
Morning all, I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities). I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly). I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl>and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest>at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat <http://microformats.org/> as a simple demonstration of what is possible. Anyway, without further ado: Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like? The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type <http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html>of the [ Semantic <http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web>as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)? Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too. Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand. XML It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers. Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/>it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData <http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries <http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching>and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning> ). OCCI Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/>whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things. The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well: - *Copyrights* (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. - *Patents* pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842>cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble>against competitors. - *Trademarks* like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011>prevent us from even referring to the Amazon APIs by name. While I wish the guys at Eucalyptus <http://open.eucalyptus.com/> and Canonical <http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop>whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287>and RFC 5023: Atom Publishing Protocol <http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code. So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies). Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing.

Couple of questions… By introducing Atom, are you proposing it to be the meta-model of OCCI? If it is the meta-model then we should define relationships at a model level as atom will not do this for us. These relationships are not detailed in the Noun/Verb/Attribute page. How does it differ by choosing the approach of SUN/Vmware/Elastichosts/GoGrid? All of which use a specific model that is rendered in various ways. Randy, Richard, Tim, Chris, any practical implications on using atom? Andy From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Sam Johnston Sent: 05 May 2009 02:34 To: occi-wg@ogf.org Subject: [occi-wg] Is OCCI the HTTP of Cloud Computing? Morning all, I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities). I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly). I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl> and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest> at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com> and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com> versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat<http://microformats.org/> as a simple demonstration of what is possible. Anyway, without further ado: Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like? The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type<http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html> of the [Semantic<http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web> as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)? Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too. Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand. XML It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers. Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/> it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData<http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries<http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching> and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning>). OCCI Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/> whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things. The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well: * Copyrights (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. * Patents pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842> cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble> against competitors. * Trademarks like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011> prevent us from even referring to the Amazon APIs by name. While I wish the guys at Eucalyptus<http://open.eucalyptus.com/> and Canonical<http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop> whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287> and RFC 5023: Atom Publishing Protocol<http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code. So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies). Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing. ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
Andy, Thanks for the feedback. I'm on the road so I'll be concise for a change. On Tue, May 5, 2009 at 12:16 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com
wrote:
By introducing Atom, are you proposing it to be the meta-model of OCCI? If it is the meta-model then we should define relationships at a model level as atom will not do this for us. These relationships are not detailed in the Noun/Verb/Attribute page.
That's the idea - it gives us just enough structure (but no more) and while the proposal is not without contention<http://samj.net/2009/05/is-occi-http-of-cloud-computing.html#comments>, I am unconvinced that text and/or json alone will meet the (at times esoteric) needs of the enterprise customers I represent. Agreed, we will need to have a simple model showing compute resources having zero or more network and storage resources as well as network (and storage?) interconnects. It may be interesting/necessary to stray into the territory of these resources having parents too but we're already starting to stray onto SNIA turf there (better to have them extend OCCI too if we can).
How does it differ by choosing the approach of SUN/Vmware/Elastichosts/GoGrid?
VMware appear to be going for OVF over RESTful HTTP, possibly with some kind of XML wrapping. That's not a bad idea but it's somewhat overkill - I came up with it myself independently for OCCI but dropped it based on feedback from members of this group. Sun do something similar<http://kenai.com/projects/suncloudapis/pages/HelloCloud>with JSON (likely becuase of the Q-Layer vintage where the API was consumed by a web interface) but that fails the "sysadmin friendly" test and as soon as you need to invoke a library it doesn't matter whether it's JSON or ASN.1 on the wire :) GoGrid have a query API<http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call>that will talk JSON, XML and CSV and ElasticHosts ran with <http://www.elastichosts.com/products/api> space separated attribute/value pairs. They also give advice<http://www.elastichosts.com/blog/2009/01/01/designing-a-great-http-api/>which I've taken heed of in this proposal: Choice of syntax: Different users will find different syntax most natural. At the unix shell, space-deliminated text rules. From Javascript, you’ll want JSON. From Java, you may want XML. Some tools parse x-www-form-encoded data nicely. A great HTTP APIMIME content types. (OK, we admit that we’ve only released text/plain ourselves so far, but the rest are coming very soon!). All of which use a specific model that is rendered in various ways. Randy,
Richard, Tim, Chris, any practical implications on using atom?
I'm very interested to hear the feedback from these guys too (hence this post) and while moving to something like JSON <http://www.json.org/>/YAML<http://www.yaml.org> /YML <http://fdik.org/yml/> may make sense technically it would be at the cost of many years of maturity and a substantial base of (almost) OCCI-ready clients <http://code.google.com/apis/gdata/clientlibs.html> courtesy Google (not to mention the various feed readers/libraries etc). So long as we're going to support multiple formats anyway I figure we may as well base it on XML given the ease at which it can be downconverted to text/json/etc. and upconverted to [X]HTML, PDF, etc. - making sample XSLT's available to implementors will make this task a walk in the park (as evidenced by the reference implementation). Anyway have a meeting on the other side of town in 8 minutes... Sam
*From:* occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] *On Behalf Of *Sam Johnston *Sent:* 05 May 2009 02:34 *To:* occi-wg@ogf.org *Subject:* [occi-wg] Is OCCI the HTTP of Cloud Computing?
Morning all,
I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities).
I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly).
I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl>and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest>at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat <http://microformats.org/> as a simple demonstration of what is possible.
Anyway, without further ado:
Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html
The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like?
The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type <http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html>of the [ Semantic <http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web>as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)?
Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too.
Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand.
XML
It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers.
Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/>it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData <http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries <http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching>and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning> ).
OCCI
Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/>whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things.
The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well:
- *Copyrights* (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. - *Patents* pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842>cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble>against competitors. - *Trademarks* like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011>prevent us from even referring to the Amazon APIs by name.
While I wish the guys at Eucalyptus <http://open.eucalyptus.com/> and Canonical <http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop>whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287>and RFC 5023: Atom Publishing Protocol <http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code.
So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies).
Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing.
------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
Ah ok now that makes things a little clearer. I saw Benjamin’s (@benjaminblack) concerns regarding the usage of atom but if we are using it as the metamodel then it only adds more rigor to our effort. On the other hand we are dependent on the atom model. If adopting atom we need to take our nouns apply the atom metamodel to them. I’ve a simple little metamodel that I was playing about which could provide a means for our atom-based noun model (attached). It is most basic but follows some aspects such as OVF and Sun API. Perhaps that could serve as a starting point? If we settle on the model (how nouns are related) then I don’t see any real issue in the presentation of that model via various renderings (here we could use content negotiation) like text, json and xml (although a rendering of atom-based json might look ugly – perhaps JSONSchema [1] might be of use here? As for text – no idea, yet ☺). Andy [1] http://www.json.com/json-schema-proposal From: Sam Johnston [mailto:samj@samj.net] Sent: 05 May 2009 12:23 To: Edmonds, AndrewX Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing? Andy, Thanks for the feedback. I'm on the road so I'll be concise for a change. On Tue, May 5, 2009 at 12:16 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com<mailto:andrewx.edmonds@intel.com>> wrote: By introducing Atom, are you proposing it to be the meta-model of OCCI? If it is the meta-model then we should define relationships at a model level as atom will not do this for us. These relationships are not detailed in the Noun/Verb/Attribute page. That's the idea - it gives us just enough structure (but no more) and while the proposal is not without contention<http://samj.net/2009/05/is-occi-http-of-cloud-computing.html#comments>, I am unconvinced that text and/or json alone will meet the (at times esoteric) needs of the enterprise customers I represent. Agreed, we will need to have a simple model showing compute resources having zero or more network and storage resources as well as network (and storage?) interconnects. It may be interesting/necessary to stray into the territory of these resources having parents too but we're already starting to stray onto SNIA turf there (better to have them extend OCCI too if we can). How does it differ by choosing the approach of SUN/Vmware/Elastichosts/GoGrid? VMware appear to be going for OVF over RESTful HTTP, possibly with some kind of XML wrapping. That's not a bad idea but it's somewhat overkill - I came up with it myself independently for OCCI but dropped it based on feedback from members of this group. Sun do something similar<http://kenai.com/projects/suncloudapis/pages/HelloCloud> with JSON (likely becuase of the Q-Layer vintage where the API was consumed by a web interface) but that fails the "sysadmin friendly" test and as soon as you need to invoke a library it doesn't matter whether it's JSON or ASN.1 on the wire :) GoGrid have a query API<http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call> that will talk JSON, XML and CSV and ElasticHosts ran with<http://www.elastichosts.com/products/api> space separated attribute/value pairs. They also give advice<http://www.elastichosts.com/blog/2009/01/01/designing-a-great-http-api/> which I've taken heed of in this proposal: Choice of syntax: Different users will find different syntax most natural. At the unix shell, space-deliminated text rules. From Javascript, you’ll want JSON. From Java, you may want XML. Some tools parse x-www-form-encoded data nicely. A great HTTP APIMIME content types. (OK, we admit that we’ve only released text/plain ourselves so far, but the rest are coming very soon!). All of which use a specific model that is rendered in various ways. Randy, Richard, Tim, Chris, any practical implications on using atom? I'm very interested to hear the feedback from these guys too (hence this post) and while moving to something like JSON<http://www.json.org/>/YAML<http://www.yaml.org>/YML<http://fdik.org/yml/> may make sense technically it would be at the cost of many years of maturity and a substantial base of (almost) OCCI-ready clients<http://code.google.com/apis/gdata/clientlibs.html> courtesy Google (not to mention the various feed readers/libraries etc). So long as we're going to support multiple formats anyway I figure we may as well base it on XML given the ease at which it can be downconverted to text/json/etc. and upconverted to [X]HTML, PDF, etc. - making sample XSLT's available to implementors will make this task a walk in the park (as evidenced by the reference implementation). Anyway have a meeting on the other side of town in 8 minutes... Sam From: occi-wg-bounces@ogf.org<mailto:occi-wg-bounces@ogf.org> [mailto:occi-wg-bounces@ogf.org<mailto:occi-wg-bounces@ogf.org>] On Behalf Of Sam Johnston Sent: 05 May 2009 02:34 To: occi-wg@ogf.org<mailto:occi-wg@ogf.org> Subject: [occi-wg] Is OCCI the HTTP of Cloud Computing? Morning all, I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities). I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly). I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl> and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest> at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com> and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com> versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat<http://microformats.org/> as a simple demonstration of what is possible. Anyway, without further ado: Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like? The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type<http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html> of the [Semantic<http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web> as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)? Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too. Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand. XML It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers. Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/> it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData<http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries<http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching> and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning>). OCCI Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/> whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things. The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well: * Copyrights (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. * Patents pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842> cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble> against competitors. * Trademarks like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011> prevent us from even referring to the Amazon APIs by name. While I wish the guys at Eucalyptus<http://open.eucalyptus.com/> and Canonical<http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop> whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287> and RFC 5023: Atom Publishing Protocol<http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code. So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies). Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing. ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
{kind=link}
On Tue, May 5, 2009 at 9:58 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com>wrote:
Ah ok now that makes things a little clearer.
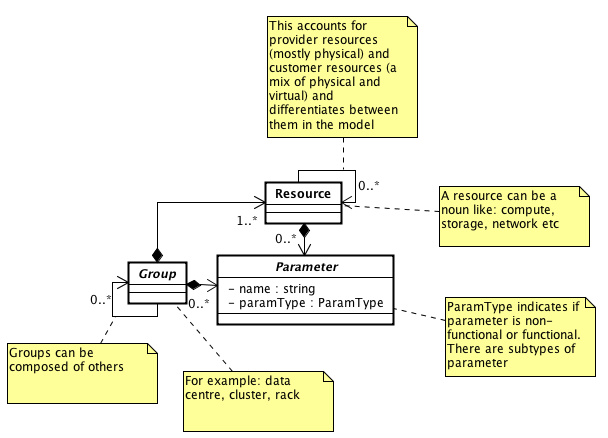
I saw Benjamin’s (@benjaminblack) concerns regarding the usage of atom but if we are using it as the metamodel then it only adds more rigor to our effort. On the other hand we are dependent on the atom model. If adopting atom we need to take our nouns apply the atom metamodel to them. I’ve a simple little metamodel that I was playing about which could provide a means for our atom-based noun model (attached). It is most basic but follows some aspects such as OVF and Sun API. Perhaps that could serve as a starting point?
Thanks Andy, this looks like a great start. Atom is exactly that - adding just enough structure in the form of links and metadata and the vast majority of it is stuff we were already trying to reinvent from scratch before.
If we settle on the model (how nouns are related) then I don’t see any real issue in the presentation of that model via various renderings (here we could use content negotiation) like text, json and xml (although a rendering of atom-based json might look ugly – perhaps JSONSchema [1] might be of use here? As for text – no idea, yet J).
Content negotiation is part of the spec as well but something I did consider was brain dead/secure devices that run e.g. desktop images might want to have a *very* simple implementation consisting of just static "OCCI" files sitting on an embedded web server. To allow for that, in addition to Internet media (mime) types we may want to specify file extensions too (e.g. .xml, .txt, .html, .json). This is a nice to have for sysadmins and anyone interacting with the API manually (e.g. point your browser at http://example.com/d1a12188-59ed-44a2-bfdd-cdcd44ff5c3d.json) as otherwise it's virtually impossible to access the different renderings. I'm pretty sure some of the existing APIs do this already. Sam
Andy
[1] http://www.json.com/json-schema-proposal
*From:* Sam Johnston [mailto:samj@samj.net] *Sent:* 05 May 2009 12:23 *To:* Edmonds, AndrewX *Cc:* occi-wg@ogf.org *Subject:* Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
Andy,
Thanks for the feedback. I'm on the road so I'll be concise for a change.
On Tue, May 5, 2009 at 12:16 PM, Edmonds, AndrewX < andrewx.edmonds@intel.com> wrote:
By introducing Atom, are you proposing it to be the meta-model of OCCI? If it is the meta-model then we should define relationships at a model level as atom will not do this for us. These relationships are not detailed in the Noun/Verb/Attribute page.
That's the idea - it gives us just enough structure (but no more) and while the proposal is not without contention<http://samj.net/2009/05/is-occi-http-of-cloud-computing.html#comments>, I am unconvinced that text and/or json alone will meet the (at times esoteric) needs of the enterprise customers I represent.
Agreed, we will need to have a simple model showing compute resources having zero or more network and storage resources as well as network (and storage?) interconnects. It may be interesting/necessary to stray into the territory of these resources having parents too but we're already starting to stray onto SNIA turf there (better to have them extend OCCI too if we can).
How does it differ by choosing the approach of SUN/Vmware/Elastichosts/GoGrid?
VMware appear to be going for OVF over RESTful HTTP, possibly with some kind of XML wrapping. That's not a bad idea but it's somewhat overkill - I came up with it myself independently for OCCI but dropped it based on feedback from members of this group.
Sun do something similar<http://kenai.com/projects/suncloudapis/pages/HelloCloud>with JSON (likely becuase of the Q-Layer vintage where the API was consumed by a web interface) but that fails the "sysadmin friendly" test and as soon as you need to invoke a library it doesn't matter whether it's JSON or ASN.1 on the wire :)
GoGrid have a query API<http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call>that will talk JSON, XML and CSV and ElasticHosts ran with <http://www.elastichosts.com/products/api> space separated attribute/value pairs. They also give advice<http://www.elastichosts.com/blog/2009/01/01/designing-a-great-http-api/>which I've taken heed of in this proposal:
Choice of syntax: Different users will find different syntax most natural. At the unix shell, space-deliminated text rules. From Javascript, you’ll want JSON. From Java, you may want XML. Some tools parse x-www-form-encoded data nicely. A great HTTP APIMIME content types. (OK, we admit that we’ve only released text/plain ourselves so far, but the rest are coming very soon!).
All of which use a specific model that is rendered in various ways. Randy, Richard, Tim, Chris, any practical implications on using atom?
I'm very interested to hear the feedback from these guys too (hence this post) and while moving to something like JSON <http://www.json.org/>/YAML<http://www.yaml.org> /YML <http://fdik.org/yml/> may make sense technically it would be at the cost of many years of maturity and a substantial base of (almost) OCCI-ready clients <http://code.google.com/apis/gdata/clientlibs.html> courtesy Google (not to mention the various feed readers/libraries etc). So long as we're going to support multiple formats anyway I figure we may as well base it on XML given the ease at which it can be downconverted to text/json/etc. and upconverted to [X]HTML, PDF, etc. - making sample XSLT's available to implementors will make this task a walk in the park (as evidenced by the reference implementation).
Anyway have a meeting on the other side of town in 8 minutes...
Sam
*From:* occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] *On Behalf Of *Sam Johnston *Sent:* 05 May 2009 02:34 *To:* occi-wg@ogf.org *Subject:* [occi-wg] Is OCCI the HTTP of Cloud Computing?
Morning all,
I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities).
I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly).
I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl>and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest>at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat <http://microformats.org/> as a simple demonstration of what is possible.
Anyway, without further ado:
Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html
The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like?
The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type <http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html>of the [ Semantic <http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web>as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)?
Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too.
Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand.
XML
It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers.
Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/>it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData <http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries <http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching>and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning> ).
OCCI
Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/>whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things.
The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well:
- *Copyrights* (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. - *Patents* pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842>cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble>against competitors. - *Trademarks* like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011>prevent us from even referring to the Amazon APIs by name.
While I wish the guys at Eucalyptus <http://open.eucalyptus.com/> and Canonical <http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop>whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287>and RFC 5023: Atom Publishing Protocol <http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code.
So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies).
Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing.
-------------------------------------------------------------
Intel Ireland Limited (Branch)
Collinstown Industrial Park, Leixlip, County Kildare, Ireland
Registered Number: E902934
This e-mail and any attachments may contain confidential material for
the sole use of the intended recipient(s). Any review or distribution
by others is strictly prohibited. If you are not the intended
recipient, please contact the sender and delete all copies.
------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.

Morning Sam! Thanks for your latest mail, and the work that you have clearly put in to get some examples, XSLT, etc. up. Here's the ElasticHosts view:
Amazon use a simple but sprawling XML based API ... there are a raft of intellectual property issues as well:
We definitely agree with you that OCCI can produce a better API than Amazon, both in terms of IP issues and also a cleaner design. If I were Amazon and wanted to play hardball, I would (a) allow Eucalyptus, etc to copy my API for now (since it only helps me gain traction as a defacto standard), (b) remain vague about IP for now, (c) not support any other API standards while I remember the defacto standard and (d) later halt or charge fees to any competition which becomes serious. (a), (b) and (c) seem well executed to date ;-)
I am now 100% convinced that the best results are to be had with a variant of XML over HTTP ... support alternative formats including HTML, JSON and TXT via XML Stylesheets
As you're well aware, we're less in favour of XML. However support for alternative formats with automatic cross-conversion makes all the versions equivalently first-class citizens, which is good enough for us. The XSLT convertors start with XML and convert to the other formats. In practice, ElasticHosts will likely start with TXT, and convert from there to the JSON, XML, etc - it would be great to see automatic convertors in this opposite direction too, to validate that it can be done. Writing these will also impose discipline and prevent creation of unnecessarily complex datastructures, which is always a risk in XML.
You can see the basics in action thanks to my Google App Engine reference implementation at http://occitest.appspot.com/ (as well as HTML, JSON and TXT versions of same)
http://occitest.appspot.com/ http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com
I'm not going to comment on the XML, since Enterprise XML design is not our forte. I will go through the TEXT and JSON versions in some detail. Here's a sample excerpt in XML:
<entry> <id>urn:uuid:47bb7df8-587e-47fa-bd89-6f2f81c14b19</id> <title>Virtual Machine #1</title> <summary>Sample Compute Resource</summary> <updated>2009-05-04T09:52:37Z</updated> <link href="/47bb7df8-587e-47fa-bd89-6f2f81c14b19" /> <link rel="http://purl.org/occi/storage#device" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" title="Hard Drive"/> <link rel="http://purl.org/occi/network#interface" href="urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9" title="Internet Connection"/> <link rel="http://purl.org/occi/network#interface" href="urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475" title="Private Network"/> </entry>
in JSON: [I assume the '\n' and '\/' in the strings are mistakes. It'd also be good if the XSLT-converted JSON had nice indentation, like I've produced below]
{ "id":"urn:uuid:47bb7df8-587e-47fa-bd89-6f2f81c14b19", "title":"Virtual\nMachine\n#1", "summary":"Sample\nCompute\nResource", "updated":"2009-05-04T09:52:37Z", "link":[ { "href":"\/47bb7df8-587e-47fa-bd89-6f2f81c14b19" }, { "rel":"http:\/\/purl.org\/occi\/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard\nDrive" }, { "rel":"http:\/\/purl.org\/occi\/network#interface", "href":"urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9", "title":"Internet\nConnection" }, { "rel":"http:\/\/purl.org\/occi\/network#interface", "href":"urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475", "title":"Private\nNetwork" } ] }
and in TXT:
[47bb7df8-587e-47fa-bd89-6f2f81c14b19] title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19 link|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475 etag|
Going through the text version...
[47bb7df8-587e-47fa-bd89-6f2f81c14b19]
To simplify parsing even further, I'd write this as: id|47bb7df8-587e-47fa-bd89-6f2f81c14b19 and have the blank line also as the separator between objects
title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z
These look good - simple key-value pairs. Presumably we'll also add some actual parameters of the virtual machine, e.g. smp|2 cpu|2000 mem|1024 It would be good to work these into the examples, TXT, JSON and XML.
link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19
It's good that we have an end-point for editing the object directly. I'd make this a simple key-value rather than having blank fields: link|/47bb7df8-587e-47fa-bd89-6f2f81c14b19
link|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475
There are four fields here: 'link', a schema, a name and an object's UUID. However there's an important one missing - the specification of _how_ the other object is bound to the virtual machine (e.g. is the drive bound as IDE or SCSI, and to which bus? Which network is which virtual NIC?). This extra field will be needed in the XML too, e.g. as 'type': <link type="ide:0:0" rel="http://purl.org/occi/storage#device" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" title="Hard Drive"/> One this is specified, the first three fields aren't actually necessary in the TXT version, which can just be: ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df nic:0|dc88b244-145f-49e4-be7c-0880dcad42e9 nic:1|253d83dd-e417-4e1f-9958-8c0a63120475 There's no need to specify the schema, since this is uniquely determined by the link type (and in any case only relevant to the XML), no need to specify 'link', since it always is for this key, and no need to specify the name, since that's the name of the object with the given UUID.
etag|
What's this doing? Can it be deleted? Putting these together, the original:
[47bb7df8-587e-47fa-bd89-6f2f81c14b19] title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19 link|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475 etag|
Turns into: id|47bb7df8-587e-47fa-bd89-6f2f81c14b19 title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z smp|2 cpu|2000 mem|1024 link|/47bb7df8-587e-47fa-bd89-6f2f81c14b19 ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df nic:0|dc88b244-145f-49e4-be7c-0880dcad42e9 nic:1|253d83dd-e417-4e1f-9958-8c0a63120475 Which is shorter, simpler and describes the virtual server more fully (3 extra properties + the link attachment points). We can also render this same thing in JSON: { "id": "47bb7df8-587e-47fa-bd89-6f2f81c14b19", "title": "Virtual Machine #1", "summary": "Sample Compute Resource", "updated": "2009-05-04T09:52:37Z", "smp": 2, "cpu": 2000, "mem": 1024, "link": "/47bb7df8-587e-47fa-bd89-6f2f81c14b19", "ide:0:0": "4cc8cf62-69a4-4650-9e8c-7d4c516884df", "nic:0": "dc88b244-145f-49e4-be7c-0880dcad42e9", "nic:1": "253d83dd-e417-4e1f-9958-8c0a63120475" } Which again is shorter, simpler and more descriptive than the original. Sam: please can you take these changes on board: - update the XML example with the 3 extra properties, the link attachment points and probably some actuators too (like start and stop) - update the XSLT conversions to produce the improved TXT and JSON formats Thanks! Richard.

On Tue, May 5, 2009 at 2:44 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
As you're well aware, we're less in favour of XML. However support for alternative formats with automatic cross-conversion makes all the versions equivalently first-class citizens, which is good enough for us.
The XSLT convertors start with XML and convert to the other formats. In practice, ElasticHosts will likely start with TXT, and convert from there to the JSON, XML, etc - it would be great to see automatic convertors in this opposite direction too, to validate that it can be done. Writing these will also impose discipline
This is a great point - cross format converters will make it easier to spot bugs. alexis
The XSLT convertors start with XML and convert to the other formats. In practice, ElasticHosts will likely start with TXT, and convert from there to the JSON, XML, etc - it would be great to see automatic convertors in this opposite direction too, to validate that it can be done. Writing these will also impose discipline
This is a great point - cross format converters will make it easier to spot bugs.
Definitely. And they'll impose discipline in data structures too, as I said. We firmly believe that the entire core API can and should be written as simple key-value pairs in the text format (see my last post where I improved Sam's example by converting it to these). In the simpler formats (TXT, JSON), it's easier to spot when the data structures are running away, whereas in the XML it's easy to make a mistake which adds another 4 levels of data structure nesting, sometimes even without realising it! Richard.
On Tue, May 5, 2009 at 2:59 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
In the simpler formats (TXT, JSON), it's easier to spot when the data structures are running away, whereas in the XML it's easy to make a mistake which adds another 4 levels of data structure nesting, sometimes even without realising it!
Incidentally we rewrote the AMQP XML spec for verbs in JSON for various reasons. It is now much easier to use. alexis
On Tue, May 5, 2009 at 4:01 PM, Alexis Richardson < alexis.richardson@gmail.com> wrote:
On Tue, May 5, 2009 at 2:59 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
In the simpler formats (TXT, JSON), it's easier to spot when the data structures are running away, whereas in the XML it's easy to make a
mistake
which adds another 4 levels of data structure nesting, sometimes even without realising it!
Incidentally we rewrote the AMQP XML spec for verbs in JSON for various reasons. It is now much easier to use.
This sounds like useful work for me to look at - where can I find it? Sam
On Tue, May 5, 2009 at 3:59 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
The XSLT convertors start with XML and convert to the other formats. In practice, ElasticHosts will likely start with TXT, and convert from there to the JSON, XML, etc - it would be great to see automatic convertors in this opposite direction too, to validate that it can be done. Writing these will also impose discipline
This is a great point - cross format converters will make it easier to spot bugs.
Definitely.
And they'll impose discipline in data structures too, as I said. We firmly believe that the entire core API can and should be written as simple key-value pairs in the text format (see my last post where I improved Sam's example by converting it to these).
In the simpler formats (TXT, JSON), it's easier to spot when the data structures are running away, whereas in the XML it's easy to make a mistake which adds another 4 levels of data structure nesting, sometimes even without realising it!
Agreed, but bear in mind that a key motivator for choosing XML as the source format is that it's trivial to convert it into anything from plain text to json to ODF/PDF etc. Sam
Richard, Apologies for the tardy response - I have been busy organising our presence at the Cloud Computing Expos in Prague and London on 18-19 and 20-21 May respectively (hope to see some of you there). On Tue, May 5, 2009 at 3:44 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
Amazon use a simple but sprawling XML based API ... there are a raft of intellectual property issues as well:
We definitely agree with you that OCCI can produce a better API than Amazon, both in terms of IP issues and also a cleaner design. If I were Amazon and wanted to play hardball, I would (a) allow Eucalyptus, etc to copy my API for now (since it only helps me gain traction as a defacto standard), (b) remain vague about IP for now, (c) not support any other API standards while I remember the defacto standard and (d) later halt or charge fees to any competition which becomes serious.
(a), (b) and (c) seem well executed to date ;-)
Indeed, and until such time as Amazon work out what they want to do with their APIs they're essentially a no-go-zone (for us at least).
I am now 100% convinced that the best results are to be had with a variant
of XML over HTTP ... support alternative formats including HTML, JSON and TXT via XML Stylesheets
As you're well aware, we're less in favour of XML. However support for alternative formats with automatic cross-conversion makes all the versions equivalently first-class citizens, which is good enough for us.
The XSLT convertors start with XML and convert to the other formats. In practice, ElasticHosts will likely start with TXT, and convert from there to the JSON, XML, etc - it would be great to see automatic convertors in this opposite direction too, to validate that it can be done. Writing these will also impose discipline and prevent creation of unnecessarily complex datastructures, which is always a risk in XML.
Agreed, but one of the primary drivers for XML is the ease at which one can transform from it into $PREFERRED_FORMAT - the same cannot necessarily be said in reverse. That's not to say I won't have a crack at it, nor that it would necessarily be all that difficult, but there's no generic xsltjson<http://www.bramstein.com/projects/xsltjson/>(and things like BadgerFish <http://ajaxian.com/archives/badgerfish-translating-xml-to-json>) to do that mechanically for example.
You can see the basics in action thanks to my Google App Engine reference
implementation at http://occitest.appspot.com/ (as well as HTML, JSON and TXT versions of same)
I'm not going to comment on the XML, since Enterprise XML design is not our forte. I will go through the TEXT and JSON versions in some detail.
No problem - it's not that difficult to understand but I'm guessing a fairly introductory explanation would be a useful addition to the spec.
Here's a sample excerpt in XML:
<entry> <id>urn:uuid:47bb7df8-587e-47fa-bd89-6f2f81c14b19</id> <title>Virtual Machine #1</title> <summary>Sample Compute Resource</summary> <updated>2009-05-04T09:52:37Z</updated> <link href="/47bb7df8-587e-47fa-bd89-6f2f81c14b19" /> <link rel="http://purl.org/occi/storage#device" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" title="Hard Drive"/> <link rel="http://purl.org/occi/network#interface" href="urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9" title="Internet Connection"/> <link rel="http://purl.org/occi/network#interface" href="urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475" title="Private Network"/> </entry>
in JSON: [I assume the '\n' and '\/' in the strings are mistakes. It'd also be good if the XSLT-converted JSON had nice indentation, like I've produced below]
Yes, I was assuming that would go unnoticed but apparently people are paying attention... I was using TextMate to clean it up but the same could easy enough be done in the XSLT.
{ "id":"urn:uuid:47bb7df8-587e-47fa-bd89-6f2f81c14b19", "title":"Virtual\nMachine\n#1", "summary":"Sample\nCompute\nResource", "updated":"2009-05-04T09:52:37Z", "link":[ { "href":"\/47bb7df8-587e-47fa-bd89-6f2f81c14b19" }, { "rel":"http:\/\/purl.org\/occi\/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard\nDrive" }, { "rel":"http:\/\/purl.org\/occi\/network#interface", "href":"urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9", "title":"Internet\nConnection" }, { "rel":"http:\/\/purl.org\/occi\/network#interface", "href":"urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475", "title":"Private\nNetwork" } ] }
and in TXT:
[47bb7df8-587e-47fa-bd89-6f2f81c14b19] title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19 link|http://purl.org/occi/storage#device|Hard<http://purl.org/occi/storage#device%7CHard>Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet<http://purl.org/occi/network#interface%7CInternet>Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private<http://purl.org/occi/network#interface%7CPrivate>Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475 etag|
Going through the text version...
[47bb7df8-587e-47fa-bd89-6f2f81c14b19]
To simplify parsing even further, I'd write this as:
id|47bb7df8-587e-47fa-bd89-6f2f81c14b19
Right, Chris and I discussed this before and agreed that an INI format wasn't ideal - changing it is easy enough to do (even for an XSLT newbie like myself). We also spoke about putting the ID on every line ala tinydns-data format (which is nice for multithreaded/asynchronous implementations which may need to pull data from billing systems, performance monitor counters, etc)... this is trivial to parse into a hash [of hashes] and a pleasure to work with. Another thing to note is the use of the pipe (|) character as a separator since colons (:) are present in URLs... we may also be able to move to CSV which is something I believe GoGrid are already supporting. This is a detail that makes little difference though, and probably something we can agree on later.
and have the blank line also as the separator between objects
title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z
These look good - simple key-value pairs.
Presumably we'll also add some actual parameters of the virtual machine, e.g.
smp|2 cpu|2000 mem|1024
Right, and then there's just the question of whether these go into the top level namespace or e.g. "compute:cores", "compute:arch", "compute:speed", "memory:size", etc. (I'm thinking burning a few more characters is worth it, and the mechanical transformations are easier then too... avoiding confusion e.g. "cpu" means speed or cores).
It would be good to work these into the examples, TXT, JSON and XML.
link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19
It's good that we have an end-point for editing the object directly. I'd make this a simple key-value rather than having blank fields:
link|/47bb7df8-587e-47fa-bd89-6f2f81c14b19
The blank fields are not [really] intentional, but there's a good reason for their existence. "link" is a generic Atom construct (see here<http://tools.ietf.org/html/rfc4287#section-4.2.7>for details) that can point back to the object, to an alternate (e.g. PDF) representation of it, to another object (e.g. a parent, child, sibling, etc.) or pretty much whatever we want (e.g. think screenshots, snapshots, build documentation, etc. - again, where a lot of the innovation will take place). Perhaps we can move the URL to the front and only show the empty fields when there are gaps... need to get me a good XSLT book (if anyone has a PDF or even a recommendation I'd be happy to hear it).
link|http://purl.org/occi/storage#device|Hard<http://purl.org/occi/storage#device%7CHard>Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet<http://purl.org/occi/network#interface%7CInternet>Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private<http://purl.org/occi/network#interface%7CPrivate>Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475
There are four fields here: 'link', a schema, a name and an object's UUID. However there's an important one missing - the specification of _how_ the other object is bound to the virtual machine (e.g. is the drive bound as IDE or SCSI, and to which bus? Which network is which virtual NIC?).
Again "link" is a generic Atom construct that can apply to anything... usually it is used to point at the content of the object where none is embedded (remembering you can embed XML e.g. OVF or any other data including binary if need be).
This extra field will be needed in the XML too, e.g. as 'type':
<link type="ide:0:0" rel="http://purl.org/occi/storage#device" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" title="Hard Drive"/>
One this is specified, the first three fields aren't actually necessary in the TXT version, which can just be:
ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df nic:0|dc88b244-145f-49e4-be7c-0880dcad42e9 nic:1|253d83dd-e417-4e1f-9958-8c0a63120475
There's no need to specify the schema, since this is uniquely determined by the link type (and in any case only relevant to the XML), no need to specify 'link', since it always is for this key, and no need to specify the name, since that's the name of the object with the given UUID.
Yes, this makes a lot of sense, but it also means you've got logic in your transforms which is something I would *very much* like to avoid. We also start to impose on the format of device identifiers which doesn't necessarily work in large, complex and/or heterogeneous environments (you say eth0, I say en1 and others say "Local Area Connection"... and that's before you start talking about paravirtualised block devices and so on) and short of revising the spec we're at a dead end if implementors need to carry other information such as block or frame size. Human friendly "title"s are incredibly useful too by the way, and while one could use the title of the storage or network resource that doesn't always work (think shared networks and cluster storage). I admit there's probably a better way to do it and to be honest I've not had a chance to spend a lot of time on the problem (nor am I an XSLT wizard, yet).
etag|
What's this doing? Can it be deleted?
Nothing at the moment because I haven't worked out a sensible way to generate eTags <http://en.wikipedia.org/wiki/HTTP_ETag>, however this is part of the magic fairy dust that Google added to Atom to make GData and it's very important for performance/caching/proxying/gatewaying/concurrency/conflict resolution/etc. (but also usually safe to ignore for those who don't care about such things).
Putting these together, the original:
[47bb7df8-587e-47fa-bd89-6f2f81c14b19] title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19 link|http://purl.org/occi/storage#device|Hard<http://purl.org/occi/storage#device%7CHard>Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df link|http://purl.org/occi/network#interface|Internet<http://purl.org/occi/network#interface%7CInternet>Connection|urn:uuid:dc88b244-145f-49e4-be7c-0880dcad42e9 link|http://purl.org/occi/network#interface|Private<http://purl.org/occi/network#interface%7CPrivate>Network|urn:uuid:253d83dd-e417-4e1f-9958-8c0a63120475 etag|
Turns into:
id|47bb7df8-587e-47fa-bd89-6f2f81c14b19 title|Virtual Machine #1 summary|Sample Compute Resource updated|2009-05-04T09:52:37Z smp|2 cpu|2000 mem|1024 link|/47bb7df8-587e-47fa-bd89-6f2f81c14b19 ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df nic:0|dc88b244-145f-49e4-be7c-0880dcad42e9 nic:1|253d83dd-e417-4e1f-9958-8c0a63120475
Which is shorter, simpler and describes the virtual server more fully (3 extra properties + the link attachment points).
Sure this looks nicer/neater for us humans but it's less flexible and makes more work for the machines (and more importantly, programmers thereof). We need to find a balance and I'll certainly be working with you and Chris to do that.
We can also render this same thing in JSON:
{ "id": "47bb7df8-587e-47fa-bd89-6f2f81c14b19", "title": "Virtual Machine #1", "summary": "Sample Compute Resource", "updated": "2009-05-04T09:52:37Z", "smp": 2, "cpu": 2000, "mem": 1024, "link": "/47bb7df8-587e-47fa-bd89-6f2f81c14b19", "ide:0:0": "4cc8cf62-69a4-4650-9e8c-7d4c516884df", "nic:0": "dc88b244-145f-49e4-be7c-0880dcad42e9", "nic:1": "253d83dd-e417-4e1f-9958-8c0a63120475" }
Which again is shorter, simpler and more descriptive than the original.
Agreed.
Sam: please can you take these changes on board: - update the XML example with the 3 extra properties, the link attachment points and probably some actuators too (like start and stop) - update the XSLT conversions to produce the improved TXT and JSON formats
No problem. I wanted to have the actuators in place already but also wanted to make them responsive (that is, so you can actually test your clients against this and so the general public can kick the tires). Sam
Richard,
Apologies for the tardy response - I have been busy organising our presence at the Cloud Computing Expos in Prague and London on 18-19 and 20-21 May respectively (hope to see some of you there).
No worries - you have plenty to do as well, I'm sure... I agree with much of what you wrote in response. The bit which I disagree with most is on the links, and is a symptom of defining from XML first. E.g.: [Exhibit A]
link|||/47bb7df8-587e-47fa-bd89-6f2f81c14b19 [might become] link|/47bb7df8-587e-47fa-bd89-6f2f81c14b19 ... The blank fields are not [really] intentional, but there's a good reason for their existence. "link" is a generic Atom construct ... Again "link" is a generic Atom construct that can apply to anything... ...
[Exhibit B]
link|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df [might become] ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df ... Sure this looks nicer/neater for us humans but it's less flexible and makes more work for the machines (and more importantly, programmers thereof). We need to find a balance and I'll certainly be working with you and Chris to do that.
In both cases here, you are using an Atom construct to define the structure in non-XML, as well as XML, formats. That's a mistake to me - our XML, JSON and TXT formats should all share the same nouns, verbs and attributes, and should also be automatically translatable into each other, but beyond that each should be well designed in their own right - I don't want to see things which look awkward in the JSON or TXT and be told that this is because they're mirroring Atom XML constructs. I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'. Yes, this will mean a little more work for an automatic translator between the formats, but that's code which is written once at most, whereas a typical users will start using a single format and find it easier if this behaves as naturally as they would expect that particular format to do. Cheers, Richard.
On Wed, May 6, 2009 at 4:11 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
In both cases here, you are using an Atom construct to define the structure in non-XML, as well as XML, formats.
That's a mistake to me - our XML, JSON and TXT formats should all share the same nouns, verbs and attributes, and should also be automatically translatable into each other, but beyond that each should be well designed in their own right - I don't want to see things which look awkward in the JSON or TXT and be told that this is because they're mirroring Atom XML constructs.
Fair point.
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Yes, this will mean a little more work for an automatic translator between the formats, but that's code which is written once at most, whereas a typical users will start using a single format and find it easier if this behaves as naturally as they would expect that particular format to do.
Ok so it's definitely an area I need to do more work on... Sam
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats. Richard.
On Wed, May 6, 2009 at 4:21 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats.
So the human friendly title is one thing that would be lost with your proposal... and things like frame/block size (unless you're happy to say it will never happen, and I'm wary of doing that, just as I'm wary of telling people to support another specific networking or storage or security or whatever protocol to cover our shortcomings). Sam
Following up the topic of attributes on links after the discussion on our call: The original example was:
<link href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
And as I said before, we also need a device identifier at which to connect the storage, making it something like:
<link type="ide:0:0" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
which mapped to JSON as:
"link":[ { "type":"ide:0:0" "rel":"http://purl.org/occi/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" } ]
I still believe that the "link" here is a figment of conversion from the Atom XML format. To write this in something more like native JSON, I'd go with: "ide:0:0": { "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" } since the device identifier is unique for the VM, and clearly specifies this as a place where storage is being attached. In text format, I'd flatten this data structure as: ide:0:0|href|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive or even just: ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive Rather than the original: link|ide:0:0|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df This is rather cleaner in terms of not having to know what all the possible attributes might be, and where they appear in the |-deliminated list. Cheers, Richard.
Hi guys, Sorry I missed the call. Had to be on the AMQP weekly call... I've just got an update from Sam by phone. It sounds like we continue to make progress! We had a chat about the formats thing and realised that a good position might be to disallow any XML use that cannot easily be expressed in JSON. This would allow JSON to be used - good news for "being very simple and clear" and good news for JSON scenarios (eg browser) and many sections of the dev community who like JSON. At the same time it would allow environments with poor support for JSON, such as .NET, to put angle brackets around things as needed ;-) Any thoughts on this? alexis On Wed, May 6, 2009 at 5:32 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
Following up the topic of attributes on links after the discussion on our call:
The original example was:
<link href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
And as I said before, we also need a device identifier at which to connect the storage, making it something like:
<link type="ide:0:0" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
which mapped to JSON as:
"link":[ { "type":"ide:0:0" "rel":"http://purl.org/occi/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" } ]
I still believe that the "link" here is a figment of conversion from the Atom XML format. To write this in something more like native JSON, I'd go with:
"ide:0:0": { "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" }
since the device identifier is unique for the VM, and clearly specifies this as a place where storage is being attached.
In text format, I'd flatten this data structure as:
ide:0:0|href|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
or even just:
ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
Rather than the original:
link|ide:0:0|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df
This is rather cleaner in terms of not having to know what all the possible attributes might be, and where they appear in the |-deliminated list.
Cheers,
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
We had a chat about the formats thing and realised that a good position might be to disallow any XML use that cannot easily be expressed in JSON.
Yes, I agree strongly with that.
This would allow JSON to be used - good news for "being very simple and clear"
Yes, and we'll be fighting for the "simple and clear" JSON to have the minimum depth of nested data structures wherever it seems to be getting too complex. I also think that simple and clear JSON is also easy to convert to TXT, so this will give us all three formats easily, and with automatic conversions, which is where we should be. Cheers, Richard.
Good. +1 On Wed, May 6, 2009 at 5:46 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
We had a chat about the formats thing and realised that a good position might be to disallow any XML use that cannot easily be expressed in JSON.
Yes, I agree strongly with that.
This would allow JSON to be used - good news for "being very simple and clear"
Yes, and we'll be fighting for the "simple and clear" JSON to have the minimum depth of nested data structures wherever it seems to be getting too complex.
I also think that simple and clear JSON is also easy to convert to TXT, so this will give us all three formats easily, and with automatic conversions, which is where we should be.
Cheers,
Richard.
+1 FWIW everything so far is flat... and I see no reason to change that. Sam On 5/6/09, Alexis Richardson <alexis.richardson@gmail.com> wrote:
Good.
+1
On Wed, May 6, 2009 at 5:46 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
We had a chat about the formats thing and realised that a good position might be to disallow any XML use that cannot easily be expressed in JSON.
Yes, I agree strongly with that.
This would allow JSON to be used - good news for "being very simple and clear"
Yes, and we'll be fighting for the "simple and clear" JSON to have the minimum depth of nested data structures wherever it seems to be getting too complex.
I also think that simple and clear JSON is also easy to convert to TXT, so this will give us all three formats easily, and with automatic conversions, which is where we should be.
Cheers,
Richard.

Hi all,
The original example was:
<link href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
And as I said before, we also need a device identifier at which to connect the storage, making it something like:
<link type="ide:0:0" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df " rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
Shouldn't these href's be HTTP URIs so I know where to go to find out some more about the storage device (in this case) ? And then, visiting the home of the storage device, I get some more (typed) links I can follow to other other things the storage is related to ... i.e. navigating the graph. (?) Roger
which mapped to JSON as:
"link":[ { "type":"ide:0:0" "rel":"http://purl.org/occi/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" } ]
I still believe that the "link" here is a figment of conversion from the Atom XML format. To write this in something more like native JSON, I'd go with:
"ide:0:0": { "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" }
since the device identifier is unique for the VM, and clearly specifies this as a place where storage is being attached.
In text format, I'd flatten this data structure as:
ide:0:0|href|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
or even just:
ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
Rather than the original:
link|ide:0:0|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df
This is rather cleaner in terms of not having to know what all the possible attributes might be, and where they appear in the |-deliminated list.
Cheers,
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com> Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534 ______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.
Sorry about the double vision before... went trough a tunnel on the train so it was sent twice. Comments inline... On 5/7/09, Roger Menday <roger.menday@uk.fujitsu.com> wrote:
Hi all,
The original example was:
<link href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
And as I said before, we also need a device identifier at which to connect the storage, making it something like:
<link type="ide:0:0" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df " rel="http://purl.org/occi/storage#device" title="Hard Drive"/>
Shouldn't these href's be HTTP URIs so I know where to go to find out some more about the storage device (in this case) ? And then, visiting the home of the storage device, I get some more (typed) links I can follow to other other things the storage is related to ... i.e. navigating the graph.
Good question and good to see people payong close attentipn. We know we can find the resources at the root of the entry point so I'm more inclined to use the href as an internal pointer than confuse things when there are multiple servers potentially talking about the same resources. we can use 3xx redirects as a kind of resolution system if need be too. Sam on iPhone
(?)
Roger
which mapped to JSON as:
"link":[ { "type":"ide:0:0" "rel":"http://purl.org/occi/storage#device", "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" } ]
I still believe that the "link" here is a figment of conversion from the Atom XML format. To write this in something more like native JSON, I'd go with:
"ide:0:0": { "href":"urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df", "title":"Hard Drive" }
since the device identifier is unique for the VM, and clearly specifies this as a place where storage is being attached.
In text format, I'd flatten this data structure as:
ide:0:0|href|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
or even just:
ide:0:0|4cc8cf62-69a4-4650-9e8c-7d4c516884df ide:0:0|title|Hard Drive
Rather than the original:
link|ide:0:0|http://purl.org/occi/storage#device|Hard Drive|urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df
This is rather cleaner in terms of not having to know what all the possible attributes might be, and where they appear in the |-deliminated list.
Cheers,
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.

On Thu, May 7, 2009 at 8:52 AM, Sam Johnston <samj@samj.net> wrote:
Good question and good to see people payong close attentipn. We know we can find the resources at the root of the entry point so I'm more inclined to use the href as an internal pointer than confuse things when there are multiple servers potentially talking about the same resources. we can use 3xx redirects as a kind of resolution system if need be too.
Sam on iPhone
I wish I could assume you were joking here. Of course they should be HTTP URIs! The confusion in the multi-provider case would come _because_ we did not specify a single entry point. The logic of exposing some internal reference and then using redirects to paper over by translating to an external reference eludes me. Ben
On 5/7/09, Benjamin Black <b@b3k.us> wrote:
On Thu, May 7, 2009 at 8:52 AM, Sam Johnston <samj@samj.net> wrote:
Good question and good to see people payong close attentipn. We know we can find the resources at the root of the entry point so I'm more inclined to use the href as an internal pointer than confuse things when there are multiple servers potentially talking about the same resources. we can use 3xx redirects as a kind of resolution system if need be too.
Sam on iPhone
I wish I could assume you were joking here. Of course they should be HTTP URIs! The confusion in the multi-provider case would come _because_ we did not specify a single entry point. The logic of exposing some internal reference and then using redirects to paper over by translating to an external reference eludes me.
Actually it makes a lot of sense. The IDs are UUID based URNs and if we have a feed we want to be able to link resources together without having to futz with URLs. The entry point will either have a resource it gave you or know where to find it anyway so resolution is a non-problem. Say we design a system where individual workstations/servers/clusters/etc each implement OCCI and have a common network resource then we definitely don't want to get different pointers from each of them. Same applies for resources that move (e.g. Live migrations), which would likely be the primary use case dr said redirects. Sam
Using HTTP URIs and making things globally unique are orthogonal. You are, again, assuming a specific implementation rather than describing the desired behavior. You _could_ produce a system using HTTP URIs that were not consistent/unique/etc., just as you could produce a system based on UUIDs that changed as the infrastructure changed. This is allegedly a RESTful API, please use the techniques of a good RESTful API, like embedding HTTP URIs, and describe the construction and semantics of the pieces as needed. Now, will someone please explain why, exactly, we are not basing this work on the Sun API? I've asked several times now and have either been ignored or gotten hand waving. Ben On Thu, May 7, 2009 at 2:53 PM, Sam Johnston <samj@samj.net> wrote:
On 5/7/09, Benjamin Black <b@b3k.us> wrote:
On Thu, May 7, 2009 at 8:52 AM, Sam Johnston <samj@samj.net> wrote:
Good question and good to see people payong close attentipn. We know we can find the resources at the root of the entry point so I'm more inclined to use the href as an internal pointer than confuse things when there are multiple servers potentially talking about the same resources. we can use 3xx redirects as a kind of resolution system if need be too.
Sam on iPhone
I wish I could assume you were joking here. Of course they should be HTTP URIs! The confusion in the multi-provider case would come _because_ we did not specify a single entry point. The logic of exposing some internal reference and then using redirects to paper over by translating to an external reference eludes me.
Actually it makes a lot of sense. The IDs are UUID based URNs and if we have a feed we want to be able to link resources together without having to futz with URLs. The entry point will either have a resource it gave you or know where to find it anyway so resolution is a non-problem.
Say we design a system where individual workstations/servers/clusters/etc each implement OCCI and have a common network resource then we definitely don't want to get different pointers from each of them. Same applies for resources that move (e.g. Live migrations), which would likely be the primary use case dr said redirects.
Sam
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
Using HTTP URIs and making things globally unique are orthogonal. You are, again, assuming a specific implementation rather than describing the desired behavior. You _could_ produce a system using HTTP URIs that were not consistent/unique/etc., just as you could produce a system based on UUIDs that changed as the infrastructure changed. This is allegedly a RESTful API, please use the techniques of a good RESTful API, like embedding HTTP URIs, and describe the construction and semantics of the pieces as needed.
We were talking before about all URLs appearing in the protocol, which does make a lot of sense. UUIDs are universally unique already are resolveable if not retrievable from the entry point that served them, and don't break when moved or shared. There are pros and cons of both approaches bit I think we need to understand the full implications before we decide one way or the other.
Now, will someone please explain why, exactly, we are not basing this work on the Sun API? I've asked several times now and have either been ignored or gotten hand waving.
There have (unsurprisingly) been public and private calls to rubber stamp various APIs but each have their benefits and drawbacks and we're trying to pick out the best parts. Single entry points, discovery, controllers and some of the structure came from Sun^W Oracle Cloud APIs already... the main thing that hasn't (yet) come across is JSON. Sam Sam
On Thu, May 7, 2009 at 2:53 PM, Sam Johnston <samj@samj.net> wrote:
On 5/7/09, Benjamin Black <b@b3k.us> wrote:
On Thu, May 7, 2009 at 8:52 AM, Sam Johnston <samj@samj.net> wrote:
Good question and good to see people payong close attentipn. We know we can find the resources at the root of the entry point so I'm more inclined to use the href as an internal pointer than confuse things when there are multiple servers potentially talking about the same resources. we can use 3xx redirects as a kind of resolution system if need be too.
Sam on iPhone
I wish I could assume you were joking here. Of course they should be HTTP URIs! The confusion in the multi-provider case would come _because_ we did not specify a single entry point. The logic of exposing some internal reference and then using redirects to paper over by translating to an external reference eludes me.
Actually it makes a lot of sense. The IDs are UUID based URNs and if we have a feed we want to be able to link resources together without having to futz with URLs. The entry point will either have a resource it gave you or know where to find it anyway so resolution is a non-problem.
Say we design a system where individual workstations/servers/clusters/etc each implement OCCI and have a common network resource then we definitely don't want to get different pointers from each of them. Same applies for resources that move (e.g. Live migrations), which would likely be the primary use case dr said redirects.
Sam

On May 7, 2009, at 3:45 PM, Sam Johnston wrote:
We were talking before about all URLs appearing in the protocol, which does make a lot of sense. UUIDs are universally unique already are resolveable if not retrievable from the entry point that served them, and don't break when moved or shared. There are pros and cons of both approaches bit I think we need to understand the full implications before we decide one way or the other.
[Trying not to get hauled into the thick of OCCI design...] Actually, if you have a protocol and there's a place where you're going to identify things with URIs (which is a good thing), the best practice is not to constrain the URI scheme. Just say it's a URI. There are people who are going to want to use URNs or "tag:" URIs or whatever, for reasons that seem good to them. I almost always disagree with those people and think that in general HTTP URIs are the way to go for almost everything, but if the usability of the protocol depends on the choice of URI scheme, that's usually a symptom of a problem. -Tim
On 5/8/09, Tim Bray <Tim.Bray@sun.com> wrote:
On May 7, 2009, at 3:45 PM, Sam Johnston wrote:
We were talking before about all URLs appearing in the protocol, which does make a lot of sense. UUIDs are universally unique already are resolveable if not retrievable from the entry point that served them, and don't break when moved or shared. There are pros and cons of both approaches bit I think we need to understand the full implications before we decide one way or the other.
[Trying not to get hauled into the thick of OCCI design...]
Actually, if you have a protocol and there's a place where you're going to identify things with URIs (which is a good thing), the best practice is not to constrain the URI scheme. Just say it's a URI. There are people who are going to want to use URNs or "tag:" URIs or whatever, for reasons that seem good to them. I almost always disagree with those people and think that in general HTTP URIs are the way to go for almost everything, but if the usability of the protocol depends on the choice of URI scheme, that's usually a symptom of a problem. -Tim
This is a good point... I wonder what the implications are for interoperability - UUID based URNs do make a hell of a lot of sense for this environment. Oh and before I forget, so I wanted to release OCCI under CC with a view to pulling directly from Sun, Google, etc. but it was shaping up to be a battle with the OGF board. May revisit the question with them later. CC licenses exclude trademarks and patents so in addition to copyright there's trademark and patent protecion for us to think about (Sun's TM is less of an issue but not sure there was a patent license/pledge for it). That said it's amazon who appear to be the resident experts on IP problems. Sam on iPhone
On Thu, May 7, 2009 at 3:45 PM, Sam Johnston <samj@samj.net> wrote:
We were talking before about all URLs appearing in the protocol, which does make a lot of sense. UUIDs are universally unique already are resolveable if not retrievable from the entry point that served them, and don't break when moved or shared. There are pros and cons of both approaches bit I think we need to understand the full implications before we decide one way or the other.
Can you point me to the requirements you've written up for this? There have (unsurprisingly) been public and private calls to rubber
stamp various APIs but each have their benefits and drawbacks and we're trying to pick out the best parts. Single entry points, discovery, controllers and some of the structure came from Sun^W Oracle Cloud APIs already... the main thing that hasn't (yet) come across is JSON.
Please refrain from putting words in my mouth. I am not asking that work be rubber stamped, I am asking that work be adopted as a basis for further work, rather than recreating large portions of it. Once again, the question goes unanswered. Best of luck. Ben
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
On Thu, May 7, 2009 at 3:45 PM, Sam Johnston <samj@samj.net> wrote:
We were talking before about all URLs appearing in the protocol, which does make a lot of sense. UUIDs are universally unique already are resolveable if not retrievable from the entry point that served them, and don't break when moved or shared. There are pros and cons of both approaches bit I think we need to understand the full implications before we decide one way or the other.
Can you point me to the requirements you've written up for this?
The requirement to link compute, storage and network resources together is obvious is it not? Our requirements for migrating and shared resources are obvious too but could probably afford to be committe to digital ink if they're not already in the wiki.
There have (unsurprisingly) been public and private calls to rubber
stamp various APIs but each have their benefits and drawbacks and we're trying to pick out the best parts. Single entry points, discovery, controllers and some of the structure came from Sun^W Oracle Cloud APIs already... the main thing that hasn't (yet) come across is JSON.
Please refrain from putting words in my mouth. I am not asking that work be rubber stamped, I am asking that work be adopted as a basis for further work, rather than recreating large portions of it. Once again, the question goes unanswered.
Ok so the attributes will be reviewed against our registry before long... already things like "operating system" will likely be added. The virtual datacenter structure for both Sun and VMware is too rigid for my liking and I'm hoping categories and tags can cover this requirement adequately and flexibly. Aside from that we've already taken a good deal of inspiration from this source and tim's excellent blog post on the subject. Was there something else you wanted us to take on board? Sam on iPhone
Ben, Sam, On Fri, May 8, 2009 at 12:20 AM, Sam Johnston <samj@samj.net> wrote:
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
On Thu, May 7, 2009 at 3:45 PM, Sam Johnston <samj@samj.net> wrote:
We were talking before about all URLs appearing in the protocol, ...
Can you point me to the requirements you've written up for this?
The requirement to link compute, storage and network resources together is obvious is it not? Our requirements for migrating and shared resources are obvious too but could probably afford to be committe to digital ink if they're not already in the wiki.
It's not obvious to me :-) It would be very good if you could put anything like this in a suitable page of the wiki.
There have (unsurprisingly) been public and private calls to rubber
stamp various APIs but each have their benefits and drawbacks and we're trying to pick out the best parts. Single entry points, discovery, controllers and some of the structure came from Sun^W Oracle Cloud APIs already... the main thing that hasn't (yet) come across is JSON.
Please refrain from putting words in my mouth. I am not asking that work be rubber stamped, I am asking that work be adopted as a basis for further work, rather than recreating large portions of it. Once again, the question goes unanswered.
Ben, Let me have a go at this one. When we started this work we were excited by the similarity of the frameworks people had evolved for their cloud APIs. See: http://spreadsheets.google.com/ccc?key=pGccO5mv6yH8Y4wV1ZAJrbQ We were all certainly very impressed by the Sun API work. But I personally would prefer to hear the Sun design decisions advocated by someone who understands them in full, which is why I am really pleased to see Tim B on here. We need these voices and they don't all arrive at once. Leaving aside any licensing questions, which I am sure are easily solved, the Sun API would IMO be a great "basis" for further work in the sense that I think you mean. But I think that for this process to work then other cloud APIs must also be a basis. Here I am especially thinking of GoGrid and ElasticHosts from the service provider side, as well as work from the OGF community as represented by for example OpenNebula. I name these because they are all willing to engage in a dialogue about their APIs in public. I'd be happy with something that was: a) common b) open c) consistent with the aims of those providers And I would be elated if we also could say: d) pleasing to a community of end users I think it is also important to hear from people who are not providing cloud technology and I like it that Sam has put work into rallying some of these voices and backing them up with drafts on the wiki. I'm not sure if you are currently in the user or provider group, but in either case please keep contributing. Do you think it is possible to talk about a common API that has as its basis the four sources of work I described above, and satisifies a community of users that is potentially larger than, say, the current users of any one API? I think it is. We made a good start in terms of consensus on the nouns and verbs at least. I also think Sam has some good ideas that are worth exploring - for example the role of feeds, and the role played by Google in the cloudscape. I'd like hear more about both of these lines of thought. But preferably not in such a way that all the issues become entangled into one. With regard to the formats issue: we all currently disagree. That is ok. We do need to hammer out a proper requirements list. It may be that we have a requirement that pushes us outside the JSON envelope so to speak. E.g.: we have talked about playing nicely with OVF and SNIA and this is certainly part of the spirit of the OCCI charter. So we need to work out what that all means and how it may apply in practice. I'd like to hear as much as possible about the requirements from Sam and from others eg Mark M. I do think that a JSON advocate could very helpfully put some info on the wiki.
Ok so the attributes will be reviewed against our registry before long... already things like "operating system" will likely be added. The virtual datacenter structure for both Sun and VMware is too rigid for my liking and I'm hoping categories and tags can cover this requirement adequately and flexibly. Aside from that we've already taken a good deal of inspiration from this source and tim's excellent blog post on the subject. Was there something else you wanted us to take on board?
Sam, thanks for this. If you have a moment please could you set out some requirements in a priority list, so that we can consider them in isolation? Happy to wait until after you are back from the weekend... alexis
I've a feeling that by choosing atom as our meta-model (analogous to base classes) that we may end up limiting the number of format that we can expose via the OCCI through this dependency. It is this choice that perhaps is the reason for the unclear path to a clean and efficient means of rendering, the OCCI model instance passed back through the OCCI, as text or JSON. To be honest it is kinda scary talk when conversions, translations etc of a schema are being talked of at this early stage, imho. Couldn't we just define a schema particular to our use cases and then see along with our requirements (e.g. easy rendering of models as text) if atom fits the bill? That schema could then be rendered as atom via transformation if required. Andy -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 06 May 2009 15:22 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats. Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.

+1 Quoting [Edmonds, AndrewX] (May 06 2009):
I've a feeling that by choosing atom as our meta-model (analogous to base classes) that we may end up limiting the number of format that we can expose via the OCCI through this dependency. It is this choice that perhaps is the reason for the unclear path to a clean and efficient means of rendering, the OCCI model instance passed back through the OCCI, as text or JSON.
To be honest it is kinda scary talk when conversions, translations etc of a schema are being talked of at this early stage, imho.
Couldn't we just define a schema particular to our use cases and then see along with our requirements (e.g. easy rendering of models as text) if atom fits the bill? That schema could then be rendered as atom via transformation if required.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 06 May 2009 15:22 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats.
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
+1 Personally I favour JSON initially, which we (RabbitMQ) have had no problem with in an enterprise context whatsoever. On Wed, May 6, 2009 at 3:37 PM, Andre Merzky <andre@merzky.net> wrote:
+1
Quoting [Edmonds, AndrewX] (May 06 2009):
I've a feeling that by choosing atom as our meta-model (analogous to base classes) that we may end up limiting the number of format that we can expose via the OCCI through this dependency. It is this choice that perhaps is the reason for the unclear path to a clean and efficient means of rendering, the OCCI model instance passed back through the OCCI, as text or JSON.
To be honest it is kinda scary talk when conversions, translations etc of a schema are being talked of at this early stage, imho.
Couldn't we just define a schema particular to our use cases and then see along with our requirements (e.g. easy rendering of models as text) if atom fits the bill? That schema could then be rendered as atom via transformation if required.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 06 May 2009 15:22 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats.
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
I should of added that whatever the outcome of the schema discussions are that an early prototype implementation such as what Sam has provided is hugely beneficial and useful - especially with OGF26 on the horizons. -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Edmonds, AndrewX Sent: 06 May 2009 15:32 To: Richard Davies; Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing? I've a feeling that by choosing atom as our meta-model (analogous to base classes) that we may end up limiting the number of format that we can expose via the OCCI through this dependency. It is this choice that perhaps is the reason for the unclear path to a clean and efficient means of rendering, the OCCI model instance passed back through the OCCI, as text or JSON. To be honest it is kinda scary talk when conversions, translations etc of a schema are being talked of at this early stage, imho. Couldn't we just define a schema particular to our use cases and then see along with our requirements (e.g. easy rendering of models as text) if atom fits the bill? That schema could then be rendered as atom via transformation if required. Andy -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 06 May 2009 15:22 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats. Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
I'd like to see something which can be implemented by (say) both Chris and Sam easily. On Wed, May 6, 2009 at 3:40 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I should of added that whatever the outcome of the schema discussions are that an early prototype implementation such as what Sam has provided is hugely beneficial and useful - especially with OGF26 on the horizons.
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Edmonds, AndrewX Sent: 06 May 2009 15:32 To: Richard Davies; Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I've a feeling that by choosing atom as our meta-model (analogous to base classes) that we may end up limiting the number of format that we can expose via the OCCI through this dependency. It is this choice that perhaps is the reason for the unclear path to a clean and efficient means of rendering, the OCCI model instance passed back through the OCCI, as text or JSON. To be honest it is kinda scary talk when conversions, translations etc of a schema are being talked of at this early stage, imho. Couldn't we just define a schema particular to our use cases and then see along with our requirements (e.g. easy rendering of models as text) if atom fits the bill? That schema could then be rendered as atom via transformation if required.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 06 May 2009 15:22 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing?
I don't believe this will make JSON or TXT either less flexible or more work for machines - to the contrary, I believe it's easier to parse if you don't have to have rules like 'always ignore ||| which is just there as legacy from the XML'.
That may be fine if we don't mind the text version being lossy, which is something else I was trying to avoid.
Don't think we need to make it lossy - just would need slightly smarter conversion tools when converting back to XML which know when they have to put in blank or standard XML fields which have been omitted for simplicity in other formats.
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
However there's an important one missing - the specification of _how_ the other object is bound to the virtual machine (e.g. is the drive bound as IDE or SCSI, and to which bus? Which network is which virtual NIC?). ... This extra field will be needed in the XML too, e.g. as 'type':
<link type="ide:0:0" rel="[22]http://purl.org/occi/storage#device" href="urn:uuid:4cc8cf62-69a4-4650-9e8c-7d4c516884df" title="Hard Drive"/> ... start to impose on the format of device identifiers which doesn't necessarily work in large, complex and/or heterogeneous environments (you say eth0, I say en1 and others say "Local Area Connection"... and that's before you start talking about paravirtualised block devices and so on)
Yes, there is an choice of whether to choose an abstract set of device identifiers (e.g. nic:0) or to allow many platform-specific variants (eth0, en0, etc.). We can't just omit the identifiers though - it is an important part of the specification of a VM to know _how_ storage, networks, etc. connect, as well as just the fact that they do. Cheers, Richard.
Ok so for the record, here's a thread between Ben Black and myself discussing XML v JSON: Sam, I'm hoping there is more to the various decisions than is outlined in this post. "Everyone is doing it" is illustrative, but not convincing. XML drags along an awful lot of baggage, which has resulted in many folks using lighter-weight formats like JSON. ATOM, in turns, lards still more baggage into the mix, again, without any clear advantage in this application. Finally, OAuth is very much in flux, as the recent security incident makes painfully clear, and, once again, its compelling advantage in this scenario is not covered above. The Sun Cloud API work is extremely solid and goes towards simplicity in almost every choice. Why are you ignoring it? Ben G'day Ben, Au contraire, we are paying *very* close attention to the Sun Cloud APIs and originally wanted to draw from them heavily were it not for a disagreement with the OGF powers that be over Creative Commons licensing. Nonetheless we have learnt a lot from them about high level concepts such as having a single entry point and "buttons" for state changes and the like. We are also looking at simple text based APIs like those used at ElasticHosts and GoGrid (and of course Amazon). Sun's decision to use JSON no doubt stems from the fact that the API was previously consumed almost exclusively by the Q-Layer web interface - it is not so clear that it is the best choice when you stray from the web and native JavaScript environments, particularly when you want to (safely) support extensibility... XML allows users to extend the API as necessary in a fashion that can be validated and will not break other extensions. Another reasonably firm requirement is that it be possible/trivial to script the interface for e.g. sysadmin tasks... for this we need a simple text based protocol anyway so we already have to support more than one output format (which is increasingly common today, even if not particularly elegant). Finally, given that technology is only half the battle (the other half being marketing/politics), it's necessary to cater to the needs of enterprise users who are well used to horrors like WS-* and who will find a lightweight XML layer refreshingly simple in comparison to the status quo. More importantly though, enterprise requirements like validation, signing, encryption, etc. are natively supported by XML and not (easily) supported for the alternatives. Oh and we are not at all wedded to OAuth - any HTTP authentication mechanism will do (though it may make sense for us to limit this somewhat for interoperability). For more specific details check out the wiki<http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/HomePage>and/or get involved yourself. Sam Sam, The onus is on you to justify the additional complexity. Rejecting simpler solutions because they are unfamiliar is dangerous. While JSON might have initially entered the protocol via Q-Layer, the current state of the work is miles from those origins. JSON has similarly moved well beyond its origins as something used by Javascript (see CouchDB for a great example). Finally, it is a simple, text-based system, far simpler than XML, and I have recent, painful experience in working in JSON and XML simultaneously for systems management. It's a no brainer: JSON wins in that space because it is easier to write, easier to read, and a lot harder to make poor, structural decisions using it. Enterprises currently use a lot of XML because that is what vendors like Microsoft foisted on them in the name of "standards". If you adopt all the existing validation and security stack for XML, you are so close to WS-* as to be indistinguishable. This work will fail if all it does is produce "WS-Cloud", and that is very much the path on which you are placing it with these choices. You can do better. Ben Ben, Thanks for your ongoing interest in this topic - your opinion is valued (and not just by me) so I would very much like us to be on the same wavelength. I've since been looking at CouchDB which is a very interesting project given one of the design patterns I've been keeping in mind is a database driven controller (that is, OCCI being a direct interface to the database) with triggers firing off e.g. AMQP messages for state changes et al. Erlang is the obvious choice for such infrastructure and it seems like CouchDB has done a lot of the work already. Of course it's well out of scope for the spec itself but it's useful to consider how it might be realised. In terms of the XML vs JSON bikeshed <http://www.bikeshed.com/> (and I say bikeshed because once you have to reach for library, as is the case for both XML and JSON, you may as well use ASN.1 on the wire for all it matters), I have many reasons for preferring XML, not the least of which is the ease at which it can be trivially converted to $PREFERRED_FORMAT using tools and expertise that already exists (the same cannot necessarily be said for the reverse, or between other formats). Very few enterprise developers have JSON exposure, let alone experience, and it's not surprising given that essential features such as schemas <http://www.json.com/json-schema-proposal/> and validation are still in a state of flux. Incidentally one thing I *do* like about YAML (and to a lesser extent, JSON) is the relative ease at which even complex data structures can be represented - this does provide more rope with which to hang oneself though. This brings us to the specifics of the proposal... XML can be [ab]used in so many different ways it's worth pointing out that the proposal uses it in the simplest way possible. Atom giving us just enough structure to link objects together, categorise them and provide metadata (such as owners, etags for caching, etc.) - as Andy observed it's more of a meta-model than anything else and we found that much of what we were trying to do was reinventing the [Atom] wheel. The actual content itself (cpu, memory, etc.) is simple, easily readable, and in all cases so far, flat... as such it's more a question of whether we use angle brackets or curly braces :) So why go for angle brackets (XML) over curly braces (JSON) given most of the action is going on in the latter camp? In addition to the reasons given above, Google. That is, if we essentially rubber stamp GData (a well proven protocol) in the form of OCCI core then it's just a matter of changing (or supporting multiple) namespaces and we may well be able to get Google on board along with a raft of running code. I've already been discussing this with Google's API gurus and product managers this week and while there's no commitment there is some amount of interest. As for WS-Cloud, I assure you this is nothing like it... I wonder when reading the WS-[death]* specs whether they weren't deliberately obfuscated in some cases and even the better ones like WS-Agreement<http://samj.net/2009/05/www.ogf.org/documents/GFD.107.pdf>are [over]complicated, in this case running out to dozens of pages. Sam On Tue, May 5, 2009 at 3:33 AM, Sam Johnston <samj@samj.net> wrote:
Morning all,
I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities).
I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly).
I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl>and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest>at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat <http://microformats.org/> as a simple demonstration of what is possible.
Anyway, without further ado:
Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html
The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like?
The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type <http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html>of the [ Semantic <http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web>as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)?
Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too.
Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand.
XML
It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers.
Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/>it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData <http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries <http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching>and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning> ).
OCCI
Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/>whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things.
The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well:
- *Copyrights* (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. - *Patents* pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842>cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble>against competitors. - *Trademarks* like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011>prevent us from even referring to the Amazon APIs by name.
While I wish the guys at Eucalyptus <http://open.eucalyptus.com/> and Canonical <http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop>whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287>and RFC 5023: Atom Publishing Protocol <http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code.
So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies).
Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing.

Sam Johnston <samj@samj.net> quotes Ben Black:
I'm hoping there is more to the various decisions than is outlined in this post. "Everyone is doing it" is illustrative, but not convincing.
XML drags along an awful lot of baggage, which has resulted in many folks using lighter-weight formats like JSON. ATOM, in turns, lards still more baggage into the mix, again, without any clear advantage in this application. Finally, OAuth is very much in flux, as the recent security incident makes painfully clear, and, once again, its compelling advantage in this scenario is not covered above. [...] The onus is on you to justify the additional complexity. Rejecting simpler solutions because they are unfamiliar is dangerous. [...] Enterprises currently use a lot of XML because that is what vendors like Microsoft foisted on them in the name of "standards". If you adopt all the existing validation and security stack for XML, you are so close to WS-* as to be indistinguishable. This work will fail if all it does is produce "WS-Cloud", and that is very much the path on which you are placing it with these choices. You can do better. [...] [It is] a lot harder to make poor, structural decisions using [json]
It's a great shame Ben hasn't joined the occi-wg so far. I'd like to put on the record my strong agreement with his points quoted above. I share his horror at the idea of accessing a simple API to a simple service via two layers of complex container formats, and agree that there has been no technical argument for this other than vague and thoroughly unconvincing references to 'enterprise users' and 'extensibility'. That said, our view is that this OCCI process will take place with or without us, and by actively taking part we can at least try to argue against some of the more extraordinary aberrations from clean design. For the same reason, I'd like to encourage Ben to get involved directly going forward. Cheers, Chris.
I'd like to see Ben involved too. Chris, if you think we have a choice to make please could you describe the options we have to choose from in more detail. On Wed, May 6, 2009 at 3:34 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Sam Johnston <samj@samj.net> quotes Ben Black:
I'm hoping there is more to the various decisions than is outlined in this post. "Everyone is doing it" is illustrative, but not convincing.
XML drags along an awful lot of baggage, which has resulted in many folks using lighter-weight formats like JSON. ATOM, in turns, lards still more baggage into the mix, again, without any clear advantage in this application. Finally, OAuth is very much in flux, as the recent security incident makes painfully clear, and, once again, its compelling advantage in this scenario is not covered above. [...] The onus is on you to justify the additional complexity. Rejecting simpler solutions because they are unfamiliar is dangerous. [...] Enterprises currently use a lot of XML because that is what vendors like Microsoft foisted on them in the name of "standards". If you adopt all the existing validation and security stack for XML, you are so close to WS-* as to be indistinguishable. This work will fail if all it does is produce "WS-Cloud", and that is very much the path on which you are placing it with these choices. You can do better. [...] [It is] a lot harder to make poor, structural decisions using [json]
It's a great shame Ben hasn't joined the occi-wg so far. I'd like to put on the record my strong agreement with his points quoted above. I share his horror at the idea of accessing a simple API to a simple service via two layers of complex container formats, and agree that there has been no technical argument for this other than vague and thoroughly unconvincing references to 'enterprise users' and 'extensibility'.
That said, our view is that this OCCI process will take place with or without us, and by actively taking part we can at least try to argue against some of the more extraordinary aberrations from clean design. For the same reason, I'd like to encourage Ben to get involved directly going forward.
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Alexis Richardson <alexis.richardson@gmail.com> writes:
Chris, if you think we have a choice to make please could you describe the options we have to choose from in more detail.
I think Richard has just beaten me to it! However, more generally, I think that before we can even have these discussions about formats, we should confirm that we're all on the same page with regard to the semantic building blocks: http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/NounsVe... I think Richard, Sam, Andy and I have all hacked at this page. Would anyone else like to comment or is there general consensus around these basic nouns, verbs and attributes? Cheers, Chris.

Hi everyone, I would like to see a clone verb (or maybe attribute, not sure about this) for drives, also maybe as an extension. I'm thinking on implementations sharing images using shared storage, this will allow to use those images directly, and obviously "cloning" set to "no" will make this image persistent automatically. What do you think? About the choice of format, as much as I like XML and Atom specially, I would advocate for the "simpler is nicer" principle is there is nothing that proves that it can do things that simple text or even JSON (from which I can see benefits for machine and human readibility) simply can´t, which also I haven't seen so far (Sam, please, correct me if I am wrong). Regards, -Tino -- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org On Wed, May 6, 2009 at 6:18 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Alexis Richardson <alexis.richardson@gmail.com> writes:
Chris, if you think we have a choice to make please could you describe the options we have to choose from in more detail.
I think Richard has just beaten me to it! However, more generally, I think that before we can even have these discussions about formats, we should confirm that we're all on the same page with regard to the semantic building blocks:
http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/NounsVe...
I think Richard, Sam, Andy and I have all hacked at this page. Would anyone else like to comment or is there general consensus around these basic nouns, verbs and attributes?
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
About the choice of format, as much as I like XML and Atom specially,
Sorry about my low level of participation. Anyone who has worked with Sun engineers knows that in the weeks leading up to JavaOne, we're typically useless for anything external. In my case, I'm actually working on making a cloud-computing facility deployable. But a bunch of things have gone by that I should really comment on. [For those who don't know, I was co-editor of XML 1.0 and co-chair of the IETF Atom working group. So I like XML and Atom too.] 1. Background I am neither a supporter nor an opponent of this OCCI work. My personal opinion is that the best time to do standards is after there is experience with interoperable implementations; so on that basis this is too early. On the other hand, I'm aware that there may be market pressure for standards sooner than would be ideal, so this work might prove to be very useful. I'm amused that there are at least three organizations working on cloud interoperability standards before we have any experience with cloud interoperability, but that's the IT business. 2. Sun Position We are going to run with our CC-licensed REST API until we have some experience operating a cloud-computing service because we think we have a whole lot to learn about where the real pain points are. That API is *not* frozen. There are other parties also experimenting with using it as a front-end to various cloud-computing services. BTW, I saw a remark in some earlier email about the Creative-Commons licensing being a problem for someone who might want to use some or all of our API spec. That is very surprising to me; if it's going to be a problem for people we'd like to hear about it. Our idea was simply to make it clear that we assert no intellectual-property claims on the API itself. 3. General advice on making standards 3.1 Dare to do less. Consider Gall's Law. Try to hit 80/20 points. Build "The simplest thing that could possibly work". When in doubt, leave it out. Essentially all the technologies that have enjoyed widespread rapid adoption on the Internet have been initially lean and mean, and were criticized for being incomplete and insufficient. Also, this increases the chances that you get it done in time to be relevant. 3.2 No optional features. Every time, in a standard, you say "you can do this or you can do that", you lose interoperability. The best example is SQL; the committee, whenever they came to a fork in the road, took both paths. As a result, SQL compliance means essentially nothing in practical terms, and database vendors use SQL to lock in their customers. 4. Specific advice on multiple formats Don't do it. Pick one data format and stick with it. Look at the RFC series, which is the most successful set of protocol designs in the history of the universe. They do not rely on interoperable models, they rely on agreement on what bytes I send you and what bytes you send me and what the meanings of the fields are. Allowing multiple formats in general, or XML and JSON in particular, is actively harmful. It is very easy in XML to create formats that can't be represented reasonably in JSON, and JSON carries a bunch of useful semantics (lists, hashes) that require extra work to specify in XML. I have opinions on which formats are most useful for a cloud-computing protocol, but the choice isn't that important. What is important is to pick one and stick with it. See 3.2 above. 5. When to use XML 5.1 When the order of elements in the message might matter. 5.2 When you anticipate trouble dealing with i18n, and can't simply say "Use UTF-8". 5.3 When you have document-like constructs, e.g. <p>This <a href="/docs/policy"> is <em>important</em>.</p> <p>So is the discussion above.</p> That kind of thing can't be represented sanely in anything but XML. 6. When to use Atom 6.1 When you are usually dealing with ordered collections of resources. 6.2 When it's essential that every item have a human-readable title, a globally-unique identifier, and a time-stamp. 6.3 When you have to wrap up document-like content, e.g. blog posts or HTML pages. [Is it now obvious why we chose JSON?] 7. Suggested reading: 7.1 Architecture of the World Wide Web: http://www.w3.org/TR/webarch/ 7.2 Modeling is hard: http://www.tbray.org/ongoing/When/200x/2009/04/29/Model-and-Syntax 7.3 On XML Language Design: http://www.tbray.org/ongoing/When/200x/2006/01/09/On-XML-Language-Design - Tim Bray, Sun Microsystems Distinguished Engineer, Director of Web Technologies +1-877-305-0889 Sun ext. 60561 AIM: MarkupPedant, Jabber: timbray@{gmail,jabber} http://www.tbray.org/ongoing/ http://twitter.com/timbray
Tim, Thank-you very much for this extremely thoughtful and helpful email. OCCI was in an important sense inspired by your work and we really appreciate your voice in this room. To introduce myself: I am a co-chair of OCCI. I run RabbitMQ which an open source AMQP messaging broker that has a number of cloud users. Through co-developing AMQP I have some of my own standards scars. I also co-founded a cloud company - CohesiveFT - that I no longer work for since RabbitMQ just became full time. AMQP has taught me that: - Simplicity really matters - And is hard - User contribution is vital - But consensus is also hard: value it - Standards take time - Over-reach causes delay - People get bored quickly these days - The state of the art may be wrong - Most technology has been done at least once before - But, things are changing all the time - It is not sufficient to be correct - Less is more I hope to be a voice for these principles in OCCI. Comments, questions and other ramblings - below: On Wed, May 6, 2009 at 6:33 PM, Tim Bray <Tim.Bray@sun.com> wrote:
About the choice of format, as much as I like XML and Atom specially,
Sorry about my low level of participation. Anyone who has worked with Sun engineers knows that in the weeks leading up to JavaOne, we're typically useless for anything external. In my case, I'm actually working on making a cloud-computing facility deployable. But a bunch of things have gone by that I should really comment on. [For those who don't know, I was co-editor of XML 1.0 and co-chair of the IETF Atom working group. So I like XML and Atom too.]
All forms of participation are crucial and we really want to hear what Sun's cloud team have to say.
1. Background
I am neither a supporter nor an opponent of this OCCI work. My personal opinion is that the best time to do standards is after there is experience with interoperable implementations; so on that basis this is too early. On the other hand, I'm aware that there may be market pressure for standards sooner than would be ideal, so this work might prove to be very useful. I'm amused that there are at least three organizations working on cloud interoperability standards before we have any experience with cloud interoperability, but that's the IT business.
Understood. Our hope is that we can reflect what has *been done* with public clouds and in so doing not invent new technology or demarcate behaviours prematurely. Failure is a possibility and for this reason we have set ourselves a very tight schedule so that if we fail we can fail fast and the interoperability community can learn from our findings. That said, we do not plan to fail. I believe that among the benefits of our approach will be to demonstrate that more than a few people can agree on *something* and that this *something* can be useful. Therefore, people can attempt to provide interoperable implementations quickly, and from this we can gain insight at least, and I hope much more. We can create real value if the deliverables are based on real world experience and humbly pursued. The issue of multiple efforts is IMO a natural consequence of the technology extravaganza that "Cloud" has become. Ho, and indeed, hum. I hope our efforts can make a mark and do not see this as a competition. If I had to pick one thing that makes us different, I would like it to be 'community based approach'. There are some really talented people helping OCCI move along and many of them have learnt their trade through open source and other developer communities. This is not in any way to cast doubt on the voice of the large vendor, but it may give OCCI a certain flavour.
2. Sun Position
We are going to run with our CC-licensed REST API until we have some experience operating a cloud-computing service because we think we have a whole lot to learn about where the real pain points are. That API is *not* frozen. There are other parties also experimenting with using it as a front-end to various cloud-computing services.
Cool - can you or they contribute some use cases please? We needs dem use cases :-)
BTW, I saw a remark in some earlier email about the Creative-Commons licensing being a problem for someone who might want to use some or all of our API spec. That is very surprising to me; if it's going to be a problem for people we'd like to hear about it. Our idea was simply to make it clear that we assert no intellectual-property claims on the API itself.
Sam - could you comment on this please? Tim - we obviously want to achieve harmony here and I hope we can clear this up.
3. General advice on making standards
3.1 Dare to do less. Consider Gall's Law. Try to hit 80/20 points. Build "The simplest thing that could possibly work". When in doubt, leave it out. Essentially all the technologies that have enjoyed widespread rapid adoption on the Internet have been initially lean and mean, and were criticized for being incomplete and insufficient. Also, this increases the chances that you get it done in time to be relevant.
+1 "in time" is key to our approach and thanks for these comments
3.2 No optional features. Every time, in a standard, you say "you can do this or you can do that", you lose interoperability. The best example is SQL; the committee, whenever they came to a fork in the road, took both paths. As a result, SQL compliance means essentially nothing in practical terms, and database vendors use SQL to lock in their customers.
+1 again. We have just learnt this with AMQP and as a result the 1.0 work is starting to look really rather good. Strategic silence for the win: Success breeds use and hence trust, which leads to innovation.
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it. Look at the RFC series, which is the most successful set of protocol designs in the history of the universe.
That's a big place :-)
They do not rely on interoperable models, they rely on agreement on what bytes I send you and what bytes you send me and what the meanings of the fields are. Allowing multiple formats in general, or XML and JSON in particular, is actively harmful. It is very easy in XML to create formats that can't be represented reasonably in JSON, and JSON carries a bunch of useful semantics (lists, hashes) that require extra work to specify in XML.
That sounds like a protocol mindset - consistent with your RFC comment above. But is OCCI a protocol? Or is it an API? What are your thoughts here? (note - I like protocols)
I have opinions on which formats are most useful for a cloud-computing protocol, but the choice isn't that important. What is important is to pick one and stick with it. See 3.2 above.
OK. We are heading to consensus in which we stick to really simple (currently: flat) formats so JSON or XML are both candidates right now. More generally: What is the right way to make a cloud interface more like a protocol?
5. When to use XML
5.1 When the order of elements in the message might matter.
5.2 When you anticipate trouble dealing with i18n, and can't simply say "Use UTF-8".
5.3 When you have document-like constructs, e.g.
<p>This <a href="/docs/policy"> is <em>important</em>.</p> <p>So is the discussion above.</p>
That kind of thing can't be represented sanely in anything but XML.
How would you recommend we deal with cases where XML is well supported but JSON is not well known? * .NET * Many 'enterprises' Though of course this can change very fast. If we 'went with JSON' then would it be plausible to have XML adaptors for non-JSON settings? What about plain text - any view on that?
6. When to use Atom
6.1 When you are usually dealing with ordered collections of resources.
6.2 When it's essential that every item have a human-readable title, a globally-unique identifier, and a time-stamp.
6.3 When you have to wrap up document-like content, e.g. blog posts or HTML pages.
[Is it now obvious why we chose JSON?]
No :-) I am a dullard so please can you be more explicit. Do you think Atom is a bad thing for our use cases? alexis
7. Suggested reading:
7.1 Architecture of the World Wide Web: http://www.w3.org/TR/webarch/
7.2 Modeling is hard: http://www.tbray.org/ongoing/When/200x/2009/04/29/Model-and-Syntax
7.3 On XML Language Design: http://www.tbray.org/ongoing/When/200x/2006/01/09/On-XML-Language-Design
- Tim Bray, Sun Microsystems Distinguished Engineer, Director of Web Technologies +1-877-305-0889 Sun ext. 60561 AIM: MarkupPedant, Jabber: timbray@{gmail,jabber} http://www.tbray.org/ongoing/ http://twitter.com/timbray
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On May 6, 2009, at 1:44 PM, Alexis Richardson wrote:
Failure is a possibility and for this reason we have set ourselves a very tight schedule so that if we fail we can fail fast and the interoperability community can learn from our findings.
FWIW, I've never seen a non-trivial language/protocol/API/standard/ whatever designed in less than a year, elapsed.
We are going to run with our CC-licensed REST API ... There are other parties also experimenting with using it as a front-end to various cloud-computing services.
Cool - can you or they contribute some use cases please? We needs dem use cases :-)
Good point. We have internal ones, had actually never thought of publishing them. I'll see what I can do.
They do not rely on interoperable models, they rely on agreement on what bytes I send you and what bytes you send me and what the meanings of the fields are. ....
That sounds like a protocol mindset - consistent with your RFC comment above. But is OCCI a protocol? Or is it an API? What are your thoughts here?
I don't understand the difference, to be honest. The problem is that when you say API people expect object models and methods, and history should have taught us that those are very difficult to make portable across networks. I confess to having a protocol mindset since I'm a Web guy.
More generally: What is the right way to make a cloud interface more like a protocol?
My opinion: Be RESTful, to the extent possible.
How would you recommend we deal with cases where XML is well supported but JSON is not well known?
* .NET * Many 'enterprises'
Hmm... if you're in Java or Python or Ruby or of course JavaScript, it's super-easy to consume and generate JSON. If C# & friends are behind in this respect I can't see it staying that way for very long, my impression is that those guys are serious about keeping up with the joneses.
If we 'went with JSON' then would it be plausible to have XML adaptors for non-JSON settings?
Specifying the mapping is extra work. I suggest that YAGNI.
What about plain text - any view on that?
Well, in our API, it turned out that the things we wanted to send back and forth were numbers, labels, lists and hashes. Without exception. JSON had everything we needed built-in and nothing we didn't need.
Do you think Atom is a bad thing for our use cases?
I'm not sure; I enumerated the things that I think would make Atom attractive. For our use cases in the Sun API, it didn't seem like a terribly good match. -Tim
On Thu, May 7, 2009 at 1:17 AM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 6, 2009, at 1:44 PM, Alexis Richardson wrote:
Failure is a possibility and for this reason we have set ourselves a very tight schedule so that if we fail we can fail fast and the interoperability community can learn from our findings.
FWIW, I've never seen a non-trivial language/protocol/API/standard/ whatever designed in less than a year, elapsed.
True. I've been working on the problem for about a year now so I guess that counts for something, plus we're trying to find the consensus of a large and growing number of existing APIs so we're not starting from scratch. If this trivia doesn't derail us I'm expecting to have a rough spec and reference implementation demo in place in time for my Europe tour starting Monday week.
Cool - can you or they contribute some use cases please? We needs dem use cases :-)
Good point. We have internal ones, had actually never thought of publishing them. I'll see what I can do.
+1 that would be awesome - even if they're deidentified.
They do not rely on interoperable models, they rely on agreement on what bytes I send you and what bytes you send me and what the meanings of the fields are. ....
That sounds like a protocol mindset - consistent with your RFC comment above. But is OCCI a protocol? Or is it an API? What are your thoughts here?
I don't understand the difference, to be honest.
The problem is that when you say API people expect object models and methods, and history should have taught us that those are very difficult to make portable across networks. I confess to having a protocol mindset since I'm a Web guy.
I can see some value in running a knife down the middle... hence the talk about OCCI Core vs OCCI IaaS - where the former is a protocol ala HTTP (actually based on HTTP + Atom + magic fairy dust for search, caching, etc.) and the latter more an API that animates the resources with controllers/actuators, network and storage links, attributes, etc.
More generally: What is the right way to make a cloud interface more
like a protocol?
My opinion: Be RESTful, to the extent possible.
Agreed, no point redoing what HTTP's already done.
How would you recommend we deal with cases where XML is well supported but JSON is not well known?
* .NET * Many 'enterprises'
Hmm... if you're in Java or Python or Ruby or of course JavaScript, it's super-easy to consume and generate JSON. If C# & friends are behind in this respect I can't see it staying that way for very long, my impression is that those guys are serious about keeping up with the joneses.
There's some ASP.NET stuff and some 3rd party stuff but it's certainly not burnt into the DNA like XML is.
If we 'went with JSON' then would it be plausible to have XML adaptors for non-JSON settings?
Specifying the mapping is extra work. I suggest that YAGNI.
I'll check it out.
What about plain text - any view on that?
Well, in our API, it turned out that the things we wanted to send back and forth were numbers, labels, lists and hashes. Without exception. JSON had everything we needed built-in and nothing we didn't need.
Do you think Atom is a bad thing for our use cases?
I'm not sure; I enumerated the things that I think would make Atom attractive. For our use cases in the Sun API, it didn't seem like a terribly good match.
I definitely want us all to be on the same wavelength whatever we end up doing, but I also want to avoid closing doors unnecessarily (e.g. for enterprise/private cloud deployments). Sun Cloud API does look particularly good for public cloud (certainly better than the incumbent). Sam
On Wed, May 6, 2009 at 4:57 PM, Sam Johnston <samj@samj.net> wrote:
There's some ASP.NET stuff and some 3rd party stuff but it's certainly not burnt into the DNA like XML is.
Have you considered how it got "burnt into the DNA"? People made protocols and the tools were made to support them. We need to design the best protocol(s) we can, not simply the best protocol we can given the constraints of what Visual Studio can do today. If we get it right, the tools will follow. If we get it wrong, the tools support won't matter. For some additional context: XML dates from about 1996 (Tim, please correct me) and JSON from about 1999. You'll find that many big players use have JSON support in their APIs, for example, the frequently mentioned GData: http://code.google.com/apis/gdata/samples.html#JSON . This is not new stuff. It's just gotten a lot less attention for most of its existence. That is changing rapidly for good reason. We should pay attention to those reasons rather than clinging to the past based on vague notions of 'maturity'. Ben
Sam, On Thu, May 7, 2009 at 12:57 AM, Sam Johnston <samj@samj.net> wrote:
I can see some value in running a knife down the middle... hence the talk about OCCI Core vs OCCI IaaS - where the former is a protocol ala HTTP (actually based on HTTP + Atom + magic fairy dust for search, caching, etc.) and the latter more an API that animates the resources with controllers/actuators, network and storage links, attributes, etc.
Admittedly I don't fully understand this but at face value I'd suggest providing 'Core' first, whatever that is.
How would you recommend we deal with cases where XML is well supported but JSON is not well known?
* .NET * Many 'enterprises'
Hmm... if you're in Java or Python or Ruby or of course JavaScript, it's super-easy to consume and generate JSON. If C# & friends are behind in this respect I can't see it staying that way for very long, my impression is that those guys are serious about keeping up with the joneses.
There's some ASP.NET stuff and some 3rd party stuff but it's certainly not burnt into the DNA like XML is.
Personally I am in favour of JSON if it works and endorse Ben's comment about not being tied down to whatever is in Visual Studio today. I do think .NET will support JSON as a first class data format in its official tools. If it is acceptable to use JSON in OCCI in order to stick to one format for now (and learn from Sun's work) then great. I note that GData supports JSON. I'd like to hear more from the .NET and 'enterprise' crowd though.
If we 'went with JSON' then would it be plausible to have XML adaptors for non-JSON settings?
Specifying the mapping is extra work. I suggest that YAGNI.
I'll check it out.
Great!
Do you think Atom is a bad thing for our use cases?
I'm not sure; I enumerated the things that I think would make Atom attractive. For our use cases in the Sun API, it didn't seem like a terribly good match.
I definitely want us all to be on the same wavelength whatever we end up doing, but I also want to avoid closing doors unnecessarily (e.g. for enterprise/private cloud deployments). Sun Cloud API does look particularly good for public cloud (certainly better than the incumbent).
We do need to be careful about the difference between sticking to our charter to the letter (public cloud first) and not closing doors. It's a fine line. alexis
On Thu, May 7, 2009 at 9:32 AM, Alexis Richardson < alexis.richardson@gmail.com> wrote:
Sam,
On Thu, May 7, 2009 at 12:57 AM, Sam Johnston <samj@samj.net> wrote:
I can see some value in running a knife down the middle... hence the talk about OCCI Core vs OCCI IaaS - where the former is a protocol ala HTTP (actually based on HTTP + Atom + magic fairy dust for search, caching,
etc.)
and the latter more an API that animates the resources with controllers/actuators, network and storage links, attributes, etc.
Admittedly I don't fully understand this but at face value I'd suggest providing 'Core' first, whatever that is.
The ideal core protocol would contain no references to infrastructure, rather allow manipulation of resources (CRUD, linking, actuators) irrespective of what the resource was. It would thus be reusable for any resource (as Google have done for 16 different services<http://code.google.com/apis/gdata/>and who knows how many different resource types already with GData). The IaaS part would then define compute, storage and network resources and the various actions and linkages that make sense, leaving as much room as possible for innovation but ensuring the common parts are interoperable. In a year or two when people realise infrastructure is boring we'd just need to define resources for platform and software services rather than rewrite the protocol (almost certainly without backwards compatibility), or worse, create a new one.
How would you recommend we deal with cases where XML is well supported but JSON is not well known?
* .NET * Many 'enterprises' <snip>
Personally I am in favour of JSON if it works and endorse Ben's comment about not being tied down to whatever is in Visual Studio today. I do think .NET will support JSON as a first class data format in its official tools.
I've made it quite clear that I don't believe JSON will work (giving various technical reasons for same though there are various non-technical reasons too) and was hoping to see at least some of the outstanding questions addressed today now everyone's back to work. "First class citizen" support of JSON is another of the more serious concerns - as it's executable(!?!?) JavaScript code it's obviously a first class citizen for JavaScript, but even for Java there are no less than 18 different projects listed at json.org in addition to the unsupported reference code <http://www.json.org/java/>. Enterprise movers and shakers will be pleased to know Python has just added the json module<http://docs.python.org/library/json.html>, only most of them are lucky to be using 2.5, let alone 2.6/3.0. For Microsoft's .NET languages though they're out of luck (except for some JSON code buried in ASP.NET AJAX <http://www.asp.net/ajax/>) and it's the same story pretty much wherever you look - with the exception of PHP, native (let alone "first class citizen") support of JSON is very much a work in progress. Most of the enterprise developers I know/work with wouldn't be allowed to touch most of this stuff without approval which (depending on the organisation) can be notoriously difficult to get - especially where legal has to approve the license. Native support is no problem though and I doubt there's a language in common use today that lacks native XML functionality. Ask again on an OCCI 2.0 timeframe.
If it is acceptable to use JSON in OCCI in order to stick to one format for now (and learn from Sun's work) then great. I note that GData supports JSON. I'd like to hear more from the .NET and 'enterprise' crowd though.
Has anyone (including Sun for that matter) implemented, let alone achieved interoperability with the Sun Cloud APIs? If not, what is there to learn that we haven't already gleaned from them (e.g. actuators)? I'm very happy to have Sun involved in this process (especially veterans like Tim) but they have stated they have no plans to implement the API I do think our requirements differ somewhat - Sun need an API for exposing the functionality of a specific public cloud service while we need one for exposing the [current and future] functionality of *every* service, public and private (including arbitrarily complex enterprise systems). Also am I the only one to notice that JSON is not in fact a standard, rather the work of one (admittedly rather clever) Yahoo engineer<http://en.wikipedia.org/wiki/Douglas_Crockford>? RFC 4627 <http://www.ietf.org/rfc/rfc4627.txt> is informational and "does not specify an Internet standard of any kind", having crept in under the guise of defining the application/json media type. That's fine for integration/convenience, but not for interop. Is it even possible (let alone sensible) to build a standard on top of a non-standard? Is there any precedent for SSO standards based on JSON? I still can't find any successful JSON-only APIs in the wild and this is one of my outstanding questions.
If we 'went with JSON' then would it be plausible to have XML adaptors
for non-JSON settings?
Specifying the mapping is extra work. I suggest that YAGNI.
I'll check it out.
Great!
Ok so I'm an idiot (perhaps we both are) - YAGNI<http://en.wikipedia.org/wiki/YAGNI>is basically saying we don't need multiple formats despite there being various demands for same. It does seem likely that Sun don't need multiple formats for their service, but that's not to say we don't - the TXT format is an absolute requirement for use case E.2. "Simple scripting of cloud from Unix shell<http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/SimpleScriptingOfCloudFromUnixShell>" for example
Do you think Atom is a bad thing for our use cases?
I'm not sure; I enumerated the things that I think would make Atom attractive. For our use cases in the Sun API, it didn't seem like a terribly good match.
I definitely want us all to be on the same wavelength whatever we end up doing, but I also want to avoid closing doors unnecessarily (e.g. for enterprise/private cloud deployments). Sun Cloud API does look particularly good for public cloud (certainly better than the incumbent).
We do need to be careful about the difference between sticking to our charter to the letter (public cloud first) and not closing doors. It's a fine line.
Perhaps I'm going too far with genericity/extensibility but better too far than not far enough. This is more a side effect of accelerating change and not knowing what computing will look like next year, let alone for the entire useful lifetime of the standard! Sam
On May 11, 2009, at 1:54 PM, Sam Johnston wrote:
The ideal core protocol would contain no references to infrastructure, rather allow manipulation of resources (CRUD, linking, actuators) irrespective of what the resource was. It would thus be reusable for any resource (as Google have done for 16 different services and who knows how many different resource types already with GData).
Odd though it may seem, until I saw this I didn't grok what Sam was proposing. Maybe I still don't, but let me take a guess: You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. Thus you outsource most of the work of CRUD specification. Then, you layer cloud-specific stuff on top of that. Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds. Is that the essence of it? -Tim

I like Tim's explanation. I have some on some trivial subjects... 1) Are we also talking about using IRIs or URIs only ? 2) What is the thoughts on handling foreign markups at endpoints and gateways/bridges ? 3) How are the scheme attributes handled for child element when presented without the parent element that has the scheme assignment ? 4) Can we publish work spaces ? Will work spaces require authorization? 5) Will there be top level resources be defined? or will each vendor define their own resources schemes? How do we preserve proprietary technology? 6) How are document writers/editors defined and authorized ? 7) Will there be document caching/synchronization policies and schemes ? 8) How are collection components authorized ? Private/authorized partial lists in collection of public lists ? 9) What are the policies for conformance levels? Will occi define our own ? 10) What will the policy be for non-IANA content ? Sorry for the long list.. -gary Tim Bray wrote:
On May 11, 2009, at 1:54 PM, Sam Johnston wrote:
The ideal core protocol would contain no references to infrastructure, rather allow manipulation of resources (CRUD, linking, actuators) irrespective of what the resource was. It would thus be reusable for any resource (as Google have done for 16 different services and who knows how many different resource types already with GData).
Odd though it may seem, until I saw this I didn't grok what Sam was proposing. Maybe I still don't, but let me take a guess:
You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. Thus you outsource most of the work of CRUD specification. Then, you layer cloud-specific stuff on top of that. Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds.
Is that the essence of it? -Tim _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Morning Gary, On Tue, May 12, 2009 at 10:24 AM, Gary Mazz <garymazzaferro@gmail.com>wrote:
I like Tim's explanation.
I have some on some trivial subjects...
1) Are we also talking about using IRIs or URIs only ?
There was some discussion about this before with Ben Black - Atom IDs are not meant to be dereferenceable so for simplicity (especially w.r.t. concurrency and migration/merging of resources safely) there was an earlier decision to use version 4 (random) UUID URN<http://en.wikipedia.org/wiki/Uniform_Resource_Name>s for the IDs. There was then some contention as to whether link relations should specify the URN of the target resource or a dereferenceable URI... I prefer the former (bearing in mind that the same resource can appear at multiple endpoints, dereferenceable URIs are easily created and working internal document references are useful) while Ben prefers the latter. These and related topics probably need further discussion re: pros and cons down the road.
2) What is the thoughts on handling foreign markups at endpoints and gateways/bridges ?
Foreign markups should/must not be touched (not sure which requirement level to use here) as this is the basis of much of our extensibility.
3) How are the scheme attributes handled for child element when presented without the parent element that has the scheme assignment ?
Elaborate - not sure what you mean here.
4) Can we publish work spaces ? Will work spaces require authorization?
Workspaces are neither required nor supported by Google's GData implementation so there is good reason to believe that we won't need them. If the use case doesn't exist then I'd opt for the simplicity of excluding them from the spec.
5) Will there be top level resources be defined? or will each vendor define their own resources schemes? How do we preserve proprietary technology?
We need to define this, at least at a high level, for interoperability. So far I had made provision for three top level categories (compute, storage and network) or "types" (what Google call "kinds").
6) How are document writers/editors defined and authorized ?
Out of scope - I'm not even sure we need to specify how they are authenticated (though I have a whitelist on the Resources page already if we take an interest in this). Authorisation can range from none (simple XML file on embedded web server) to fine grained/field level, depending on the implementation. I'm expecting this to be an area where implementors can differentiate themselves.
7) Will there be document caching/synchronization policies and schemes ?
Google have used ETags with good results<http://globelogger.com/2008/11/gdata-now-compliant-with-atompub.html>, and this makes a lot of sense given much of the work for clients will be keeping their view of the world in sync with reality. Being able to crank up a desktop client and have it display a large number of [cached] resources in seconds even over a modest link becomes a reality with this approach - and web based third-party services like RightScale have similar needs.
8) How are collection components authorized ? Private/authorized partial lists in collection of public lists ?
See above - two different users looking at the same endpoint may or may not see different things depending on which resources they are authorised to see. Public cloud offerings may have many millions of resources at a single endpoint but your average user will only see a small handful, while an enterprise setup may have all authenticated users seeing the same thing. I don't see much point in trying to burn any of this into the standard.
9) What are the policies for conformance levels? Will occi define our own ?
Possibly, though I would prefer to keep the core simple and require everyone to implement it fully and faithfully.
10) What will the policy be for non-IANA content ?
I'm guessing by this you mean Internet media types<http://en.wikipedia.org/wiki/Internet_media_type>that are not defined by IANA, in which case we have the usual x-, vnd. and prs. namespaces available.
Sorry for the long list..
No problem - the more detailed the discussion the better the result. Sam
Tim Bray wrote:
On May 11, 2009, at 1:54 PM, Sam Johnston wrote:
The ideal core protocol would contain no references to infrastructure, rather allow manipulation of resources (CRUD, linking, actuators) irrespective of what the resource was. It would thus be reusable for any resource (as Google have done for 16 different services and who knows how many different resource types already with GData).
Odd though it may seem, until I saw this I didn't grok what Sam was proposing. Maybe I still don't, but let me take a guess:
You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. Thus you outsource most of the work of CRUD specification. Then, you layer cloud-specific stuff on top of that. Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds.
Is that the essence of it? -Tim _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On May 12, 2009, at 2:36 AM, Sam Johnston wrote:
1) Are we also talking about using IRIs or URIs only ?
There was some discussion about this before with Ben Black - Atom IDs are not meant to be dereferenceable
That is not correct. Their primary purpose is to act as unique identifiers, but the normative text (properly) sets no expectation about whether they should be usable for dereference. Many people feel that dereferenceable identifiers are generally speaking of higher value and are predisposed to use "http:" everywhere. This is one reason it's usually wrong to micromanage users' choice of URI schemes. -Tim
On Tue, May 12, 2009 at 5:51 PM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 12, 2009, at 2:36 AM, Sam Johnston wrote:
1) Are we also talking about using IRIs or URIs only ?
There was some discussion about this before with Ben Black - Atom IDs are not meant to be dereferenceable
That is not correct. Their primary purpose is to act as unique identifiers, but the normative text (properly) sets no expectation about whether they should be usable for dereference. Many people feel that dereferenceable identifiers are generally speaking of higher value and are predisposed to use "http:" everywhere. This is one reason it's usually wrong to micromanage users' choice of URI schemes. -Tim
Sorry I didn't mean "must not be", rather "are not necessarily". Normally I would agree to leave users to do as they want here, and perhaps there is still some value in this (provided they follow some scheme to ensure global uniqueness, likely based on randomness and/or internet domains) but UUID URNs seem both simpler and safer. They're trivial to generate concurrently (even disconnected) and without having to maintain a central register or sequence. Most importantly they don't reveal sensitive information (such as the number of resources), don't break when they appear in multiple places (conversely a http:// URL would appear as two resources) and they can be trivially migrated and merged (e.g. migrating between providers without having to rename/remap resources and links which could be a very expensive operation for a large collection). Definitely worth considering in more detail, but we do know we can get the resource from "/<uuid>" and we can always make this explicit with rel="self" links. Sam
On Tue, May 12, 2009 at 7:34 AM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 11, 2009, at 1:54 PM, Sam Johnston wrote:
The ideal core protocol would contain no references to infrastructure,
rather allow manipulation of resources (CRUD, linking, actuators) irrespective of what the resource was. It would thus be reusable for any resource (as Google have done for 16 different services and who knows how many different resource types already with GData).
Odd though it may seem, until I saw this I didn't grok what Sam was proposing. Maybe I still don't, but let me take a guess:
It's quite possible I've not done a good enough job of explaining myself until now...
You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. Thus you outsource most of the work of CRUD specification. Then, you layer cloud-specific stuff on top of that. Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds.
Is that the essence of it? -Tim
Essentially, yes<http://googledataapis.blogspot.com/2008/11/like-version-atompub-compliant-for-very.html>- at least a subset of it (I'm not sure that service and category documents are supported nor required by GData to date) with simple extensions for querying, concurrency/performance and any other implementation issues we come across on the way. I've been focusing on Atom because that's how the data is rendered - AtomPub as you well know tells us how to discover and manipulate the Atom resources on the server. Sam
You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. *Thus you outsource most of the work of CRUD specification. *Then, you layer cloud-specific stuff on top of that. *Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds.
Is that the essence of it? *-Tim
Essentially, yes - at least a subset of it (I'm not sure that service and category documents are supported nor required by GData to date) with simple extensions for querying, concurrency/performance and any other implementation issues we come across on the way. I've been focusing on Atom because that's how the data is rendered - AtomPub as you well know tells us how to discover and manipulate the Atom resources on the server.
My biggest concern about the GData-style approach is not XML vs. JSON syntax ('angle bracket vs. curly brackets), but whether pulling in the GData/AtomPub meta-model is worth it to outsource the CRUD specification. My example of a simple JSON rendering really has two differences from the GData-XML approach: 1) [Less significant] JSON vs. XML syntax ('angle brackets vs. curly brackets') - a trivial decision, as demonstrated by the equivalent XML http://www.ogf.org/pipermail/occi-wg/2009-May/000526.html 2) [More significant] Very light meta-model - completely specified at http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/SimpleJSONRen... versus pulling in the GData meta-model to wrap the cloud infrastructure objects. I note that all existing cloud APIs (Amazon, Sun, GoGrid, ElasticHosts, etc.) have similarly specified their APIs directly over HTTP rather than over a pre-existing meta model. Whilst Sam is right that GData libraries do exist for many platforms, they are not universal and do run to tens of thousands of lines of code*. Should we really be pulling in a dependency which is this large when we have a clear choice not to? Richard. * Within http://gdata-python-client.googlecode.com/files/gdata-1.3.1.tar.gz "wc -l src/{atom,gdata}/*.py" gives 13.7 kloc. Within http://gdata-java-client.googlecode.com/files/gdata-src.java-1.31.1.zip "wc -l java/src/com/google/gdata/*/*.java" gives 33.9 kloc
Why can't Google be an integration point? I may be missing something about how the metamodel and CRUD vs 'pure' REST work here... On Tue, May 12, 2009 at 11:59 AM, Richard Davies <richard.davies@elastichosts.com> wrote:
You're focusing not so much Atom the RFC4287 data format, but AtomPub the RFC5023 publishing protocol as implemented notably in GData and lots of other places, and do generic Web-resource CRUD where the resources happen to represent cloud infrastructure objects. *Thus you outsource most of the work of CRUD specification. *Then, you layer cloud-specific stuff on top of that. *Then collections of servers and clusters and networks and so on are perforce represented as Atom Feeds.
Is that the essence of it? *-Tim
Essentially, yes - at least a subset of it (I'm not sure that service and category documents are supported nor required by GData to date) with simple extensions for querying, concurrency/performance and any other implementation issues we come across on the way. I've been focusing on Atom because that's how the data is rendered - AtomPub as you well know tells us how to discover and manipulate the Atom resources on the server.
My biggest concern about the GData-style approach is not XML vs. JSON syntax ('angle bracket vs. curly brackets), but whether pulling in the GData/AtomPub meta-model is worth it to outsource the CRUD specification.
My example of a simple JSON rendering really has two differences from the GData-XML approach:
1) [Less significant] JSON vs. XML syntax ('angle brackets vs. curly brackets') - a trivial decision, as demonstrated by the equivalent XML http://www.ogf.org/pipermail/occi-wg/2009-May/000526.html
2) [More significant] Very light meta-model - completely specified at http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/SimpleJSONRen... versus pulling in the GData meta-model to wrap the cloud infrastructure objects.
I note that all existing cloud APIs (Amazon, Sun, GoGrid, ElasticHosts, etc.) have similarly specified their APIs directly over HTTP rather than over a pre-existing meta model.
Whilst Sam is right that GData libraries do exist for many platforms, they are not universal and do run to tens of thousands of lines of code*.
Should we really be pulling in a dependency which is this large when we have a clear choice not to?
Richard.
* Within http://gdata-python-client.googlecode.com/files/gdata-1.3.1.tar.gz "wc -l src/{atom,gdata}/*.py" gives 13.7 kloc.
Within http://gdata-java-client.googlecode.com/files/gdata-src.java-1.31.1.zip "wc -l java/src/com/google/gdata/*/*.java" gives 33.9 kloc _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Tim, Thanks for this. On Thu, May 7, 2009 at 12:17 AM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 6, 2009, at 1:44 PM, Alexis Richardson wrote:
Failure is a possibility and for this reason we have set ourselves a very tight schedule so that if we fail we can fail fast and the interoperability community can learn from our findings.
FWIW, I've never seen a non-trivial language/protocol/API/standard/whatever designed in less than a year, elapsed.
We're trying to make use of work already done, as much as possible, to move things along. If we can get to a place where people can at least properly explore interop, I think that's a good start for something that will evolve (cf. your comments about how you are exploring the Sun API by building some clouds).
We are going to run with our CC-licensed REST API ... There are other parties also experimenting with using it as a front-end to various cloud-computing services.
Cool - can you or they contribute some use cases please? We needs dem use cases :-)
Good point. We have internal ones, had actually never thought of publishing them. I'll see what I can do.
Awesome, thanks.
They do not rely on interoperable models, they rely on agreement on what bytes I send you and what bytes you send me and what the meanings of the fields are. ....
That sounds like a protocol mindset - consistent with your RFC comment above. But is OCCI a protocol? Or is it an API? What are your thoughts here?
I don't understand the difference, to be honest.
I think they are different - see below.
The problem is that when you say API people expect object models and methods, and history should have taught us that those are very difficult to make portable across networks. I confess to having a protocol mindset since I'm a Web guy.
You know much more about this than I do, so at the risk of looking foolish, I'll pedantically state my own view on protocols vs APIs. * Protocols can specify a sequence of behaviours, eg a 3-way handshake to establish a connection, eg also continuations (such as used by trickles - http://www.cs.cornell.edu/~ashieh/trickles/index.php) * APIs are functional, so remain silent on what happens after a request is replied to. * By specifying behaviour, protocols disambiguate more interaction scenarios thereby improving interop. * Example API - JMS. It's hard to swap out one JMS server for another because they may behave in different ways. Often the client and server must be provided by one vendor and, indeed, taken from one software distribution. Versioning can be a problem. * Example protocol - TCP. This is basically plug and play if you stick to the core. Same for HTTP. You can get a browser from one vendor and it should work with someone else's web server and web site. * Often, but not always, protocols are based on wire formats, reducing the scope for variations due to language choice, for example nuances between how the JVM and CLR model objects. Returning to JMS as an example, it's a fiddle to get JMS working well in .NET. Most internet RFCs are protocols afaict - hence their success. IMO, the 'good' REST/HTTP designs enforce a protocol-like discipline, even though the limitations of HTTP plus the focus on nouns and verbs also admit of API-like designs. I'd suggest that HATEOAS forces interface designers to think in terms of application state evolving outside the scope of a single HTTP request, therefore it pushes them towards a protocol way of thinking. By constrast, RESTful interfaces that implement pure CRUD, look a lot like CRUD APIs that just so happen to be expressed using HTTP verbs. /end digression
More generally: What is the right way to make a cloud interface more like a protocol?
My opinion: Be RESTful, to the extent possible.
+1
How would you recommend we deal with cases where XML is well supported but JSON is not well known?
* .NET * Many 'enterprises'
Hmm... if you're in Java or Python or Ruby or of course JavaScript, it's super-easy to consume and generate JSON. If C# & friends are behind in this respect I can't see it staying that way for very long, my impression is that those guys are serious about keeping up with the joneses.
If we 'went with JSON' then would it be plausible to have XML adaptors for non-JSON settings?
Specifying the mapping is extra work. I suggest that YAGNI.
If we agree that all our data formats *can* be written in JSON, then an option for OCCI's initial deliverable is to mandate that they are written in JSON or at least provide this as a reference. I'd like to see a list of objections to this.
What about plain text - any view on that?
Well, in our API, it turned out that the things we wanted to send back and forth were numbers, labels, lists and hashes. Without exception. JSON had everything we needed built-in and nothing we didn't need.
Do you think Atom is a bad thing for our use cases?
I'm not sure; I enumerated the things that I think would make Atom attractive. For our use cases in the Sun API, it didn't seem like a terribly good match.
OK. alexis
Tim, Thanks very much for your work on the Sun Cloud API. I look forward to more attention turning to using that as the basis for this work as you've done such a solid job of it, I see no point in re-inventing. Ben
I'd like to conduct a straw poll of members on this list. Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion. I'd like to conduct a poll of everyone on this list considering the 3 format options: - XML - JSON - TXT Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer. I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count. XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote)
Thanks Richard. Good call. Re JSON vs XML - Please note that we have not discussed the OVF point that Sam has raised. Although, I think the .NET point is addressed by (a) providing an adaptor (though Tim thinks YAGNI), (b) assuming that .NET will support JSON as first class in mainstream tools soon enough. On Thu, May 7, 2009 at 8:37 AM, Richard Davies <richard.davies@elastichosts.com> wrote:
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3 format options:
- XML - JSON - TXT
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg

Hi, I've tried to follow the thread. And here's my 50 cents. I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text. So for me multi-format is mandatory... and looking at the community this group is made of, I think it's the only way forward. From similar discussions in other spheres... the real point (and someone else made that point already), is >>simplicity<<. So XML's easy to transform. JSON's easy to consume. Text is simple... So... my vote is... all of the above! And as long as the format is aggressively simple... the mapping should be trivial! Cheers, Meb Richard Davies wrote:
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3 format options:
- XML - JSON - TXT
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Thu, May 7, 2009 at 10:12 AM, Marc-Elian Begin <meb@sixsq.com> wrote:
So... my vote is... all of the above!
+1 all of the above. Polling is not a substitute for discussion<http://en.wikipedia.org/wiki/Wikipedia:NOTAVOTE>, though it's interesting input. There appears to be a lot of I [don't] like it <http://en.wikipedia.org/wiki/Wikipedia:ILIKEIT#I_like_it> going on too which is disconcerting. Sam (who would say more were it not for having a plane to catch)
Please consider what this actually means: all 3 must be specified, they must all be maintained, and they must all be kept compatible. Once we've done all that work, people have the choice of either a) producing implementations that use all 3 or b) producing implementations that may be mutually incompatible. (b) should really give us pause on the multi-format path. The ability to trivially produce mutually incompatible, but compliant, implementations is a serious protocol specification failure. Ben On Thu, May 7, 2009 at 1:12 AM, Marc-Elian Begin <meb@sixsq.com> wrote:
Hi,
I've tried to follow the thread. And here's my 50 cents.
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory... and looking at the community this group is made of, I think it's the only way forward.
From similar discussions in other spheres... the real point (and someone else made that point already), is >>simplicity<<.
So XML's easy to transform. JSON's easy to consume. Text is simple...
So... my vote is... all of the above! And as long as the format is aggressively simple... the mapping should be trivial!
Cheers,
Meb
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3
options:
- XML - JSON - TXT
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split,
Richard Davies wrote: format then
multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html(split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"? The intervening steps in the argument are not self-evident. -T

Actually, while following the discussion for a while now, I feel that we have a strawman discussion here. In general, I agree to the general consensus that data representation should be simple. Really simple. Nothing is more frustrating than having to implement, maintain, and sell a complex beast to people outside (tm). However, we should remember to not mix up model and rendering. The question whether to use RESTful services with CSV, WS-Mayhem, or JSON over avian carriers is a question of _rendering_. I second the fact that this is an important issue to decide upon at some point. But unless we have agreed on the _model_, we haven't reached this point IMHO. The canonical way to cope with this issue (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model. Plus, if we manage to agree on a certain data representation until the final draft, we still can take this single consensus and promote it as the _only_ normative rendering. Cheers, Alexander Am 07.05.2009 um 18:56 schrieb Tim Bray:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Alexander Papaspyrou alexander.papaspyrou@tu-dortmund.de
+1 -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Alexander Papaspyrou Sent: 07 May 2009 18:13 To: Tim Bray Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Votes: XML vs. JSON vs. TXT Actually, while following the discussion for a while now, I feel that we have a strawman discussion here. In general, I agree to the general consensus that data representation should be simple. Really simple. Nothing is more frustrating than having to implement, maintain, and sell a complex beast to people outside (tm). However, we should remember to not mix up model and rendering. The question whether to use RESTful services with CSV, WS-Mayhem, or JSON over avian carriers is a question of _rendering_. I second the fact that this is an important issue to decide upon at some point. But unless we have agreed on the _model_, we haven't reached this point IMHO. The canonical way to cope with this issue (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model. Plus, if we manage to agree on a certain data representation until the final draft, we still can take this single consensus and promote it as the _only_ normative rendering. Cheers, Alexander Am 07.05.2009 um 18:56 schrieb Tim Bray:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Alexander Papaspyrou alexander.papaspyrou@tu-dortmund.de ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
+1 Quoting [Alexander Papaspyrou] (May 07 2009):
Actually, while following the discussion for a while now, I feel that we have a strawman discussion here.
In general, I agree to the general consensus that data representation should be simple. Really simple. Nothing is more frustrating than having to implement, maintain, and sell a complex beast to people outside (tm).
However, we should remember to not mix up model and rendering.
The question whether to use RESTful services with CSV, WS-Mayhem, or JSON over avian carriers is a question of _rendering_. I second the fact that this is an important issue to decide upon at some point. But unless we have agreed on the _model_, we haven't reached this point IMHO.
The canonical way to cope with this issue (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model.
Plus, if we manage to agree on a certain data representation until the final draft, we still can take this single consensus and promote it as the _only_ normative rendering.
Cheers, Alexander
Am 07.05.2009 um 18:56 schrieb Tim Bray:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
Correct me if I'm wrong but I understand that the service we're considering here is a RESTFul web-service, and further following a resource oriented architecture (see Ruby and Richardson's RESTFul Web Services book). In any generic RPC protocol, you need to define verbs and messages (methods and parameters). With RESTFul and ROA, since we're manipulating resources, the HTTP verbs (GET, PUT, POST, DELETE, etc) provide a pretty clear semantic. So what's left is the messages that are exchanged between the client and the server. Another observation is that, and this is based on my personal experience so feel free to contradict me, with 'big web-services' à la SOAP, the only way to reach interoperability between SOAP (and WSDL) tooling is to keep thing really simple (and stay away from the WS-* stuff as much as possible). And even armed with amazingly advanced tooling, the in order to reach interoperability, the messages (parameters) have to be simple... otherwise the cost of interoperability goes up... and fast. So we need to keep the messages simple. As a user of the service, I want to be able to paste in my browser the url to a resource and get something I understand, which means (X)HTML, with the right hyperlinks to the resource's neighbours and possible actions I can perform on these resources... right there in my browser! But if I'm a javascript, I probably want JSON or text. And if I'm Excel, I probably want CSV or text. And if I'm Python or Java, XML works. And if I don't like any of these, I grab the XML and transform it on the fly into something I like. I know, we're not in a design room in front of a white board... we're trying to define a standard, but I think it's important to set the scene in terms of implementation so that we know more or less what the real thing's going to look like. Getting back to your question... I think that to be successful, OCCI Web Services will have to embrace the reality of today's web, which is to support a number of content-types. And while I do realise that from a standardisation point-of-view I'm suggesting to raise the bar a little for v1.0, I don't think it's a problem. And the reason for that is 'simplicity'. So if we're finding that our life becomes difficult in specifying the messages in XML, JSON and TEXT, then we might want to re-evaluate our complexity level. Having said all that, we can start with one language and add others as we go along. But then the choice become which one's first. The argument against XML is that we can very quickly throw complexity which will bite us later when we try to express the same in a simpler language. On the other hand, we can start with TEXT or JSON to mitigate that risk, but then it's more work to transform. Perhaps to finish... and in good SCRUM fashion... why don't we let who ever has spare cycles produce a naive implementation of what we've got now, in whatever his/her prefer language, and we look at it together! If we don't like it, we throw it away and start again... but we'll have learned something. But this is only possible if we take small steps at a time, otherwise it hurts to throw too much away... and pain is not fun!! To conclude... I think we need to keep things simple... and if it's simple it won't be a problem to support a wide range of content- types. If we don't want to do them all right away, but want to keep the complexity beast at bay... we should then take small steps, have a look at a running system, make sure it implements the spec properly, realign and start again. Cheers, Meb PS. In doubt... write code ;-) On May 7, 2009, at 6:56 PM, Tim Bray wrote:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T

Gee I hope we aren't going down the RESTful path...that would be a waste for those of us that don't want that approach. Chas. Marc-Elian Bégin wrote:
Correct me if I'm wrong but I understand that the service we're considering here is a RESTFul web-service, and further following a resource oriented architecture (see Ruby and Richardson's RESTFul Web Services book).
In any generic RPC protocol, you need to define verbs and messages (methods and parameters). With RESTFul and ROA, since we're manipulating resources, the HTTP verbs (GET, PUT, POST, DELETE, etc) provide a pretty clear semantic. So what's left is the messages that are exchanged between the client and the server.
Another observation is that, and this is based on my personal experience so feel free to contradict me, with 'big web-services' à la SOAP, the only way to reach interoperability between SOAP (and WSDL) tooling is to keep thing really simple (and stay away from the WS-* stuff as much as possible). And even armed with amazingly advanced tooling, the in order to reach interoperability, the messages (parameters) have to be simple... otherwise the cost of interoperability goes up... and fast.
So we need to keep the messages simple.
As a user of the service, I want to be able to paste in my browser the url to a resource and get something I understand, which means (X)HTML, with the right hyperlinks to the resource's neighbours and possible actions I can perform on these resources... right there in my browser! But if I'm a javascript, I probably want JSON or text. And if I'm Excel, I probably want CSV or text. And if I'm Python or Java, XML works. And if I don't like any of these, I grab the XML and transform it on the fly into something I like.
I know, we're not in a design room in front of a white board... we're trying to define a standard, but I think it's important to set the scene in terms of implementation so that we know more or less what the real thing's going to look like.
Getting back to your question... I think that to be successful, OCCI Web Services will have to embrace the reality of today's web, which is to support a number of content-types. And while I do realise that from a standardisation point-of-view I'm suggesting to raise the bar a little for v1.0, I don't think it's a problem. And the reason for that is 'simplicity'. So if we're finding that our life becomes difficult in specifying the messages in XML, JSON and TEXT, then we might want to re-evaluate our complexity level.
Having said all that, we can start with one language and add others as we go along. But then the choice become which one's first. The argument against XML is that we can very quickly throw complexity which will bite us later when we try to express the same in a simpler language. On the other hand, we can start with TEXT or JSON to mitigate that risk, but then it's more work to transform.
Perhaps to finish... and in good SCRUM fashion... why don't we let who ever has spare cycles produce a naive implementation of what we've got now, in whatever his/her prefer language, and we look at it together! If we don't like it, we throw it away and start again... but we'll have learned something. But this is only possible if we take small steps at a time, otherwise it hurts to throw too much away... and pain is not fun!!
To conclude... I think we need to keep things simple... and if it's simple it won't be a problem to support a wide range of content- types. If we don't want to do them all right away, but want to keep the complexity beast at bay... we should then take small steps, have a look at a running system, make sure it implements the spec properly, realign and start again.
Cheers,
Meb PS. In doubt... write code ;-)
On May 7, 2009, at 6:56 PM, Tim Bray wrote:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Right... forgive me then. And I apologies if I'm wasting anybody's time. What's the approach you want? Meb On May 7, 2009, at 8:35 PM, CEW wrote:
Gee I hope we aren't going down the RESTful path...that would be a waste for those of us that don't want that approach.
Chas.
Marc-Elian Bégin wrote:
Correct me if I'm wrong but I understand that the service we're considering here is a RESTFul web-service, and further following a resource oriented architecture (see Ruby and Richardson's RESTFul Web Services book).
In any generic RPC protocol, you need to define verbs and messages (methods and parameters). With RESTFul and ROA, since we're manipulating resources, the HTTP verbs (GET, PUT, POST, DELETE, etc) provide a pretty clear semantic. So what's left is the messages that are exchanged between the client and the server.
Another observation is that, and this is based on my personal experience so feel free to contradict me, with 'big web-services' à la SOAP, the only way to reach interoperability between SOAP (and WSDL) tooling is to keep thing really simple (and stay away from the WS-* stuff as much as possible). And even armed with amazingly advanced tooling, the in order to reach interoperability, the messages (parameters) have to be simple... otherwise the cost of interoperability goes up... and fast.
So we need to keep the messages simple.
As a user of the service, I want to be able to paste in my browser the url to a resource and get something I understand, which means (X)HTML, with the right hyperlinks to the resource's neighbours and possible actions I can perform on these resources... right there in my browser! But if I'm a javascript, I probably want JSON or text. And if I'm Excel, I probably want CSV or text. And if I'm Python or Java, XML works. And if I don't like any of these, I grab the XML and transform it on the fly into something I like.
I know, we're not in a design room in front of a white board... we're trying to define a standard, but I think it's important to set the scene in terms of implementation so that we know more or less what the real thing's going to look like.
Getting back to your question... I think that to be successful, OCCI Web Services will have to embrace the reality of today's web, which is to support a number of content-types. And while I do realise that from a standardisation point-of-view I'm suggesting to raise the bar a little for v1.0, I don't think it's a problem. And the reason for that is 'simplicity'. So if we're finding that our life becomes difficult in specifying the messages in XML, JSON and TEXT, then we might want to re-evaluate our complexity level.
Having said all that, we can start with one language and add others as we go along. But then the choice become which one's first. The argument against XML is that we can very quickly throw complexity which will bite us later when we try to express the same in a simpler language. On the other hand, we can start with TEXT or JSON to mitigate that risk, but then it's more work to transform.
Perhaps to finish... and in good SCRUM fashion... why don't we let who ever has spare cycles produce a naive implementation of what we've got now, in whatever his/her prefer language, and we look at it together! If we don't like it, we throw it away and start again... but we'll have learned something. But this is only possible if we take small steps at a time, otherwise it hurts to throw too much away... and pain is not fun!!
To conclude... I think we need to keep things simple... and if it's simple it won't be a problem to support a wide range of content- types. If we don't want to do them all right away, but want to keep the complexity beast at bay... we should then take small steps, have a look at a running system, make sure it implements the spec properly, realign and start again.
Cheers,
Meb PS. In doubt... write code ;-)
On May 7, 2009, at 6:56 PM, Tim Bray wrote:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
A descriptive language and tools to translate it to whatever form the heart desires. C. Marc-Elian Bégin wrote:
Right... forgive me then. And I apologies if I'm wasting anybody's time.
What's the approach you want?
Meb
On May 7, 2009, at 8:35 PM, CEW wrote:
Gee I hope we aren't going down the RESTful path...that would be a waste for those of us that don't want that approach.
Chas.
Marc-Elian Bégin wrote:
Correct me if I'm wrong but I understand that the service we're considering here is a RESTFul web-service, and further following a resource oriented architecture (see Ruby and Richardson's RESTFul Web Services book).
In any generic RPC protocol, you need to define verbs and messages (methods and parameters). With RESTFul and ROA, since we're manipulating resources, the HTTP verbs (GET, PUT, POST, DELETE, etc) provide a pretty clear semantic. So what's left is the messages that are exchanged between the client and the server.
Another observation is that, and this is based on my personal experience so feel free to contradict me, with 'big web-services' à la SOAP, the only way to reach interoperability between SOAP (and WSDL) tooling is to keep thing really simple (and stay away from the WS-* stuff as much as possible). And even armed with amazingly advanced tooling, the in order to reach interoperability, the messages (parameters) have to be simple... otherwise the cost of interoperability goes up... and fast.
So we need to keep the messages simple.
As a user of the service, I want to be able to paste in my browser the url to a resource and get something I understand, which means (X)HTML, with the right hyperlinks to the resource's neighbours and possible actions I can perform on these resources... right there in my browser! But if I'm a javascript, I probably want JSON or text. And if I'm Excel, I probably want CSV or text. And if I'm Python or Java, XML works. And if I don't like any of these, I grab the XML and transform it on the fly into something I like.
I know, we're not in a design room in front of a white board... we're trying to define a standard, but I think it's important to set the scene in terms of implementation so that we know more or less what the real thing's going to look like.
Getting back to your question... I think that to be successful, OCCI Web Services will have to embrace the reality of today's web, which is to support a number of content-types. And while I do realise that from a standardisation point-of-view I'm suggesting to raise the bar a little for v1.0, I don't think it's a problem. And the reason for that is 'simplicity'. So if we're finding that our life becomes difficult in specifying the messages in XML, JSON and TEXT, then we might want to re-evaluate our complexity level.
Having said all that, we can start with one language and add others as we go along. But then the choice become which one's first. The argument against XML is that we can very quickly throw complexity which will bite us later when we try to express the same in a simpler language. On the other hand, we can start with TEXT or JSON to mitigate that risk, but then it's more work to transform.
Perhaps to finish... and in good SCRUM fashion... why don't we let who ever has spare cycles produce a naive implementation of what we've got now, in whatever his/her prefer language, and we look at it together! If we don't like it, we throw it away and start again... but we'll have learned something. But this is only possible if we take small steps at a time, otherwise it hurts to throw too much away... and pain is not fun!!
To conclude... I think we need to keep things simple... and if it's simple it won't be a problem to support a wide range of content- types. If we don't want to do them all right away, but want to keep the complexity beast at bay... we should then take small steps, have a look at a running system, make sure it implements the spec properly, realign and start again.
Cheers,
Meb PS. In doubt... write code ;-)
On May 7, 2009, at 6:56 PM, Tim Bray wrote:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
What 'tools' to you have in mind? Or can you point me to a previous thread if this has been discussed already? Meb On May 7, 2009, at 8:42 PM, CEW wrote:
A descriptive language and tools to translate it to whatever form the heart desires.
C. Marc-Elian Bégin wrote:
Right... forgive me then. And I apologies if I'm wasting anybody's time.
What's the approach you want?
Meb
On May 7, 2009, at 8:35 PM, CEW wrote:
Gee I hope we aren't going down the RESTful path...that would be a waste for those of us that don't want that approach.
Chas.
Marc-Elian Bégin wrote:
Correct me if I'm wrong but I understand that the service we're considering here is a RESTFul web-service, and further following a resource oriented architecture (see Ruby and Richardson's RESTFul Web Services book).
In any generic RPC protocol, you need to define verbs and messages (methods and parameters). With RESTFul and ROA, since we're manipulating resources, the HTTP verbs (GET, PUT, POST, DELETE, etc) provide a pretty clear semantic. So what's left is the messages that are exchanged between the client and the server.
Another observation is that, and this is based on my personal experience so feel free to contradict me, with 'big web-services' à la SOAP, the only way to reach interoperability between SOAP (and WSDL) tooling is to keep thing really simple (and stay away from the WS-* stuff as much as possible). And even armed with amazingly advanced tooling, the in order to reach interoperability, the messages (parameters) have to be simple... otherwise the cost of interoperability goes up... and fast.
So we need to keep the messages simple.
As a user of the service, I want to be able to paste in my browser the url to a resource and get something I understand, which means (X)HTML, with the right hyperlinks to the resource's neighbours and possible actions I can perform on these resources... right there in my browser! But if I'm a javascript, I probably want JSON or text. And if I'm Excel, I probably want CSV or text. And if I'm Python or Java, XML works. And if I don't like any of these, I grab the XML and transform it on the fly into something I like.
I know, we're not in a design room in front of a white board... we're trying to define a standard, but I think it's important to set the scene in terms of implementation so that we know more or less what the real thing's going to look like.
Getting back to your question... I think that to be successful, OCCI Web Services will have to embrace the reality of today's web, which is to support a number of content-types. And while I do realise that from a standardisation point-of-view I'm suggesting to raise the bar a little for v1.0, I don't think it's a problem. And the reason for that is 'simplicity'. So if we're finding that our life becomes difficult in specifying the messages in XML, JSON and TEXT, then we might want to re- evaluate our complexity level.
Having said all that, we can start with one language and add others as we go along. But then the choice become which one's first. The argument against XML is that we can very quickly throw complexity which will bite us later when we try to express the same in a simpler language. On the other hand, we can start with TEXT or JSON to mitigate that risk, but then it's more work to transform.
Perhaps to finish... and in good SCRUM fashion... why don't we let who ever has spare cycles produce a naive implementation of what we've got now, in whatever his/her prefer language, and we look at it together! If we don't like it, we throw it away and start again... but we'll have learned something. But this is only possible if we take small steps at a time, otherwise it hurts to throw too much away... and pain is not fun!!
To conclude... I think we need to keep things simple... and if it's simple it won't be a problem to support a wide range of content- types. If we don't want to do them all right away, but want to keep the complexity beast at bay... we should then take small steps, have a look at a running system, make sure it implements the spec properly, realign and start again.
Cheers,
Meb PS. In doubt... write code ;-)
On May 7, 2009, at 6:56 PM, Tim Bray wrote:
On May 7, 2009, at 1:12 AM, Marc-Elian Begin wrote:
I'm currently using restlet to build RESTFul web-services (very nice by the way) in Java. In such a framework, generating the requested format based on the requests's 'Content-Type' attribute is trivial (as long as the transformation is available). This means that my WS can talk (x)html when the user's a human (me), or XML or JSON or plain/ text.
So for me multi-format is mandatory...
Could you expand on you you get from "Generating multiple formats is easy for me based on my implementation tools" to "multi-format is mandatory"?
The intervening steps in the argument are not self-evident. -T
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg

JSON +1 Mark Masterson Enterprise architect, troublemaker CSC Financial Services EMEA | m: +49.172.6163412 | Internal blog: Schloss Masterson | Public blog: Process Perfection (http://jroller.com/MasterMark/) | mmasterson@csc.com | www.csc.com. CSC • This is a PRIVATE message. If you are not the intended recipient, please delete without copying and kindly advise us by e-mail of the mistake in delivery. NOTE: Regardless of content, this e-mail shall not operate to bind CSC to any order or other contract unless pursuant to explicit written agreement or government initiative expressly permitting the use of e-mail for such purpose ï CSC Computer Sciences Limited • Registered Office: Royal Pavilion, Wellesley Road, Aldershot, Hampshire, GU11 1PZ, UK • Registered in England No: 0963578 Richard Davies <richard.davies@e lastichosts.com> To Sent by: occi-wg@ogf.org occi-wg-bounces@o cc gf.org Subject [occi-wg] Votes: XML vs. JSON vs. 07/05/09 09:37 TXT I'd like to conduct a straw poll of members on this list. Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion. I'd like to conduct a poll of everyone on this list considering the 3 format options: - XML - JSON - TXT Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer. I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count. XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
JSON +1 Mark Masterson Enterprise architect, troublemaker CSC Financial Services EMEA | m: +49.172.6163412 | Internal blog: Schloss Masterson | Public blog: Process Perfection (http://jroller.com/MasterMark/) | mmasterson@csc.com | www.csc.com. CSC • This is a PRIVATE message. If you are not the intended recipient, please delete without copying and kindly advise us by e-mail of the mistake in delivery. NOTE: Regardless of content, this e-mail shall not operate to bind CSC to any order or other contract unless pursuant to explicit written agreement or government initiative expressly permitting the use of e-mail for such purpose ï CSC Computer Sciences Limited • Registered Office: Royal Pavilion, Wellesley Road, Aldershot, Hampshire, GU11 1PZ, UK • Registered in England No: 0963578 Richard Davies <richard.davies@e lastichosts.com> To Sent by: occi-wg@ogf.org occi-wg-bounces@o cc gf.org Subject [occi-wg] Votes: XML vs. JSON vs. 07/05/09 09:37 TXT I'd like to conduct a straw poll of members on this list. Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion. I'd like to conduct a poll of everyone on this list considering the 3 format options: - XML - JSON - TXT Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer. I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count. XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
JSON is fine with me and is a good target output format for the 1st rev of OCCI. However it's the model that is the important thing for me. In my view* there's a protocol, a data structure and an on-the-wire format. - Like Alexis said, the protocol is "a sequence of behaviours" - how the communication happens and is mediated. This is our set of verbs. This is, for example, can be mediated by REST. - The data structure is the model. This is how each noun is related to each other and what attribute is part of what noun. Models can be somewhat ephemeral, often expressed as programming language agnostic UML, BNF, XSD or indeed using a programming language e.g. Java, C etc (but then model portability is limited). - On-the-wire format is what we're currently talking about (JSON, XML, TXT). The raw output of our model. The latter 2 can be compared to a compiler - the model is the language and along with a frontend, it generates an AST (an object graph). With the object graph, it's easy to output binary machine code via a backend on whatever platform required. This is similar to if I was to code my model in say Java, instantiate an object graph and then render that graph using any serialiser. For example using XStream[1] I can output my model using XML and JSON (the machine code). So currently in my view there's consensus around a protocol - REST (hope that's fair to say); consensus forming on data structures; confusion on on-the-wire formats. If we don't finalise our data structures (model) we won't resolve the on-the-wire format quickly. Andy * Apologies if this is stating the obvious :-) [1] http://xstream.codehaus.org -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 07 May 2009 08:37 To: occi-wg@ogf.org Subject: [occi-wg] Votes: XML vs. JSON vs. TXT I'd like to conduct a straw poll of members on this list. Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion. I'd like to conduct a poll of everyone on this list considering the 3 format options: - XML - JSON - TXT Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer. I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count. XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.

+1 for JSON. I could do no better then what Andy has written eloquently. Cheers <k/> |-----Original Message----- |From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf |Of Edmonds, AndrewX |Sent: Thursday, May 07, 2009 2:08 AM |To: Richard Davies; occi-wg@ogf.org |Subject: Re: [occi-wg] Votes: XML vs. JSON vs. TXT | |JSON is fine with me and is a good target output format for the 1st rev |of OCCI. However it's the model that is the important thing for me. | |In my view* there's a protocol, a data structure and an on-the-wire |format. | | - Like Alexis said, the protocol is "a sequence of behaviours" - how |the communication happens and is mediated. This is our set of verbs. |This is, for example, can be mediated by REST. | - The data structure is the model. This is how each noun is related to |each other and what attribute is part of what noun. Models can be |somewhat ephemeral, often expressed as programming language agnostic |UML, BNF, XSD or indeed using a programming language e.g. Java, C etc |(but then model portability is limited). | - On-the-wire format is what we're currently talking about (JSON, XML, |TXT). The raw output of our model. | |The latter 2 can be compared to a compiler - the model is the language |and along with a frontend, it generates an AST (an object graph). With |the object graph, it's easy to output binary machine code via a backend |on whatever platform required. This is similar to if I was to code my |model in say Java, instantiate an object graph and then render that |graph using any serialiser. For example using XStream[1] I can output my |model using XML and JSON (the machine code). | |So currently in my view there's consensus around a protocol - REST (hope |that's fair to say); consensus forming on data structures; confusion on |on-the-wire formats. | |If we don't finalise our data structures (model) we won't resolve the |on-the-wire format quickly. | |Andy | |* Apologies if this is stating the obvious :-) |[1] http://xstream.codehaus.org | |-----Original Message----- |From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf |Of Richard Davies |Sent: 07 May 2009 08:37 |To: occi-wg@ogf.org |Subject: [occi-wg] Votes: XML vs. JSON vs. TXT | |I'd like to conduct a straw poll of members on this list. | |Tim Bray wrote: |> 4. Specific advice on multiple formats |> |> Don't do it. Pick one data format and stick with it. | |and that does make me question our (/my!) current proposal of multiple |formats with automatic conversion. | | |I'd like to conduct a poll of everyone on this list considering the 3 |format |options: | |- XML |- JSON |- TXT | |Please can people reply to this post casting a single vote for their |most |preferred of these three formats. I'll tabulate the responses. If |there's a |clear winner, we should probably go with it alone. If there's a split, |then |multiple format support as we're currently proposing may be the answer. | | |I'm going to start the counts with the clearly stated opinions which |I've |seen to date (listed below). If I'm misrepresenting anyone, then please |also reply and I'll change your vote in my count. | |XML: 3 |- Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009- |May/000430.html |- Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html |- William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009- |May/000396.html | |JSON: 7 |- Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009- |May/000405.html |- Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009- |May/000420.html |- Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html |- Randy Bias? (JSON listed first at |http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) |- Richard Davies http://www.ogf.org/pipermail/occi-wg/2009- |May/000409.html (split EH vote) |- Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009- |May/000411.html |- Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html | |TXT: 1 |- Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html |(split EH vote) |_______________________________________________ |occi-wg mailing list |occi-wg@ogf.org |http://www.ogf.org/mailman/listinfo/occi-wg |------------------------------------------------------------- |Intel Ireland Limited (Branch) |Collinstown Industrial Park, Leixlip, County Kildare, Ireland |Registered Number: E902934 | |This e-mail and any attachments may contain confidential material for |the sole use of the intended recipient(s). Any review or distribution |by others is strictly prohibited. If you are not the intended |recipient, please contact the sender and delete all copies. |_______________________________________________ |occi-wg mailing list |occi-wg@ogf.org |http://www.ogf.org/mailman/listinfo/occi-wg
Quoting [Richard Davies] (May 07 2009):
Date: Thu, 7 May 2009 08:37:29 +0100 From: Richard Davies <richard.davies@elastichosts.com> To: occi-wg@ogf.org Subject: [occi-wg] Votes: XML vs. JSON vs. TXT
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3 format options:
- XML - JSON - TXT
+1 for TXT, as that is most simple, flat, and easy to map to anything else. Well, you can screw up TXT, too, but we won't, right? ;-) As stated often on the list: IMHO the best approach would be to standardize the model, and to do bindings (API + Protocol) later. Maybe use two different mailing lists to disentangle the issues? A.
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
Personally I would take XML or even EBNF. The problem with text is that it is too unstructured and slight slips can lead to nightmares. I also +1 the model vs. bindings approach. We should do the former followed by the later. Chuck W Andre Merzky wrote:
Quoting [Richard Davies] (May 07 2009):
Date: Thu, 7 May 2009 08:37:29 +0100 From: Richard Davies <richard.davies@elastichosts.com> To: occi-wg@ogf.org Subject: [occi-wg] Votes: XML vs. JSON vs. TXT
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3 format options:
- XML - JSON - TXT
+1 for TXT, as that is most simple, flat, and easy to map to anything else. Well, you can screw up TXT, too, but we won't, right? ;-)
As stated often on the list: IMHO the best approach would be to standardize the model, and to do bindings (API + Protocol) later. Maybe use two different mailing lists to disentangle the issues?
A.
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Andre Merzky <andre@merzky.net> writes:
+1 for TXT, as that is most simple, flat, and easy to map to anything else. Well, you can screw up TXT, too, but we won't, right? ;-)
I'm standing back from the rest of the discussion as I've already advocated maximum format simplicity ad nauseam. However, I'll just quickly point out that the type of text format I have been proposing is a simple KEY VALUE KEY VALUE format, which can be read by a trivial shell fragment while read K V; do [...]; done Once it gets more complex than that, the sysadmin-friendliness starts to evaporate very quickly and you might as well use JSON. (For example, I remember another provider telling me that they'd offered CSV and nobody had used it. Frankly I'm not surprised given how much of a pain it is to parse correctly.) In our own API, our 'native' format looks like this and it has worked very well. The code is simple and clean, feedback from users has been very positive, and people really do write five line shell scripts to drive our infrastructure in the way they might script their own machines. This was my original design aim. Meanwhile, we're able to do admin across the cluster with shell one-liners, which would require separate tools if our API were more clumsy. We've structured our keys hierarchically using colons as a separator, so a text fragment ide:0:0 08c92dd5-70a0-4f51-83d2-835919d254df nic:0:dhcp 91.203.56.132 nic:0:model e1000 might be viewed as equivalent to the flat JSON hash { "ide:0:0": "08c92dd5-70a0-4f51-83d2-835919d254df", "nic:0:dhcp": "91.203.56.132", "nic:0:model": "e1000" } but equally as equivalent to the nested JSON hashes { "name": "TestServer", "cpu":4000, "mem":2048} { "ide": { 0: { 0: "08c92dd5-70a0-4f51-83d2-835919d254df" } }, "nic": { 0: { "dhcp": "91.203.56.132", "model": "e1000" } } } The use of whitespace to separate keys from values and newlines to separate records restricts keys (but not values) to contain no spaces, and both keys and values to have no leading whitespace or embedded newlines. In our environment, this isn't a problem, but you would need to add shell-friendly \ escaping to the mix if you wanted to allow demented keys and values in a whitespace-separated text format. Of course, if the standard goes with just JSON, it isn't a disaster from our point of view. We'll probably end up offering a small translation binary linking against libcurl to access it in the above flattened format. Seems a shame to force every casual user to compile and use a tool just to make the API usable from their command-line, though, when this isn't currently the case with our API. It'll be hard to sell something like this to end-users as an improvement, but definitely less hard-to-sell a little JSON-parsing binary (which I could write standalone) than if the tool also needs you to compile and link against cumbersome XML and Atom libraries (which I wouldn't even think of trying to do standalone). I guess my vote is there strongly anti-xml/atom, vaguely positive about json, and strongly positive about simple plaintext. Cheers, Chris.
I was thinking more about the text format today (still believing there is significant value in multiple formats and slightly more work for a small handful of implementors VA an infinite number of clients) and was thinking RFC 822 ala HTTP headers could be interesting too... No need to be anti-XML... if you want to start from text and code the translations by hand then you're most welcome to do so. Sam On 5/7/09, Chris Webb <chris.webb@elastichosts.com> wrote:
Andre Merzky <andre@merzky.net> writes:
+1 for TXT, as that is most simple, flat, and easy to map to anything else. Well, you can screw up TXT, too, but we won't, right? ;-)
I'm standing back from the rest of the discussion as I've already advocated maximum format simplicity ad nauseam. However, I'll just quickly point out that the type of text format I have been proposing is a simple
KEY VALUE KEY VALUE
format, which can be read by a trivial shell fragment
while read K V; do [...]; done
Once it gets more complex than that, the sysadmin-friendliness starts to evaporate very quickly and you might as well use JSON. (For example, I remember another provider telling me that they'd offered CSV and nobody had used it. Frankly I'm not surprised given how much of a pain it is to parse correctly.)
In our own API, our 'native' format looks like this and it has worked very well. The code is simple and clean, feedback from users has been very positive, and people really do write five line shell scripts to drive our infrastructure in the way they might script their own machines. This was my original design aim. Meanwhile, we're able to do admin across the cluster with shell one-liners, which would require separate tools if our API were more clumsy.
We've structured our keys hierarchically using colons as a separator, so a text fragment
ide:0:0 08c92dd5-70a0-4f51-83d2-835919d254df nic:0:dhcp 91.203.56.132 nic:0:model e1000
might be viewed as equivalent to the flat JSON hash
{ "ide:0:0": "08c92dd5-70a0-4f51-83d2-835919d254df", "nic:0:dhcp": "91.203.56.132", "nic:0:model": "e1000" }
but equally as equivalent to the nested JSON hashes
{ "name": "TestServer", "cpu":4000, "mem":2048}
{ "ide": { 0: { 0: "08c92dd5-70a0-4f51-83d2-835919d254df" } }, "nic": { 0: { "dhcp": "91.203.56.132", "model": "e1000" } } }
The use of whitespace to separate keys from values and newlines to separate records restricts keys (but not values) to contain no spaces, and both keys and values to have no leading whitespace or embedded newlines. In our environment, this isn't a problem, but you would need to add shell-friendly \ escaping to the mix if you wanted to allow demented keys and values in a whitespace-separated text format.
Of course, if the standard goes with just JSON, it isn't a disaster from our point of view. We'll probably end up offering a small translation binary linking against libcurl to access it in the above flattened format. Seems a shame to force every casual user to compile and use a tool just to make the API usable from their command-line, though, when this isn't currently the case with our API.
It'll be hard to sell something like this to end-users as an improvement, but definitely less hard-to-sell a little JSON-parsing binary (which I could write standalone) than if the tool also needs you to compile and link against cumbersome XML and Atom libraries (which I wouldn't even think of trying to do standalone). I guess my vote is there strongly anti-xml/atom, vaguely positive about json, and strongly positive about simple plaintext.
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
I was thinking more about the text format today (still believing there is significant value in multiple formats and slightly more work for a small handful of implementors VA an infinite number of clients) and was thinking RFC 822 ala HTTP headers could be interesting too... No need to be anti-XML... if you want to start from text and code the translations by hand then you're most welcome to do so. Sam On 5/7/09, Chris Webb <chris.webb@elastichosts.com> wrote:
Andre Merzky <andre@merzky.net> writes:
+1 for TXT, as that is most simple, flat, and easy to map to anything else. Well, you can screw up TXT, too, but we won't, right? ;-)
I'm standing back from the rest of the discussion as I've already advocated maximum format simplicity ad nauseam. However, I'll just quickly point out that the type of text format I have been proposing is a simple
KEY VALUE KEY VALUE
format, which can be read by a trivial shell fragment
while read K V; do [...]; done
Once it gets more complex than that, the sysadmin-friendliness starts to evaporate very quickly and you might as well use JSON. (For example, I remember another provider telling me that they'd offered CSV and nobody had used it. Frankly I'm not surprised given how much of a pain it is to parse correctly.)
In our own API, our 'native' format looks like this and it has worked very well. The code is simple and clean, feedback from users has been very positive, and people really do write five line shell scripts to drive our infrastructure in the way they might script their own machines. This was my original design aim. Meanwhile, we're able to do admin across the cluster with shell one-liners, which would require separate tools if our API were more clumsy.
We've structured our keys hierarchically using colons as a separator, so a text fragment
ide:0:0 08c92dd5-70a0-4f51-83d2-835919d254df nic:0:dhcp 91.203.56.132 nic:0:model e1000
might be viewed as equivalent to the flat JSON hash
{ "ide:0:0": "08c92dd5-70a0-4f51-83d2-835919d254df", "nic:0:dhcp": "91.203.56.132", "nic:0:model": "e1000" }
but equally as equivalent to the nested JSON hashes
{ "name": "TestServer", "cpu":4000, "mem":2048}
{ "ide": { 0: { 0: "08c92dd5-70a0-4f51-83d2-835919d254df" } }, "nic": { 0: { "dhcp": "91.203.56.132", "model": "e1000" } } }
The use of whitespace to separate keys from values and newlines to separate records restricts keys (but not values) to contain no spaces, and both keys and values to have no leading whitespace or embedded newlines. In our environment, this isn't a problem, but you would need to add shell-friendly \ escaping to the mix if you wanted to allow demented keys and values in a whitespace-separated text format.
Of course, if the standard goes with just JSON, it isn't a disaster from our point of view. We'll probably end up offering a small translation binary linking against libcurl to access it in the above flattened format. Seems a shame to force every casual user to compile and use a tool just to make the API usable from their command-line, though, when this isn't currently the case with our API.
It'll be hard to sell something like this to end-users as an improvement, but definitely less hard-to-sell a little JSON-parsing binary (which I could write standalone) than if the tool also needs you to compile and link against cumbersome XML and Atom libraries (which I wouldn't even think of trying to do standalone). I guess my vote is there strongly anti-xml/atom, vaguely positive about json, and strongly positive about simple plaintext.
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
+1 XMLish I really like to see "model +rendering" -gary On Thu, May 7, 2009 at 12:37 AM, Richard Davies < richard.davies@elastichosts.com> wrote:
I'd like to conduct a straw poll of members on this list.
Tim Bray wrote:
4. Specific advice on multiple formats
Don't do it. Pick one data format and stick with it.
and that does make me question our (/my!) current proposal of multiple formats with automatic conversion.
I'd like to conduct a poll of everyone on this list considering the 3 format options:
- XML - JSON - TXT
Please can people reply to this post casting a single vote for their most preferred of these three formats. I'll tabulate the responses. If there's a clear winner, we should probably go with it alone. If there's a split, then multiple format support as we're currently proposing may be the answer.
I'm going to start the counts with the clearly stated opinions which I've seen to date (listed below). If I'm misrepresenting anyone, then please also reply and I'll change your vote in my count.
XML: 3 - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
JSON: 7 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds? http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html(split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
TXT: 1 - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html(split EH vote) _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
I am confused about this voting without further basis. Good design is not a democracy. Ben
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
I am confused about this voting without further basis. Good design is not a democracy.
This is something we certainly can agree on... in fact "democracy" tends to play a large role in the worst of specifications. Loose consensus and running code is where it's at... though voting to appove a completed specification can be a useful step. Sam on iPhone Sam
On Thu, May 7, 2009 at 3:22 PM, Sam Johnston <samj@samj.net> wrote:
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
I am confused about this voting without further basis. Good design is not a democracy.
This is something we certainly can agree on... in fact "democracy" tends to play a large role in the worst of specifications.
Absolutely! One need only look at XML, SOAP, WS-*, and company for outstanding examples of that effect in action. Ben
The list has thankfully gone quiet, so I've recounted the votes since my previous post. We are now at: 10 JSON, 5 XML, 2 TXT I don't consider this as a vote for a decision, but do think it has drawn out a lot of opinions and shown the lay of the land more clearly - in the light of the votes, the only two viable options are: - Single-format: JSON - Multi-format: JSON + XML + ?TXT The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format). I see three conclusions going forward: 1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON. There is still work here - e.g. verbs and attributes on networks have not been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks. Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html 2) The JSON vs. XML debate is not just about angle-brackets vs. curly-brackets. Amongst the XML supporters, I have seen little opposition to a GData/Atom meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired the IETF Atom working group, felt it was the wrong choice, but then he doesn't support using XML at all in this context] However, many(/all?) of the JSON supporters seem to want a lighter meta-model around the nouns/verbs/attributes. For instance, they would probably prefer fixed actuator URLs to passing these in the feed, and would likely transmit flatter hashes of noun attributes rather than following Atom conventions the structure of links, attributes, etc. within an object. Thanks to Ben Black, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html My conclusion from this is that we should not develop the JSON rendering in terms of an XSLT transform from the XML rendering, and should not go for "GData-JSON". We will need these automatic transforms eventually, but we should develop the JSON rendering in its own right, thinking about what works well for JSON, and then later work out how we'll auto transform back and forth. Do the 10 JSON supporters agree with this, or have I misjudged it and there is actually strong support for GData-JSON? Myself and Chris would be happy to lead developing the JSON rendering it its own right if people agree with my statements above and hence that it does need independent development (from the same set of nouns/verb/attributes and semantics). 3) I suggest we(/I!) stop discussing TXT for now. If we go multi-format then we should probably have it, but Chris has demonstrated how it can be trivially transformed back and forth from JSON. http://www.ogf.org/pipermail/occi-wg/2009-May/000451.html Cheers, Richard. ========================================== JSON: 10 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009-May/000455.html - Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009-May/000440.html - Michael Richardson (private mail to me) - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html XML: 5 - Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html TXT: 2 - Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) Single: 3 - Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009-May/000457.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html - Richard Davies (revised in light of Tim Bray's comments) Multi: 3 - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html - Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009-May/000439.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html
Richard, Thanks for the summary. a) As a JSON proponent, agree on your observation that we should do JSON rendering on it's own right. If you guys take the lead, would be happy to pitch-in, (as much as time allows of course). b) I support the single format than multi. Cheers <k/> |-----Original Message----- |From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf |Of Richard Davies |Sent: Friday, May 08, 2009 8:42 AM |To: occi-wg@ogf.org |Subject: Re: [occi-wg] Voting result | |The list has thankfully gone quiet, so I've recounted the votes since my |previous post. We are now at: | | 10 JSON, 5 XML, 2 TXT | |I don't consider this as a vote for a decision, but do think it has |drawn |out a lot of opinions and shown the lay of the land more clearly - in |the |light of the votes, the only two viable options are: | |- Single-format: JSON |- Multi-format: JSON + XML + ?TXT | |The list has also been fairly evenly split on whether multiple format |support makes sense or not (independent of the choice of the single |format). | | |I see three conclusions going forward: | |1) Continue our specification in terms of the model (nouns, verbs, |attributes, semantics of these, how these are linked together) with both |JSON and XML renderings of this being explored on the wiki. We can |decide |later if we run with both or just JSON. | |There is still work here - e.g. verbs and attributes on networks have |not |been specified, nor have we agreed fully the _model_ of how we link |servers |to storage and networks. | |Thanks to Alexander Papaspyrou, Andy Edmonds: |http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html |http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html | | |2) The JSON vs. XML debate is not just about angle-brackets vs. |curly-brackets. | |Amongst the XML supporters, I have seen little opposition to a |GData/Atom |meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired |the |IETF Atom working group, felt it was the wrong choice, but then he |doesn't |support using XML at all in this context] | |However, many(/all?) of the JSON supporters seem to want a lighter |meta-model around the nouns/verbs/attributes. For instance, they would |probably prefer fixed actuator URLs to passing these in the feed, and |would |likely transmit flatter hashes of noun attributes rather than following |Atom |conventions the structure of links, attributes, etc. within an object. | |Thanks to Ben Black, Andy Edmonds: |http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html |http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html | |My conclusion from this is that we should not develop the JSON rendering |in |terms of an XSLT transform from the XML rendering, and should not go for |"GData-JSON". We will need these automatic transforms eventually, but we |should develop the JSON rendering in its own right, thinking about what |works well for JSON, and then later work out how we'll auto transform |back |and forth. | |Do the 10 JSON supporters agree with this, or have I misjudged it and |there |is actually strong support for GData-JSON? | |Myself and Chris would be happy to lead developing the JSON rendering it |its |own right if people agree with my statements above and hence that it |does |need independent development (from the same set of nouns/verb/attributes |and |semantics). | | |3) I suggest we(/I!) stop discussing TXT for now. If we go multi-format |then |we should probably have it, but Chris has demonstrated how it can be |trivially transformed back and forth from JSON. | |http://www.ogf.org/pipermail/occi-wg/2009-May/000451.html | | |Cheers, | |Richard. | |========================================== | |JSON: 10 |- Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009- |May/000405.html |- Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html |- Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html |- Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009- |May/000455.html |- Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009- |May/000440.html |- Michael Richardson (private mail to me) |- Randy Bias? (JSON listed first at |http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) |- Richard Davies http://www.ogf.org/pipermail/occi-wg/2009- |May/000409.html (split EH vote) |- Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009- |May/000411.html |- Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html | |XML: 5 |- Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html |- Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html |- Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009- |May/000430.html |- Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html |- William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009- |May/000396.html | |TXT: 2 |- Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html |- Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html |(split EH vote) | |Single: 3 |- Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009- |May/000457.html |- Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html |- Richard Davies (revised in light of Tim Bray's comments) | |Multi: 3 |- Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html |- Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009- |May/000439.html |- Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html |_______________________________________________ |occi-wg mailing list |occi-wg@ogf.org |http://www.ogf.org/mailman/listinfo/occi-wg

I ditto..Richard's JSON, and single format rather than multi On Fri, May 8, 2009 at 10:35 AM, Krishna Sankar (ksankar) <ksankar@cisco.com
wrote:
Richard, Thanks for the summary.
a) As a JSON proponent, agree on your observation that we should do JSON rendering on it's own right. If you guys take the lead, would be happy to pitch-in, (as much as time allows of course). b) I support the single format than multi.
Cheers <k/>
|-----Original Message----- |From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf |Of Richard Davies |Sent: Friday, May 08, 2009 8:42 AM |To: occi-wg@ogf.org |Subject: Re: [occi-wg] Voting result | |The list has thankfully gone quiet, so I've recounted the votes since my |previous post. We are now at: | | 10 JSON, 5 XML, 2 TXT | |I don't consider this as a vote for a decision, but do think it has |drawn |out a lot of opinions and shown the lay of the land more clearly - in |the |light of the votes, the only two viable options are: | |- Single-format: JSON |- Multi-format: JSON + XML + ?TXT | |The list has also been fairly evenly split on whether multiple format |support makes sense or not (independent of the choice of the single |format). | | |I see three conclusions going forward: | |1) Continue our specification in terms of the model (nouns, verbs, |attributes, semantics of these, how these are linked together) with both |JSON and XML renderings of this being explored on the wiki. We can |decide |later if we run with both or just JSON. | |There is still work here - e.g. verbs and attributes on networks have |not |been specified, nor have we agreed fully the _model_ of how we link |servers |to storage and networks. | |Thanks to Alexander Papaspyrou, Andy Edmonds: |http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html |http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html | | |2) The JSON vs. XML debate is not just about angle-brackets vs. |curly-brackets. | |Amongst the XML supporters, I have seen little opposition to a |GData/Atom |meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired |the |IETF Atom working group, felt it was the wrong choice, but then he |doesn't |support using XML at all in this context] | |However, many(/all?) of the JSON supporters seem to want a lighter |meta-model around the nouns/verbs/attributes. For instance, they would |probably prefer fixed actuator URLs to passing these in the feed, and |would |likely transmit flatter hashes of noun attributes rather than following |Atom |conventions the structure of links, attributes, etc. within an object. | |Thanks to Ben Black, Andy Edmonds: |http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html |http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html | |My conclusion from this is that we should not develop the JSON rendering |in |terms of an XSLT transform from the XML rendering, and should not go for |"GData-JSON". We will need these automatic transforms eventually, but we |should develop the JSON rendering in its own right, thinking about what |works well for JSON, and then later work out how we'll auto transform |back |and forth. | |Do the 10 JSON supporters agree with this, or have I misjudged it and |there |is actually strong support for GData-JSON? | |Myself and Chris would be happy to lead developing the JSON rendering it |its |own right if people agree with my statements above and hence that it |does |need independent development (from the same set of nouns/verb/attributes |and |semantics). | | |3) I suggest we(/I!) stop discussing TXT for now. If we go multi-format |then |we should probably have it, but Chris has demonstrated how it can be |trivially transformed back and forth from JSON. | |http://www.ogf.org/pipermail/occi-wg/2009-May/000451.html | | |Cheers, | |Richard. | |========================================== | |JSON: 10 |- Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009- |May/000405.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000405.html> |- Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html |- Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html |- Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009- |May/000455.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000455.html> |- Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009- |May/000440.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000440.html> |- Michael Richardson (private mail to me) |- Randy Bias? (JSON listed first at |http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) |- Richard Davies http://www.ogf.org/pipermail/occi-wg/2009- |May/000409.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000409.html>(split EH vote) |- Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009- |May/000411.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000411.html> |- Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html | |XML: 5 |- Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html |- Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html |- Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009- |May/000430.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000430.html> |- Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html |- William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009- |May/000396.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000396.html> | |TXT: 2 |- Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html |- Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html |(split EH vote) | |Single: 3 |- Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009- |May/000457.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000457.html> |- Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html |- Richard Davies (revised in light of Tim Bray's comments) | |Multi: 3 |- Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html |- Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009- |May/000439.html<http://www.ogf.org/pipermail/occi-wg/2009-%0A%7CMay/000439.html> |- Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html |_______________________________________________ |occi-wg mailing list |occi-wg@ogf.org |http://www.ogf.org/mailman/listinfo/occi-wg _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- ========== Colleen Smith email: colleen1@gmail.com
Richard, Thanks for taking the time to gather the information and summarise it. On Fri, May 8, 2009 at 5:41 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
The list has thankfully gone quiet, so I've recounted the votes since my previous post. We are now at:
10 JSON, 5 XML, 2 TXT
This isn't even a loose consensus, especially if you drop the "me too" votes lacking arguments and the curious pointer to the GoGrid API which supports<http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call#Output_Formats>all of JSON, XML *and* TXT. I'm still far from convinced that JSON meets the minimum requirements to be in the running in the first place and nobody has addressed this point except to tell me to go back to square one and formally define them. Even the JSON junkies concede <http://www.json.org/xml.html> that while "*XML documents can contain any imaginable data type*", "*JSON does not have a <[CDATA[]]> feature*" so unless we want to contribute to the creation of a circus of cloud standards rather than provide the coherence of a loose framework on which to build, this point at the very least needs to be addressed. We all agree that anything but the most basic specification of compute, storage and network resources is out of scope, but we then give no option but to have clients talk multiple APIs developed by multiple SSO's (almost certainly with completely different formats and structures). Am I the only one who sees a complete and utter clusterf--k in the making (think WS-* redux JSON edition)? I don't consider this as a vote for a decision, but do think it has drawn
out a lot of opinions and shown the lay of the land more clearly - in the light of the votes, the only two viable options are:
Definitely, the arguments have been enlightening but there are still some big knowledge gaps. Mechanical transformations are another point that the JSON crowd have been totally silent about, likely because there is no solution that doesn't involve delving into the details of programming (something which is strictly out of bounds). It's worth mentioning that I well appreciate the advantages of JSON but this is about choosing the right tool for the job - XML may be a sledgehammer but everyone's got one and you can't drive a nail with a screwdriver. - Single-format: JSON
- Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic). Trim the formats and you trim the audience and with it the potential for success. I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work. There is still work here - e.g. verbs and attributes on networks have not
been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at). 2) The JSON vs. XML debate is not just about angle-brackets vs.
curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
Amongst the XML supporters, I have seen little opposition to a GData/Atom meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired the IETF Atom working group, felt it was the wrong choice, but then he doesn't support using XML at all in this context]
I'm less and less convinced that we're trying to solve the same problem here... the public cloud interfaces are extremely light (too light in places) but functional while the private cloud stuff is overkill. There is middle ground and we need to find it if hybrid clouds are to be a reality.
However, many(/all?) of the JSON supporters seem to want a lighter meta-model around the nouns/verbs/attributes. For instance, they would probably prefer fixed actuator URLs to passing these in the feed, and would likely transmit flatter hashes of noun attributes rather than following Atom conventions the structure of links, attributes, etc. within an object.
Thanks to Ben Black, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html
My conclusion from this is that we should not develop the JSON rendering in terms of an XSLT transform from the XML rendering, and should not go for "GData-JSON". We will need these automatic transforms eventually, but we should develop the JSON rendering in its own right, thinking about what works well for JSON, and then later work out how we'll auto transform back and forth.
See above re "later".
Do the 10 JSON supporters agree with this, or have I misjudged it and there is actually strong support for GData-JSON?
By GData-JSON you of course mean a generic XML to JSON<http://www.bramstein.com/projects/xsltjson/>transformation which results in functional but ugly <http://code.google.com/apis/gdata/json.html> JSON. I'm unconvinced that a "pretty" protocol is a requirement provided it is still accessible/approachable - this works for Google so it will work for us, and it's trivial while your proposed alternative is very far from it. That said, work on Atom to JSON<http://www.ibm.com/developerworks/library/x-atom2json.html>has already been done and an " application/atom+json<http://www.intertwingly.net/blog/2007/01/15/application-atom-json>" RFC would be hugely beneficial for many audiences. I'd suggest JSON be a convenience primarly for web developers and that a generic XML to JSON transform be used while an Atom to JSON transform is developed (that's something I'd happily to contribute to separately).
Myself and Chris would be happy to lead developing the JSON rendering it its own right if people agree with my statements above and hence that it does need independent development (from the same set of nouns/verb/attributes and semantics).
That's all well and good but anyone can write a "rendering" - it's the "renderer" that's hard work. If you and Chris are volunteering to get us to the point we are already with XML, by Wednesday, then we've got something to talk about. The "ugly" JSON is just fine for developers and most importantly, it works with whatever resource you throw at it (be it a Gmail "contact" or a "compute" resource). There is enormous potential value in giving Google an short path to standardisation (for Google, their competitors and most importantly, cloud computing users). This will become increasingly important/apparent as people start to realise that infrastructure is boring "keeping the lights on" work and the true value is further up the stack.
3) I suggest we(/I!) stop discussing TXT for now. If we go multi-format then we should probably have it, but Chris has demonstrated how it can be trivially transformed back and forth from JSON.
I agree there's a valid use case for TXT (sysadmins, cron jobs, etc.) and I've demonstrated<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>that there's an extremely compelling argument for [X]HTML too. I can see both CSV and PDF transforms being useful for reporting as well. The point is that there are many different audiences to satisfy and we can trivially satisfy them all, quickly, if we stick with lightweight XML. Move to JSON and there's serious doubt as to whether we'll even be able to deliver on our charter (e.g. playing nice with others). Something you haven't covered in your summary is the strong consensus to keep the model and protocol separate. That's something that I for one would like to see more of going forward and I specifically don't want to see the model spilling over into the protocol if it will limit its potential application and complicate/specialise mechanical transformation. Sam Cheers,
Richard.
==========================================
JSON: 10 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009-May/000455.html - Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009-May/000440.html - Michael Richardson (private mail to me) - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html(split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
XML: 5 - Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
TXT: 2 - Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html(split EH vote)
Single: 3 - Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009-May/000457.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html - Richard Davies (revised in light of Tim Bray's comments)
Multi: 3 - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html - Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009-May/000439.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Fri, May 8, 2009 at 12:21 PM, Sam Johnston <samj@samj.net> wrote:
- Single-format: JSON
- Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic).
I said the exact opposite: multiple formats creates complexity (either by requiring everyone support all formats or by allowing mutually incompatible yet compliant implementations) with little benefit.
Trim the formats and you trim the audience and with it the potential for success. I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
This approach does not address my concerns so much as amplify them.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work.
Arbitrary deadlines based on having to give a presentation probably not the best way to produce quality solutions.
There is still work here - e.g. verbs and attributes on networks have not
been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at).
2) The JSON vs. XML debate is not just about angle-brackets vs.
curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
What you have convinced me of is that this is your clubhouse and the rest of us mere ornament so OCCI can appear to be a legitimate "consensus-based standards group". Not my cup of tea. Ben
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
On Fri, May 8, 2009 at 12:21 PM, Sam Johnston <samj@samj.net> wrote:
- Single-format: JSON
- Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic).
I said the exact opposite: multiple formats creates complexity (either by requiring everyone support all formats or by allowing mutually incompatible yet compliant implementations) with little benefit.
I said that by NOT requiring people to implement anything but the primary format we can resolve your concerns. You have not demonstrated that there is little benefit and many of us had said that there is. The results of this straw poll demonstrate that clearly.
Trim the formats and you trim the audience and with it the potential for success. I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
This approach does not address my concerns so much as amplify them.
How so? If there is one format for interoperability and others for convenience then we have the best of both worlds - the requisite transforms need not even be part of the spec, nor even developed by us.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work.
Arbitrary deadlines based on having to give a presentation probably not the best way to produce quality solutions.
The deadline was decided pre-charter and appears in the launch release. It's inflexible.
There is still work here - e.g. verbs and attributes on networks have not
been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at).
2) The JSON vs. XML debate is not just about angle-brackets vs.
curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
What you have convinced me of is that this is your clubhouse and the rest of us mere ornament so OCCI can appear to be a legitimate "consensus-based standards group". Not my cup of tea.
Ironically my insistence on XML is in order to AVOID forcing my opinion on others... I'd have thought that was pretty clear from each of my arguments. I don't think anyone is in a position to say how cloud computing will evolve and suggesting that we know what tomorrow's datacenter will look like is extremely presumptuous, irrespective of previous accomplishments. I note that my various serious/showstopper concerns about JSON in this context remain unanswered. Sam on iPhone
OGF 25 is the presentation of a *draft*. Anything that we have not agreed on, should not be presented at OGF 25 except clearly marked as 'draft and not agreed upon yet'. There is no point in presenting anything at OGF 25 that will not be supported by more than one implementation. OCCI is a plural venture. If in doubt, leave it out. I am in favour of the notion of a 'primary format for interop.' at this stage meaning prior to OGF 25. If requirements force us to go against Tim's advice to have one format, then we should assess them in a clear way, between OGF 25 and OGF 26. (I don't see how we can support multiple formats *now* and then easily simplify down to one format. On the other hand, it is quite easy to go from one format to many.) I'd like to see consensus around the notion of one primary format for interop. for this draft stage and until we are forced to change that by clear user requirements. ---- Personally I have yet to see a showstopper concern against JSON, so I am still +1 on JSON over XML on grounds of simplicity and low costs of support. Sam, you say there are some but it would really help if you could lay them out in a list so that we can look at them one by one. alexis On Fri, May 8, 2009 at 9:08 PM, Sam Johnston <samj@samj.net> wrote:
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
On Fri, May 8, 2009 at 12:21 PM, Sam Johnston <samj@samj.net> wrote:
- Single-format: JSON
- Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic).
I said the exact opposite: multiple formats creates complexity (either by requiring everyone support all formats or by allowing mutually incompatible yet compliant implementations) with little benefit.
I said that by NOT requiring people to implement anything but the primary format we can resolve your concerns. You have not demonstrated that there is little benefit and many of us had said that there is. The results of this straw poll demonstrate that clearly.
Trim the formats and you trim the audience and with it the potential for success. I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
This approach does not address my concerns so much as amplify them.
How so? If there is one format for interoperability and others for convenience then we have the best of both worlds - the requisite transforms need not even be part of the spec, nor even developed by us.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work.
Arbitrary deadlines based on having to give a presentation probably not the best way to produce quality solutions.
The deadline was decided pre-charter and appears in the launch release. It's inflexible.
There is still work here - e.g. verbs and attributes on networks have not
been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at).
2) The JSON vs. XML debate is not just about angle-brackets vs.
curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
What you have convinced me of is that this is your clubhouse and the rest of us mere ornament so OCCI can appear to be a legitimate "consensus-based standards group". Not my cup of tea.
Ironically my insistence on XML is in order to AVOID forcing my opinion on others... I'd have thought that was pretty clear from each of my arguments.
I don't think anyone is in a position to say how cloud computing will evolve and suggesting that we know what tomorrow's datacenter will look like is extremely presumptuous, irrespective of previous accomplishments.
I note that my various serious/showstopper concerns about JSON in this context remain unanswered.
Sam on iPhone _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Alexis, On Fri, May 8, 2009 at 10:31 PM, Alexis Richardson < alexis.richardson@gmail.com> wrote:
OGF 25 is the presentation of a *draft*.
Anything that we have not agreed on, should not be presented at OGF 25 except clearly marked as 'draft and not agreed upon yet'. There is no point in presenting anything at OGF 25 that will not be supported by more than one implementation. OCCI is a plural venture. If in doubt, leave it out.
A "draft" is not an "implementable draft" if it's missing details like the core format. If we fail to deliver we'll be seen as just another talking shop releasing hot air into the cloud space by the many critics of (quite possibly premature) cloud standardisation efforts. That's not to say we should rush it but if there's a chance we can deliver on our promises then we *definitely* should. I am in favour of the notion of a 'primary format for interop.' at
this stage meaning prior to OGF 25. If requirements force us to go against Tim's advice to have one format, then we should assess them in a clear way, between OGF 25 and OGF 26. (I don't see how we can support multiple formats *now* and then easily simplify down to one format. On the other hand, it is quite easy to go from one format to many.)
I'd like to see consensus around the notion of one primary format for interop. for this draft stage and until we are forced to change that by clear user requirements.
Agreed, with the caveat that the suggestion was a "primary format for interop" AND alternative formats for convenience... you may be ok with insisting others use your $PREFERRED_FORMAT but I'm not. What I don't get is why, when the JSON junkies can have their cake, they insist on forcing the rest of us to eat it too (all in the name of simplicity no less, while actually creating complexity for those of us with anything but the most rudimentary of requirements).
Personally I have yet to see a showstopper concern against JSON, so I am still +1 on JSON over XML on grounds of simplicity and low costs of support. Sam, you say there are some but it would really help if you could lay them out in a list so that we can look at them one by one.
Let's see answers to the transformation and interoperability [with other standards] requirements first eh, then we can start talking about signatures, encryption, caching, extension, validation, etc. etc. etc. Sam On Fri, May 8, 2009 at 9:08 PM, Sam Johnston <samj@samj.net> wrote:
On 5/8/09, Benjamin Black <b@b3k.us> wrote:
On Fri, May 8, 2009 at 12:21 PM, Sam Johnston <samj@samj.net> wrote:
- Single-format: JSON
- Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic).
I said the exact opposite: multiple formats creates complexity (either by requiring everyone support all formats or by allowing mutually incompatible yet compliant implementations) with little benefit.
I said that by NOT requiring people to implement anything but the primary format we can resolve your concerns. You have not demonstrated that there is little benefit and many of us had said that there is. The results of this straw poll demonstrate that clearly.
Trim the formats and you trim the audience and with it the potential for success. I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
This approach does not address my concerns so much as amplify them.
How so? If there is one format for interoperability and others for convenience then we have the best of both worlds - the requisite transforms need not even be part of the spec, nor even developed by us.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with
both
JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work.
Arbitrary deadlines based on having to give a presentation probably not the best way to produce quality solutions.
The deadline was decided pre-charter and appears in the launch release. It's inflexible.
There is still work here - e.g. verbs and attributes on networks have not
been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at).
2) The JSON vs. XML debate is not just about angle-brackets vs.
curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
What you have convinced me of is that this is your clubhouse and the rest of us mere ornament so OCCI can appear to be a legitimate "consensus-based standards group". Not my cup of tea.
Ironically my insistence on XML is in order to AVOID forcing my opinion on others... I'd have thought that was pretty clear from each of my arguments.
I don't think anyone is in a position to say how cloud computing will evolve and suggesting that we know what tomorrow's datacenter will look like is extremely presumptuous, irrespective of previous accomplishments.
I note that my various serious/showstopper concerns about JSON in this context remain unanswered.
Sam on iPhone _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On May 8, 2009, at 12:21 PM, Sam Johnston wrote:
I'm still far from convinced that JSON meets the minimum requirements to be in the running in the first place and nobody has addressed this point except to tell me to go back to square one and formally define them. Even the JSON junkies concede that while "XML documents can contain any imaginable data type", "JSON does not have a <[CDATA[]]> feature" so unless we want to contribute to the creation of a circus of cloud standards rather than provide the coherence of a loose framework on which to build, this point at the very least needs to be addressed.
What on earth does CDATA have to do with anything? JSON can carry arbitrary textual payloads without any extra effort. Oh, here's a dirty secret: both XML and JSON are lousy "wrapper" formats. If you have different kinds of things, you're usually better off letting them stand alone and link back and forth; that hypertext thing. I have not been to the mat with the OCCI use cases so I'm not going to argue that they contain things that can't be done in JSON. We didn't find any in our use-cases, but that may not be relevant here. The disconnect here that's fascinating, looking in from outside, is between the people who feel that having multiple message formats is a problem and those who feel it's essential.
Definitely, the arguments have been enlightening but there are still some big knowledge gaps. Mechanical transformations are another point that the JSON crowd have been totally silent about, likely because there is no solution that doesn't involve delving into the details of programming (something which is strictly out of bounds).
One of the reasons that us single-data-format people feel that way is that it moves the transformation problem out of scope. Less work is good. I guarantee that the in-memory object model of our cloud infrastructure app doesn't look anything like either XML, or the JSON in the Sun REST API, or any other conceivable protocol format. An implementor is going to have to transform between protocol and application semantics anyhow; I just don't want to have to do it more than once. -T
On Fri, May 8, 2009 at 10:58 PM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 8, 2009, at 12:21 PM, Sam Johnston wrote:
I'm still far from convinced that JSON meets the minimum requirements to
be in the running in the first place and nobody has addressed this point except to tell me to go back to square one and formally define them. Even the JSON junkies concede that while "XML documents can contain any imaginable data type", "JSON does not have a <[CDATA[]]> feature" so unless we want to contribute to the creation of a circus of cloud standards rather than provide the coherence of a loose framework on which to build, this point at the very least needs to be addressed.
What on earth does CDATA have to do with anything? JSON can carry arbitrary textual payloads without any extra effort. Oh, here's a dirty secret: both XML and JSON are lousy "wrapper" formats. If you have different kinds of things, you're usually better off letting them stand alone and link back and forth; that hypertext thing.
Right so say I want to create a new resource, or move it from one service to another, or manipulate its parameters, or any one of an infinite number of other potential operations - and say this resource is an existing virtual machine in a binary format (e.g. OVA) or an XML representation of a complex storage subsystem or a flat text network device config or... you get the point. It is *far* simpler for me to associate/embed the resource with its descriptor directly than to have a two phase process of uploading it and then feeding a URL to another call. I do expect this to be an exception rather than the rule, but it's critical in that if you can't (easily) get resources into and out of the system then we have failed. There's certainly going to be other standards around networking and security and storage and... so why would we not give them a sensible home when we just as easily can? As an aside I wonder how many times there were conversations like this previously (where working groups had the blinkers on with the usual "not in the charter" cop out) and how significant a contributor this inability to work together was to the WS-* train wreck... I have not been to the mat with the OCCI use cases so I'm not going to argue
that they contain things that can't be done in JSON. We didn't find any in our use-cases, but that may not be relevant here.
I think it's mostly about finding a balance between simple public cloud interfaces and overcomplicated virtualisation^Wprivate cloud interfaces... it would be a real shame if public clouds used OCCI and virtualisation setups used OVF-NG or whatever they're calling it. I'm envisaging OCCI being useful for a single workstation through (thanks to search/categories/tags/etc.) an entire organisation... I know that Amazon's EC2 API starts to choke when you have serious numbers of resources and I'll bet others have similar scalability problems. Tangential perhaps, but it helps to understand what we're trying to achieve... I have a negative interest in churning out something like Amazon's EC2 API or, at the other end of the scale, something like OVF. I honestly believe that Atom/XML is the happy medium and it's worth reminding you that I have no agenda whatsoever outside of delivering the best interface possible.
The disconnect here that's fascinating, looking in from outside, is between the people who feel that having multiple message formats is a problem and those who feel it's essential.
True. People have asked (and will continue to ask) for support of the format du jour... which is in part why I was positioning the OCCI core protocol as something akin to HTTP; it doesn't care what it carries, but it lacks the minimal of structure that we require. Remember also that Google are already using this in production for a myriad resources on a truly massive scale (and have already ironed out the bugs in 2.0) - the same cannot be said of the alternatives and dropping by their front door on the way could prove hugely beneficial. It will also allow us to reconvene when infrastructure gets boring (probably a year or two from now) and add new resources for e.g. platforms and applications without having to rewrite the entire protocol or start from scratch.
Definitely, the arguments have been enlightening but there are still some
big knowledge gaps. Mechanical transformations are another point that the JSON crowd have been totally silent about, likely because there is no solution that doesn't involve delving into the details of programming (something which is strictly out of bounds).
One of the reasons that us single-data-format people feel that way is that it moves the transformation problem out of scope. Less work is good. I guarantee that the in-memory object model of our cloud infrastructure app doesn't look anything like either XML, or the JSON in the Sun REST API, or any other conceivable protocol format. An implementor is going to have to transform between protocol and application semantics anyhow; I just don't want to have to do it more than once. -T
This sounds a lot like an externalisation: those in the best position to solve a problem damn well should, especially when it would be more expensive/impossible for others to do so. For JSON you have no choice but to roll your own translator - one for each language/platform you need translations done on. Conversely, for XML we can write the transform once and users (including others like the large and growing Atom community) can deploy it on any platform they like (even browsers) as well as contributing their own transforms. It's almost too easy (as evidenced by what I've managed to achieve in a week or two on my own and with no prior XSLT experience), though maybe that's another problem for those who'd prefer it be harder. Sam
On May 8, 2009, at 3:55 PM, Sam Johnston wrote:
Oh, here's a dirty secret: both XML and JSON are lousy "wrapper" formats. If you have different kinds of things, you're usually better off letting them stand alone and link back and forth; that hypertext thing.
Right so say I want to create a new resource, or move it from one service to another, or manipulate its parameters, or any one of an infinite number of other potential operations - and say this resource is an existing virtual machine in a binary format (e.g. OVA) or an XML representation of a complex storage subsystem or a flat text network device config or... you get the point. It is far simpler for me to associate/embed the resource with its descriptor directly than to have a two phase process of uploading it and then feeding a URL to another call.
By participating in this discussion I'm rapidly developing an obligation to go learn the use-cases and become actually well-informed on the specifics. And I'm uncomfortable disagreeing with Sam so much, because the work that's being done here seems good. But... I just don't buy the argument above. You can't package binary *anything* into XML (or JSON) without base-64-ing it, blecch. And here's the dirty secret: a lot of times you can't even package XML into other XML safely, you break unique-id attributes and digital signatures and namespace prefixes and embedded XPaths and so on and so on. The Web architecture really wants you to deal with resources as homogeneous blogs, that's why media-types are so important. The wild success of the browser platform suggests that having to retrieve more than one resource to get a job one is not a particularly high hurdle, operationally.
As an aside I wonder how many times there were conversations like this previously (where working groups had the blinkers on with the usual "not in the charter" cop out) and how significant a contributor this inability to work together was to the WS-* train wreck...
I'm waiting for someone to write the definitive book on why WS-* imploded. Probably mostly biz and process probs as you suggest, but I suspect not enough credit is given to the use at the core of XSD and WSDL, which are both profoundly-bad technologies. But I digress. Well, it's Friday.
Remember also that Google are already using this in production for a myriad resources on a truly massive scale (and have already ironed out the bugs in 2.0) - the same cannot be said of the alternatives and dropping by their front door on the way could prove hugely beneficial.
I think you're having trouble convincing people that GData, which is pure resource CRUD, is relevant to cloud-infrastructure wrangling. I'm a huge fan of GData. -Tim
On Sat, May 9, 2009 at 1:46 AM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 8, 2009, at 3:55 PM, Sam Johnston wrote:
Oh, here's a dirty secret: both XML and JSON are lousy "wrapper" formats.
If you have different kinds of things, you're usually better off letting them stand alone and link back and forth; that hypertext thing.
Right so say I want to create a new resource, or move it from one service to another, or manipulate its parameters, or any one of an infinite number of other potential operations - and say this resource is an existing virtual machine in a binary format (e.g. OVA) or an XML representation of a complex storage subsystem or a flat text network device config or... you get the point. It is far simpler for me to associate/embed the resource with its descriptor directly than to have a two phase process of uploading it and then feeding a URL to another call.
By participating in this discussion I'm rapidly developing an obligation to go learn the use-cases and become actually well-informed on the specifics. And I'm uncomfortable disagreeing with Sam so much, because the work that's being done here seems good.
Thanks, your input is very much appreciated.
But... I just don't buy the argument above. You can't package binary *anything* into XML (or JSON) without base-64-ing it, blecch. And here's the dirty secret: a lot of times you can't even package XML into other XML safely, you break unique-id attributes and digital signatures and namespace prefixes and embedded XPaths and so on and so on. The Web architecture really wants you to deal with resources as homogeneous blogs, that's why media-types are so important.
Payload transparency is a nice to have - that is, learning from OCCI that the thing has 2 CPUs and 2Gb RAM, but then being able to peer into embedded OVF to determine more advanced parameters. Given the vast majority of the payloads we're likely to want to use are going to be XML based (e.g. OVF) this should work reasonably well most of the time, and is in any case not critical for basic functionality. I'm not suggesting that someone embed a 40Gb base64 encoded image into the OCCI stream, but we can't assume that everything is always going to be flat files (VMX) or XML (OVF). Of course Atom "alternate" link relations elegantly solve the much of this problem and can even expose situations where the resource is available in multiple formats (e.g. VMX and OVF). For more advanced use cases I've proposed a bulk transfer API that essentially involves creating the resources by some other means and then passing it in to OCCI as a href (think regularly rsync'd virtual machines for disaster recovery purposes, drag and drop WebDAV interfaces and other stuff that implementors will, with any luck, implement). In any case this approach serves the migration requirement very well - the idea of being able to faithfully serialise and/or pass an arbitrarily complex collection of machines between implementations seems like utopia but it's well within our reach. Being then able to encrypt and/or sign it natively is just icing on the cake. There's absolutely nothing to say that OCCI messages have to be ephemeral<http://www.tbray.org/ongoing/When/200x/2006/12/21/JSON>and there are many compelling use cases (from backups to virtual appliances) where treating resources as documents and collections as feeds make a lot of sense - and few where it doesn't.
The wild success of the browser platform suggests that having to retrieve more than one resource to get a job one is not a particularly high hurdle, operationally.
Multiple requests is certainly a problem when you're dealing with a large number of resources, as is the case when you're wanting to display, report on or migrate even a small virtual infrastructure/data center. This is particularly true in enterprise environments where HTML requests tend to pass through a bunch of diffferent systems which push latency through the roof - I had to make some fairly drastic optimisations even to a GData client for Google Apps provisioning recently for exactly this reason and the thing would have been completely unusable had I have separate requests for each object.
As an aside I wonder how many times there were conversations like this
previously (where working groups had the blinkers on with the usual "not in the charter" cop out) and how significant a contributor this inability to work together was to the WS-* train wreck...
I'm waiting for someone to write the definitive book on why WS-* imploded. Probably mostly biz and process probs as you suggest, but I suspect not enough credit is given to the use at the core of XSD and WSDL, which are both profoundly-bad technologies. But I digress. Well, it's Friday.
I'd very much like to read this book but as an unbiased observer I do believe the blinkers played a critical role. Short of creating ad-hoc links between SSOs (as we will with SNIA next wednesday) there aren't really any good solutions... having one organisation handle the standardisation or even coordination of same is another recipe for disaster. Certainly choosing one format over another, especially when all markup ends up looking like XML<http://www.megginson.com/blogs/quoderat/2007/01/03/all-markup-ends-up-looking-like-xml/>, is not going to prevent the same from recurring, while playing nice in the sandpit may well be enough to avoid egregious offenses.
Remember also that Google are already using this in production for a
myriad resources on a truly massive scale (and have already ironed out the bugs in 2.0) - the same cannot be said of the alternatives and dropping by their front door on the way could prove hugely beneficial.
I think you're having trouble convincing people that GData, which is pure resource CRUD, is relevant to cloud-infrastructure wrangling. I'm a huge fan of GData.
CRUD plays a hugely important role in creating and maintaining virtual infrastructure (most resources are, after all, very much document like - e.g. VMX/OVF/VMDK/etc.) - just think about the operations clients typically need to do and the overwhelming majority of them are, in fact, CRUD. The main addition is triggering state changes via actuators/controllers (thanks for the great advice<http://www.tbray.org/ongoing/When/200x/2009/03/16/Sun-Cloud>on this topic by the way - very elegant) and this is something I believe we've done a good job of courtesy custom link relations. The main gaps currently relate to how to handle parametrised operations (e.g. resizing a storage resource) and how to create arbitrary associations between resources (e.g. from compute to its storage and network resources and less obvious ones like a logical volume back to its physical container). Oh and on the topic of performance, Google use projections<http://code.google.com/apis/calendar/docs/2.0/reference.html#Projection>to limit data returned - I was thinking we would return little more than IDs and titles by default (think discovery - a very common use case) and optionally provide a list of extensions (e.g. billing, performance monitoring, etc.) that we want to hear back from... this is going to be important for calls that take a long time (like summing up usage or retrieving the CDATA content) and by default the feed should stream without blocking. At the end of the day we can very easily create something (and essentially already have thanks in no small part to Google's pioneering work in this area) that can represent anything from a contact or calendar entry to a virtual machine or network. The advantages in terms of being able to handle non-obvious but equally important tasks such as managing users<http://code.google.com/apis/apps/gdata_provisioning_api_v2.0_reference.html#User_Account_URL_Table>are huge. JSON does make sense for many applications and I'd very much like to cater to the needs of JSON users by way of a dedicated Atom to JSON transformation (something others can contribute to and benefit from), but I don't believe it's at all the right choice for this application. Its main advantages were efficiency (much of which is lost thank to remediating security issues<http://en.wikipedia.org/wiki/JSON#Security_issues>with regular expressions - this parser code <http://www.json.org/json2.js> doesn't look any more performant than a native XML parser) and being able to bypass browser security, both of which are non-issues for us. Sam
Sam, Very quickly.. as I have to rush. On Fri, May 8, 2009 at 8:21 PM, Sam Johnston <samj@samj.net> wrote:
This isn't even a loose consensus...
Correct. We don't have consensus and we need to converge not diverge. To do so I am splitting the debate into sections: * Model * Interoperability * Metamodel * Integration .... IN THAT ORDER PLEASE ....
I'm still far from convinced that JSON meets the minimum requirements to be in the running in the first place and nobody has addressed this point except to tell me to go back to square one and formally define them. Even the JSON junkies concede that while "XML documents can contain any imaginable data type", "JSON does not have a <[CDATA[]]> feature" so unless we want to contribute to the creation of a circus of cloud standards rather than provide the coherence of a loose framework on which to build, this point at the very least needs to be addressed.
JSON vs XML for interop. People have started replying to this. We need to take the 'data format and interop' question into its own thread, and separate it from integration. ---> separate thread
We all agree that anything but the most basic specification of compute, storage and network resources is out of scope, but we then give no option but to have clients talk multiple APIs developed by multiple SSO's (almost certainly with completely different formats and structures). Am I the only one who sees a complete and utter clusterf--k in the making (think WS-* redux JSON edition)?
I'm afraid you have convinced me that multiple formats for interop will lead us to to WS-*. More on this later.
I don't consider this as a vote for a decision, but do think it has drawn out a lot of opinions and shown the lay of the land more clearly - in the light of the votes, the only two viable options are:
Definitely, the arguments have been enlightening but there are still some big knowledge gaps. Mechanical transformations are another point that the JSON crowd have been totally silent about, likely because there is no solution that doesn't involve delving into the details of programming (something which is strictly out of bounds). It's worth mentioning that I well appreciate the advantages of JSON but this is about choosing the right tool for the job - XML may be a sledgehammer but everyone's got one and you can't drive a nail with a screwdriver.
JSON vs XML for interop ---> separate thread.
- Single-format: JSON - Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
The point is that there is significant support for multiple formats so multiple formats should be supported even if only as a convenience for disparate audiences (see Ben Black's comments on this topic).
IMO - No. Support for something does not make it necessary for interop. Multiple formats is an integration issue. More on this later.
Trim the formats and you trim the audience and with it the potential for success.
IMO not true. The opposite is true for interop. Mess up interop and you have no success at all. We don't want an OCCI-Interop group to have to be formed later, in order to make all the variances between formats go away.
I definitely think we need to focus on one and give mechanical transforms as a convenience for the others though, which essentially addresses Ben's concerns about interoperability problems.
One for INTEROP. Many for INTEGRATION.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
There is no "later"... I need to have my presentation for Prague submitted and a coherent format to discuss with SNIA by Wednesday. That's not to say the model is perfect but it doesn't have to be for us to move on - the wrinkles will iron themselves out with people cutting code between OGF 26 (in under 3 weeks) and OGF 27 (in under 6 months). There is huge value in raising awareness/familiarity amongst potential users as early as possible (release early, release often and all that). I'll be promoting OCCI in London and Paris in the coming weeks too, provided I still believe it's going to work.
Feel free to present what we have agreed on. The rest is w.i.p. and subject to change.
There is still work here - e.g. verbs and attributes on networks have not been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
The model is extremely simple - a compute resource can have zero or more network resources and zero or more storage resources. It gets hairy when you start considering that all three can be virtualised in which case there will be use cases which require going back to the physical devices, and that's why we need to support absolutely flexible linking between resources (something that Atom is particularly good at).
Model -- to the model thread please.
2) The JSON vs. XML debate is not just about angle-brackets vs. curly-brackets.
I'm unconvinced that this has been demonstrated and still see it as 100% religion and bikeshed painting. Were we abusing XML then fair enough, but we're not - any simpler and it's plain text.
To the JSON vs XML thread.
Amongst the XML supporters, I have seen little opposition to a GData/Atom meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired the IETF Atom working group, felt it was the wrong choice, but then he doesn't support using XML at all in this context]
I'm less and less convinced that we're trying to solve the same problem here... the public cloud interfaces are extremely light (too light in places) but functional while the private cloud stuff is overkill. There is middle ground and we need to find it if hybrid clouds are to be a reality.
Thanks for pointing us at Tim's post: http://www.tbray.org/ongoing/When/200x/2009/03/16/Sun-Cloud .. I think he also aims at the middle ground "Lightweight lockin-free data-center virtualization might be bigger, I think."
Do the 10 JSON supporters agree with this, or have I misjudged it and there is actually strong support for GData-JSON?
By GData-JSON you of course mean a generic XML to JSON transformation which results in functional but ugly JSON. I'm unconvinced that a "pretty" protocol is a requirement provided it is still accessible/approachable - this works for Google so it will work for us, and it's trivial while your proposed alternative is very far from it.
Interop. is the priority. Syntax and sugar --> integration.
That said, work on Atom to JSON has already been done and an "application/atom+json" RFC would be hugely beneficial for many audiences. I'd suggest JSON be a convenience primarly for web developers and that a generic XML to JSON transform be used while an Atom to JSON transform is developed (that's something I'd happily to contribute to separately).
TBD.
Myself and Chris would be happy to lead developing the JSON rendering it its own right if people agree with my statements above and hence that it does need independent development (from the same set of nouns/verb/attributes and semantics).
That's all well and good but anyone can write a "rendering" - it's the "renderer" that's hard work. If you and Chris are volunteering to get us to the point we are already with XML, by Wednesday, then we've got something to talk about.
Richard, Chris, do what you feel is needed .... over to you ;-)
The point is that there are many different audiences to satisfy and we can trivially satisfy them all, quickly, if we stick with lightweight XML. Move to JSON and there's serious doubt as to whether we'll even be able to deliver on our charter (e.g. playing nice with others).
This is to be discussed.
Something you haven't covered in your summary is the strong consensus to keep the model and protocol separate. That's something that I for one would like to see more of going forward and I specifically don't want to see the model spilling over into the protocol if it will limit its potential application and complicate/specialise mechanical transformation.
Not sure what you mean - I think Richard is keeping them very separate, as is the Sun API approach. IMO, this actually should be part of the metamodel discussion: CRUD/HTTP vs REST/HTTP approaches, etc. alexis
Sam
Cheers,
Richard.
==========================================
JSON: 10 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009-May/000455.html - Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009-May/000440.html - Michael Richardson (private mail to me) - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
XML: 5 - Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
TXT: 2 - Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote)
Single: 3 - Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009-May/000457.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html - Richard Davies (revised in light of Tim Bray's comments)
Multi: 3 - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html - Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009-May/000439.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
All, Following the weekend's discussion, Myself and Chris have put together a simple JSON rendering for OCCI, directly from the Nouns, Verbs and Attributes: http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/SimpleJSONRen... I'd like people to take a look and comment. This simple JSON rendering could be adopted exactly as written, or used as a reference point for whether alternative JSON renderings are adding unnecessary complexity - it sets a stake in the ground for how simple an OCCI format could be. It attempts to borrow some naming and other conventions from XML Atom and other APIs which OCCI has discussed. If we were to go this route the only remaining task would be to finish the nouns, verbs and attributes (networks in particular are still not well defined). Cheers, Richard.
Richard Thank-you very much! For the benefit of showing what an integration point might look like, would it be possible to autogenerate some XML from this? a On Mon, May 11, 2009 at 5:29 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
All,
Following the weekend's discussion, Myself and Chris have put together a simple JSON rendering for OCCI, directly from the Nouns, Verbs and Attributes:
http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/SimpleJSONRen...
I'd like people to take a look and comment.
This simple JSON rendering could be adopted exactly as written, or used as a reference point for whether alternative JSON renderings are adding unnecessary complexity - it sets a stake in the ground for how simple an OCCI format could be. It attempts to borrow some naming and other conventions from XML Atom and other APIs which OCCI has discussed.
If we were to go this route the only remaining task would be to finish the nouns, verbs and attributes (networks in particular are still not well defined).
Cheers,
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
For the benefit of showing what an integration point might look like, would it be possible to autogenerate some XML from this?
I don't know what the standard tools are, but I'm sure it would be a trivial mechanical transform to go between: [ { "id": "418d982c-9f6a-4079-9aa9-82123b10c533", "category": "server", "title": "My Server", "cores": 2, "memory": 2147483648, "status": "active", "ide:0:0": { "source": "65a1e5c4-19a5-4e7b-8a76-8c6460d78734", "title": "Primary hard disk attachment" } }, { "id": "65a1e5c4-19a5-4e7b-8a76-8c6460d78734", "category": "storage", "title": "My Storage", "size": 1000000000 } ] and: <object> <id>418d982c-9f6a-4079-9aa9-82123b10c533"</id> <category>server</category> <title>My Server</title> <cores>2</cores> <memory>2147483648</memory> <status>active</status> <ide:0:0> <source>65a1e5c4-19a5-4e7b-8a76-8c6460d78734</source> <title>Primary hard disk attachment</title> </ide:0:0> </object> <object> <id>65a1e5c4-19a5-4e7b-8a76-8c6460d78734</id> <category>storage</category> <title>My Storage</title> <size>1000000000</size> </object> [Actually - this example might just have pointed out that : is not a great character for the interface specifier!] Obviously the XML version could have all the tags put inside an occi namespace and an appropriate schema describing them. Cheers, Richard.
On Mon, May 11, 2009 at 7:00 PM, Richard Davies < richard.davies@elastichosts.com> wrote:
For the benefit of showing what an integration point might look like, would it be possible to autogenerate some XML from this?
I don't know what the standard tools are, but I'm sure it would be a trivial mechanical transform to go between
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet). Enter the externalisation in the form of expensive consultants required to implement $PREFERRED_FORMAT in $PREFERRED_LANGUAGE, which is one of a number of areas where oversimplification actually ends up biting the users. Note that short of implementing each format for each language, there's absolutely nothing we can do to help them here. Sam
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML. Richard.
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard, Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?) The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ... regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com> Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534 ______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.
So long as the grammar is regular it can be transcoded from one to another....just make it regular. Chas. Roger Menday wrote:
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process: "The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model." It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically. Andy -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard, Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?) The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ... regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com> Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534 ______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
Andy It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural. alexis On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Quoting [Alexis Richardson] (May 12 2009):
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
That is indeed difficult to define, IMHO. My (biased) example is the SAGA spec in OGF (Simple API for Grid Applications): the API specification is language neutral, but several renderings for Java, C++, Python etc exist, and will be normative in their own right (spec documents are WIP). The abstract specification includes a number of syntactic and (more so) semantic guidelines which MUST be followed by the renderings, to maintain common nouns, verbs and attributes (no surprise, he?). But language specific deviations are allowed, were sensible (error handling, booststrapping, etc). Interopn can indeed only effectively defined for the individual renderings. We believe, however, that implementations of different renderings are assumed interoperable, if the respective test suites result in the same backend operations. For SAGA, that is difficult to prove - the API is too large for that. For OCCI, with its limites set of nouns/verbs/attribs, that may very well be possible. FWIW, other APIs in OGF went a similar route, most notably DRMAA. Their original spec is in C, but after several renderings emerged for Java, Python, etc, a language neutral spec (IDL) was created to derive these bindings from. Interop again is defined via test suites. Note: a different to OCCI is that neithe SAGA nor DRMAA talk about protocols, but *only* about client side APIs, rendered in higher level programming languages. My $0.02, Andre.
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
Andre, Andy, If you guys think you can provide a formal equivalent of a canonical interop rendering of the format, that might well be useful because it would provide a means to specify and check conformance. I still think there can be only one interop format - I think Chris put it very well. alexis On Tue, May 12, 2009 at 1:41 PM, Andre Merzky <andre@merzky.net> wrote:
Quoting [Alexis Richardson] (May 12 2009):
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
That is indeed difficult to define, IMHO. My (biased) example is the SAGA spec in OGF (Simple API for Grid Applications): the API specification is language neutral, but several renderings for Java, C++, Python etc exist, and will be normative in their own right (spec documents are WIP).
The abstract specification includes a number of syntactic and (more so) semantic guidelines which MUST be followed by the renderings, to maintain common nouns, verbs and attributes (no surprise, he?). But language specific deviations are allowed, were sensible (error handling, booststrapping, etc).
Interopn can indeed only effectively defined for the individual renderings. We believe, however, that implementations of different renderings are assumed interoperable, if the respective test suites result in the same backend operations.
For SAGA, that is difficult to prove - the API is too large for that. For OCCI, with its limites set of nouns/verbs/attribs, that may very well be possible.
FWIW, other APIs in OGF went a similar route, most notably DRMAA. Their original spec is in C, but after several renderings emerged for Java, Python, etc, a language neutral spec (IDL) was created to derive these bindings from. Interop again is defined via test suites.
Note: a different to OCCI is that neithe SAGA nor DRMAA talk about protocols, but *only* about client side APIs, rendered in higher level programming languages.
My $0.02,
Andre.
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
Andre, Maybe we should bang heads together? andy -----Original Message----- From: Alexis Richardson [mailto:alexis.richardson@gmail.com] Sent: 12 May 2009 13:54 To: Andre Merzky Cc: Edmonds, AndrewX; Roger Menday; occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI Andre, Andy, If you guys think you can provide a formal equivalent of a canonical interop rendering of the format, that might well be useful because it would provide a means to specify and check conformance. I still think there can be only one interop format - I think Chris put it very well. alexis On Tue, May 12, 2009 at 1:41 PM, Andre Merzky <andre@merzky.net> wrote:
Quoting [Alexis Richardson] (May 12 2009):
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
That is indeed difficult to define, IMHO. My (biased) example is the SAGA spec in OGF (Simple API for Grid Applications): the API specification is language neutral, but several renderings for Java, C++, Python etc exist, and will be normative in their own right (spec documents are WIP).
The abstract specification includes a number of syntactic and (more so) semantic guidelines which MUST be followed by the renderings, to maintain common nouns, verbs and attributes (no surprise, he?). But language specific deviations are allowed, were sensible (error handling, booststrapping, etc).
Interopn can indeed only effectively defined for the individual renderings. We believe, however, that implementations of different renderings are assumed interoperable, if the respective test suites result in the same backend operations.
For SAGA, that is difficult to prove - the API is too large for that. For OCCI, with its limites set of nouns/verbs/attribs, that may very well be possible.
FWIW, other APIs in OGF went a similar route, most notably DRMAA. Their original spec is in C, but after several renderings emerged for Java, Python, etc, a language neutral spec (IDL) was created to derive these bindings from. Interop again is defined via test suites.
Note: a different to OCCI is that neithe SAGA nor DRMAA talk about protocols, but *only* about client side APIs, rendered in higher level programming languages.
My $0.02,
Andre.
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Nothing is ever easy.
------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
Alexis Richardson <alexis.richardson@gmail.com> writes:
I still think there can be only one interop format - I think Chris put it very well.
I didn't make quite that strong a statement! It's fine to have multiple interop formats but you can't have *optional* interop formats. Clients can't rely on anything optional: they have to use one of the compulsory renderings if they want their code to be portable across cloud providers. Cheers, Chris.
On Tue, May 12, 2009 at 2:30 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Alexis Richardson <alexis.richardson@gmail.com> writes:
I still think there can be only one interop format - I think Chris put it very well.
I didn't make quite that strong a statement! It's fine to have multiple interop formats but you can't have *optional* interop formats. Clients can't rely on anything optional: they have to use one of the compulsory renderings if they want their code to be portable across cloud providers.
Maybe we are talking about different things. I am talking about the format for the data exchanged between client and cloud.
Cheers,
Chris.
Alexis Richardson <alexis.richardson@gmail.com> writes:
Maybe we are talking about different things. I am talking about the format for the data exchanged between client and cloud.
We're talking about the same thing. If the cloud supports multiple data formats like our API server does, and you have to offer all of them to be compliant with the spec, users can rely on any of them. If some of them might or might not be there, users can't rely on those. Cheers, Chris.
Actually, I still don't see a problem here. If we have an abstract rendering, which formally specifies the semantics of the data, and normative renderings which formally define the mapping to concrete formats (JSON, CSV, etc.), then it is trivial to put a converter (say, XSLT in the XML case) between them to map the data. The same thing can be done for all other renderings as well, provided that the semantics of the data and renderings are fixed. -Alexander Am 12.05.2009 um 15:31 schrieb Alexis Richardson:
On Tue, May 12, 2009 at 2:30 PM, Chris Webb <chris.webb@elastichosts.com
wrote: Alexis Richardson <alexis.richardson@gmail.com> writes:
I still think there can be only one interop format - I think Chris put it very well.
I didn't make quite that strong a statement! It's fine to have multiple interop formats but you can't have *optional* interop formats. Clients can't rely on anything optional: they have to use one of the compulsory renderings if they want their code to be portable across cloud providers.
Maybe we are talking about different things.
I am talking about the format for the data exchanged between client and cloud.
Cheers,
Chris.
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Alexander Papaspyrou alexander.papaspyrou@tu-dortmund.de
Hi Alexander,
Actually, I still don't see a problem here.
If we have an abstract rendering, which formally specifies the semantics of the data, and normative renderings which formally define the mapping to concrete formats (JSON, CSV, etc.), then it is trivial to put a converter (say, XSLT in the XML case) between them to map the data.
The approach taken by Exhibit to modeling [1] is interesting, and IMO, the noun-attribute-verb approach taken by OCCI so far, is about right (although yet to be convinced on the verb part). So, identify the resources. Then for each resource there are simple properties and properties which link to other resources. That's the basis of the class model. Give every resource a HTTP URI. A rendering is always flat data structure, as it only ever describes the *current* resource. In key-value terms: the key is the name of the property and the value is either the string, float, etc, or a http uri to another resource. How this looks in json or xml too, is clear (?), and it is simple too, and could also be specified (?). However, we decide on only *1*. Key-value (i.e. www-form-urlencoded) is interesting as a rendering as its fits nicely with HTML forms. ([2] is somehow relevant to the above.) Roger [1] http://simile.mit.edu/wiki/Exhibit/Understanding_Exhibit_Database [2] http://www.tbray.org/ongoing/When/200x/2009/01/29/Name-Value-Pairs
The same thing can be done for all other renderings as well, provided that the semantics of the data and renderings are fixed.
-Alexander
Am 12.05.2009 um 15:31 schrieb Alexis Richardson:
On Tue, May 12, 2009 at 2:30 PM, Chris Webb <chris.webb@elastichosts.com
wrote: Alexis Richardson <alexis.richardson@gmail.com> writes:
I still think there can be only one interop format - I think Chris put it very well.
I didn't make quite that strong a statement! It's fine to have multiple interop formats but you can't have *optional* interop formats. Clients can't rely on anything optional: they have to use one of the compulsory renderings if they want their code to be portable across cloud providers.
Maybe we are talking about different things.
I am talking about the format for the data exchanged between client and cloud.
Cheers,
Chris.
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Alexander Papaspyrou alexander.papaspyrou@tu-dortmund.de
<Alexander Papaspyrou.vcf>
Roger Menday (PhD) <roger.menday@uk.fujitsu.com> Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534 ______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.
On May 12, 2009, at 7:00 AM, Alexander Papaspyrou wrote:
Actually, I still don't see a problem here.
If we have an abstract rendering, which formally specifies the semantics of the data, and normative renderings which formally define the mapping to concrete formats (JSON, CSV, etc.), then it is trivial to put a converter (say, XSLT in the XML case) between them to map the data.
That's true in theory. In practice, we observe that agreeing on a formal model in an interoperable way is immensely more difficult than interoperating on the actual bits-on-the-wire of a protocol. Consider, for couple of examples, the Internet and the World Wide Web. -Tim
Hi,
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
Is'nt it a lot to do with communication ? ... i.e. interoperation via the rendering, communication of the concepts primarily with a model. re : how renderings can be plural. I think it is interesting to at least think about how this works, even if the approach is that they are NOT plural .... related : as others have pointed out, there is a long history of information modeling at the OGF. Is there some cross-over, information modeling-wise, with existing work ? Roger
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb- attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.
On Tue, May 12, 2009 at 2:12 PM, Roger Menday <roger.menday@uk.fujitsu.com> wrote:
related : as others have pointed out, there is a long history of information modeling at the OGF. Is there some cross-over, information modeling-wise, with existing work ?
One would hope so. The (partly) scientific provenance of OGF surely favours some formal underpinnings here.
Roger
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb-attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free.
Again what Roger says here makes sense to me. Model provides a common understanding of the domain, albeit abstract - if this is not shared then how can interoperation begin? The model should support the bare minimum of necessary requirements (as we've already established). It's the lowest common denominator - if all support this model (or basic profile) then various services can then interoperate at least with the basics (concepts captured by noun-verb-attribute). The question of integration, is for me more so what formats (model renderings) can each service support of the various model serialisations (JSON, XML etc ). As to supporting numerous renderings, that's still an open question for me and more so if it is to be supported how is accepted formats discovery supported? Content negotiation? andy -----Original Message----- From: Roger Menday [mailto:roger.menday@uk.fujitsu.com] Sent: 12 May 2009 14:13 To: Alexis Richardson Cc: Edmonds, AndrewX; Richard Davies; occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI Hi,
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
Is'nt it a lot to do with communication ? ... i.e. interoperation via the rendering, communication of the concepts primarily with a model. re : how renderings can be plural. I think it is interesting to at least think about how this works, even if the approach is that they are NOT plural .... related : as others have pointed out, there is a long history of information modeling at the OGF. Is there some cross-over, information modeling-wise, with existing work ? Roger
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb- attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
______________________________________________________________________ Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469 This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
On Tue, May 12, 2009 at 2:23 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
The question of integration, is for me more so what formats (model renderings) can each service support of the various model serialisations (JSON, XML etc ). As to supporting numerous renderings, that's still an open question for me and more so if it is to be supported how is accepted formats discovery supported? Content negotiation?
Too much complexity - I have seen this tried and it is almost impossible to manage. ONE format for interop = you can't get it wrong and wonder wtf your supposedly interoperating client is not working. Happy to let a billion renderings bloom off the interoperable core.
andy
-----Original Message----- From: Roger Menday [mailto:roger.menday@uk.fujitsu.com] Sent: 12 May 2009 14:13 To: Alexis Richardson Cc: Edmonds, AndrewX; Richard Davies; occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
Hi,
Andy
It's not completely obvious to me how people can interoperate on just a model, nor how normative renderings can be plural.
Is'nt it a lot to do with communication ? ... i.e. interoperation via the rendering, communication of the concepts primarily with a model.
re : how renderings can be plural. I think it is interesting to at least think about how this works, even if the approach is that they are NOT plural ....
related : as others have pointed out, there is a long history of information modeling at the OGF. Is there some cross-over, information modeling-wise, with existing work ?
Roger
alexis
On Tue, May 12, 2009 at 11:53 AM, Edmonds, AndrewX <andrewx.edmonds@intel.com> wrote:
I'd (again) agree with this and would re-iterate Alexander's (Papaspyrou) earlier point on approach and process:
"The canonical way to cope with this issue [formats] (which, by the way, has proved right many times in the past) in many WGs within OGF is to separate this step not only in design, but also in specification: have an abstract "modeling" part in the spec which clearly defines the semantics the data, and one or more normative renderings for the abstract model."
It would also seem to me that although we have the noun-verb- attribute reasoning it might need to be expressed in an easier form to communicate, say graphically.
Andy
-----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Roger Menday Sent: 12 May 2009 11:43 To: Richard Davies Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
On 12 May 2009, at 11:20, Richard Davies wrote:
Therein lies the problem - there are no "standard tools" nor any way to specify a cross-platform mechanical transform for JSON (at least not yet).
Yes, I agree with you there - if we're going with multiple formats it'll be easier to define XML -> JSON than JSON -> XML.
Hi Richard,
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
regards Roger
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Roger Menday (PhD) <roger.menday@uk.fujitsu.com>
Senior Researcher, Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE, U.K. Tel: +44 (0) 208 606 4534
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
______________________________________________________________________
Fujitsu Laboratories of Europe Limited Hayes Park Central, Hayes End Road, Hayes, Middlesex, UB4 8FE Registered No. 4153469
This e-mail and any attachments are for the sole use of addressee(s) and may contain information which is privileged and confidential. Unauthorised use or copying for disclosure is strictly prohibited. The fact that this e-mail has been scanned by Trendmicro Interscan and McAfee Groupshield does not guarantee that it has not been intercepted or amended nor that it is virus-free. ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934
This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
On Tue, May 12, 2009 at 3:23 PM, Edmonds, AndrewX <andrewx.edmonds@intel.com
wrote:
As to supporting numerous renderings, that's still an open question for me and more so if it is to be supported how is accepted formats discovery supported? Content negotiation?
Yes, this is explained in the wiki under "Entry point". Sam
On Tue, May 12, 2009 at 12:43 PM, Roger Menday <roger.menday@uk.fujitsu.com>wrote:
Rather than transforming across the actual formats, there seems to be a interest in defining a model and then describe how to render onto various data formats. So, rendering-down, rather then transforming- across. (?)
These are both valid alternatives but given our ultimate aim is to reduce costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
The data formats discussion is a tricky one to resolve, as there's things to like in each of JSON, ATOM and key-value. That said, the "compliant, but non-interoperable implementations through supporting multiple representations" is a strong argument for a single format. Whatever that may be ...
How does one representation for integration (e.g. desktop clients, RightScale-style management services, live migrations, etc.) and multiples for convenience (e.g. web interfaces, cron jobs, failover scripts, reporting, etc.) not satisfy everybody's needs in a risk-free fashion? Sam
Sam Johnston <samj@samj.net> writes:
These are both valid alternatives but given our ultimate aim is to reduce costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
Something implicit here is worth highlighting: this route only leads to interoperability if the extra formats are mandatory, not if they're optional. Otherwise, I can write an OCCI-compliant tool in bash which talks KEY VALUE text, but it won't be able to connect to Richard's front-end (which only understands JSON) or use another provider's front-end (which only understands Atom). The option of making one format mandatory and the others optional won't fly, because in that case the only way you write code that's guaranteed to work is to use the mandatory format, whereupon you've effectively converged on a single rendering in all but name. Cheers, Chris.
That is exactly right. Optionality has to be at the edges. On Tue, May 12, 2009 at 12:39 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Sam Johnston <samj@samj.net> writes:
These are both valid alternatives but given our ultimate aim is to reduce costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
Something implicit here is worth highlighting: this route only leads to interoperability if the extra formats are mandatory, not if they're optional.
Otherwise, I can write an OCCI-compliant tool in bash which talks KEY VALUE text, but it won't be able to connect to Richard's front-end (which only understands JSON) or use another provider's front-end (which only understands Atom).
The option of making one format mandatory and the others optional won't fly, because in that case the only way you write code that's guaranteed to work is to use the mandatory format, whereupon you've effectively converged on a single rendering in all but name.
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Tue, May 12, 2009 at 1:39 PM, Chris Webb <chris.webb@elastichosts.com>wrote:
Sam Johnston <samj@samj.net> writes:
These are both valid alternatives but given our ultimate aim is to reduce costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
Something implicit here is worth highlighting: this route only leads to interoperability if the extra formats are mandatory, not if they're optional.
No, this route leads to interoperability *provided at least one format is mandatory*. I don't rate myself enough to say which alternative formats will be most useful today, let alone tomorrow, so if the number of required formats exceeds 1 (it need not IMO) then it should be no more than 2 or 3 and we should make life as easy as possible for implementors (think transforms).
Otherwise, I can write an OCCI-compliant tool in bash which talks KEY VALUE text, but it won't be able to connect to Richard's front-end (which only understands JSON) or use another provider's front-end (which only understands Atom).
Right, obviously at least one format needs to be mandated and that format should obviously be as widely supported and easily translated to others as possible. Simplicity, while important, is secondary IMO - oversimplifying has the same result as overcomplicating.
The option of making one format mandatory and the others optional won't fly, because in that case the only way you write code that's guaranteed to work is to use the mandatory format, whereupon you've effectively converged on a single rendering in all but name.
...so we should just converge on a single rendering and be done with it? There is absolutely value in convenience formats, as evidenced by Google's JSON renderer... without them we wouldn't be able to do things like setup cron jobs to run regular tasks or write scripts to automate routine tasks such as failover. Quoting your own insightful "Designing a great HTTP API<http://www.elastichosts.com/blog/2009/01/01/designing-a-great-http-api/>" post from earlier in the year (because I couldn't have said it better or clearer myself):
Simple syntax means making it easy for any user with a standard tool to call the API. *If you can’t call the API with curl from a single line of shell then your API** is not good enough*. This rules out many of today’s cumbersome XML-RPC and SOAP APIs, although *you will want **XML as an option for users who are using XML**-friendly languages*.
We believe in:
-
Choice of syntax: Different users will find different syntax most natural. At the unix shell, space-deliminated text rules. From Javascript, you’ll want JSON. From Java, you may want XML. Some tools parse x-www-form-encoded data nicely. *A great HTTP API** makes every command available with data in all of these formats for all of these users *, specified with either different URLs or MIME content types. (OK, we admit that we’ve only released text/plain ourselves so far, but *the rest are coming very soon!*). -
Don’t reinvent the wheel: Smart people designed the internet. There are good existing mechanisms for security (e.g. SSL/TLS), authentication (e.g. HTTP auth), error codes (e.g. HTTP status codes), etc. Use them, and don’t invent your own, unlike one UK payment gateway who invented a simple XOR encryption which is vulnerable<https://support.protx.com/forum/Topic6841-23-1.aspx>to a known plaintext attack and didn’t fix it when we pointed this out!
Sam
Sam Johnston <samj@samj.net> writes:
Right, obviously at least one format needs to be mandated and that format should obviously be as widely supported and easily translated to others as possible.
Nobody will be able to write portable code using the formats you don't mandate. That's unfortunate if the only mandated rendering forces you to pull in tens of thousands of lines of library code... Cheers, Chris.
On Tue, May 12, 2009 at 3:34 PM, Chris Webb <chris.webb@elastichosts.com>wrote:
Sam Johnston <samj@samj.net> writes:
Right, obviously at least one format needs to be mandated and that format should obviously be as widely supported and easily translated to others as possible.
Nobody will be able to write portable code using the formats you don't mandate. That's unfortunate if the only mandated rendering forces you to pull in tens of thousands of lines of library code...
Nobody ever said they would be able to... portability/interoperability are very different requirements to convenience/integration. Just because clients can't rely on support of a given format does not mean it shouldn't be offered at all. As but one example, scripting is a strong requirement that requires a text rendering, but we all agree that a text rendering does not go far enough. By that reasoning alone we need to support multiple formats, and this is but another area where implementors can innovate without hurting interoperability (for example by serving up a XUL<https://developer.mozilla.org/En/XUL>rendering for Firefox users). Sam
On Tue, May 12, 2009 at 3:34 PM, Chris Webb <chris.webb@elastichosts.com>wrote:
Sam Johnston <samj@samj.net> writes:
Right, obviously at least one format needs to be mandated and that format should obviously be as widely supported and easily translated to others as possible.
Nobody will be able to write portable code using the formats you don't mandate. That's unfortunate if the only mandated rendering forces you to pull in tens of thousands of lines of library code...
Nobody's forcing you to pull in any more code for one rendering than another - the Google GData clients have code for working with all of their 16 services and are Apache licensed so you can toss whatever you don't use. If you don't like that you can always start from scratch, and you would have to for JSON anyway because we have nothing today and I'm not about to [re]write it. Let's not forget that Apache Abdera <http://abdera.apache.org/> provides an open source AtomPub implementation for the server side too. Sam
Sam Johnston <samj@samj.net> writes:
Nobody's forcing you to pull in any more code for one rendering than another
A KEY VALUE parser is trivial to write. A JSON parser is fairly easy to write. An XML/Atom parser is a major undertaking. Those look like different amounts of code to me. Cheers, Chris.
An XML parser isn't any more difficult than writing any other one. Chas. Chris Webb wrote:
Sam Johnston <samj@samj.net> writes:
Nobody's forcing you to pull in any more code for one rendering than another
A KEY VALUE parser is trivial to write.
A JSON parser is fairly easy to write.
An XML/Atom parser is a major undertaking.
Those look like different amounts of code to me.
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
CEW <eprparadocs@gmail.com> writes:
An XML parser isn't any more difficult than writing any other one.
Really? I must be missing a trick here! In a number of places both inside our public cloud platform and in client code that interacts with it, I have the following parser code in bash for our simple KEY VALUE format: local KEY VALUE while read KEY VALUE; do case "$KEY" in [dispatch table] esac done I'm delighted to hear that I could just as easily and cheaply be using XML as my interchange format at this point, and given this, perhaps I should be doing so. Would you care to illustrate? Cheers, Chris.
Look at XML support in Python. It is pretty simple to use, almost effortless. So is, by the way ini file support. Chas. Chris Webb wrote:
CEW <eprparadocs@gmail.com> writes:
An XML parser isn't any more difficult than writing any other one.
Really? I must be missing a trick here! In a number of places both inside our public cloud platform and in client code that interacts with it, I have the following parser code in bash for our simple KEY VALUE format:
local KEY VALUE while read KEY VALUE; do case "$KEY" in [dispatch table] esac done
I'm delighted to hear that I could just as easily and cheaply be using XML as my interchange format at this point, and given this, perhaps I should be doing so. Would you care to illustrate?
Cheers,
Chris.
Python is easier to use than Bash. C. Chris Webb wrote:
CEW <eprparadocs@gmail.com> writes:
Look at XML support in Python. It is pretty simple to use, almost effortless. So is, by the way ini file support.
XML support in Python doesn't help me much in bash.
Cheers,
Chris.
I guess it was only a matter of time before this discussion digressed to "my $language is bigger than your $language" :) We're certainly not the first to think about command-line XML processing<http://www.ibm.com/developerworks/xml/library/x-tipclp.html>- commands like 'curl http://occitest.appspot.com | xpath //entry/title' work for me and besides, with an XML source we get a plain text rendering for free courtesy XSLT - *even if the provider doesn't support the format themselves* (example<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com> ). We already host a set of common (or uncommon) transforms in the Google code project <http://code.google.com/p/occi/> and people can use whatever format they like (at least for reading and for CSV, TXT, PDF, HTML, etc. that's all you need anyway - in this case you're likely just looking for a handle to pull). Anyway Chris, weren't you now advocating a JSON-only solution? Perhaps you could illustrate the bash 1-liner for that... Sam On Tue, May 12, 2009 at 5:10 PM, CEW <eprparadocs@gmail.com> wrote:
Python is easier to use than Bash.
C.
Chris Webb wrote:
CEW <eprparadocs@gmail.com> writes:
Look at XML support in Python. It is pretty simple to use, almost effortless. So is, by the way ini file support.
XML support in Python doesn't help me much in bash.
Cheers,
Chris.
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Sorry Sam. Sometimes the truth hurts...lol Chas. Sam Johnston wrote:
I guess it was only a matter of time before this discussion digressed to "my $language is bigger than your $language" :)
We're certainly not the first to think about command-line XML processing <http://www.ibm.com/developerworks/xml/library/x-tipclp.html> - commands like 'curl http://occitest.appspot.com | xpath //entry/title' work for me and besides, with an XML source we get a plain text rendering for free courtesy XSLT - /even if the provider doesn't support the format themselves/ (example <http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>).
We already host a set of common (or uncommon) transforms in the Google code project <http://code.google.com/p/occi/> and people can use whatever format they like (at least for reading and for CSV, TXT, PDF, HTML, etc. that's all you need anyway - in this case you're likely just looking for a handle to pull).
Anyway Chris, weren't you now advocating a JSON-only solution? Perhaps you could illustrate the bash 1-liner for that...
Sam
On Tue, May 12, 2009 at 5:10 PM, CEW <eprparadocs@gmail.com <mailto:eprparadocs@gmail.com>> wrote:
Python is easier to use than Bash.
C.
Chris Webb wrote: > CEW <eprparadocs@gmail.com <mailto:eprparadocs@gmail.com>> writes: > > >> Look at XML support in Python. It is pretty simple to use, almost >> effortless. So is, by the way ini file support. >> > > XML support in Python doesn't help me much in bash. > > Cheers, > > Chris. >
_______________________________________________ occi-wg mailing list occi-wg@ogf.org <mailto:occi-wg@ogf.org> http://www.ogf.org/mailman/listinfo/occi-wg
Sam Johnston <samj@samj.net> writes:
Anyway Chris, weren't you now advocating a JSON-only solution?
Personally, I remain a staunch advocate of whitespace separated KEY VALUE. To date, I have seen no technical justification for a more complex interface to something as conceptually trivial as an infrastructure cloud. However, because optional formats will (by definition) not be universal and hence not something that portable apps can rely on, and given that I (like you) am in the minority with this view, realistically I have to accept that we'll end up specifying mandatory data format(s) which wrap(s) the data in pointless fluff. Once I've conceded that we won't pick the right format, I then have to try to advocate the 'least wrong' one. JSON carries much less baggage than Atom, requires much less code to parse, and will be easier to translate back and forth from something more sysadmin-friendly with a small standalone C utility, which I'll end up writing for our clients if we implement the OCCI API. Cheers, Chris.
On Tue, May 12, 2009 at 6:11 PM, Chris Webb <chris.webb@elastichosts.com>wrote:
Sam Johnston <samj@samj.net> writes:
Anyway Chris, weren't you now advocating a JSON-only solution?
Personally, I remain a staunch advocate of whitespace separated KEY VALUE. To date, I have seen no technical justification for a more complex interface to something as conceptually trivial as an infrastructure cloud.
"Conceptually trivial" is not at all incompatible with "complex" at scale, and as I've said before oversimplification will kill off a standard just as efficiently as overcomplication. Yes you can define a model and map it directly to a wire format like JSON (a process that has been suggested a number of times already even today) but when you need to modify it you need to go through the same process and risk breaking existing code while you're at it. The result is both brittle and inextensible which is fine for Twitter but useless for real applications like OCCI on which enterprises will be looking to depend. However, because optional formats will (by definition) not be universal and
hence not something that portable apps can rely on, and given that I (like you) am in the minority with this view, realistically I have to accept that we'll end up specifying mandatory data format(s) which wrap(s) the data in pointless fluff.
Your "pointless fluff" is anothers' absolute requirement - remember that the ElasticHosts API is at one extreme end of the spectrum and it's about finding a balance - if we don't go far enough to be able to capture the use cases then we are more likely to fail than if we go too far. Here's the alternatives ordered by decreasing complexity... even vCloud is significantly less complicated on the wire than WS-* so far as I can tell: - WS-* (SOAP/XML-RPC) - DMTF (vCloud/OVF) - OCCI-XML <- sweet spot IMO - OCCI-JSON - TXT Once I've conceded that we won't pick the right format, I then have to try
to advocate the 'least wrong' one. JSON carries much less baggage than Atom, requires much less code to parse, and will be easier to translate back and forth from something more sysadmin-friendly with a small standalone C utility, which I'll end up writing for our clients if we implement the OCCI API.
Ok I think I've seen more than enough now - so you're saying that in order for the 1's and 0's on the wire passing between two computers to be pleasing to the human eye you're prepared to write a "standalone C utility" but won't under any circumstances accept XML? That's exactly what I referred to before as "cutting off my nose to spite my face". Why not just forget all about having a "pretty" protocol (which is a complete and utter waste of time for all it matters) and run with something like ASN.1 or ProtocolBuffers then? I'm just now starting to wonder whether I didn't wander into the wrong forum and shouldn't be over at DMTF paying for the privilege of watching a gaggle of vendors develop a standard that I might actually end up being able to use... Sam

It just hit me. JSON is utterly useless in this space. On Tue, May 12, 2009 at 6:11 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Once I've conceded that we won't pick the right format, I then have to try
to advocate the 'least wrong' one. JSON carries much less baggage than Atom,
Sorry, but you're wrong. The problem space here requires that there be in place the ability to take two function names which seemingly provide the same functionality, carry the same name, and yet couldn't be further apart in regards to the action they represent on each of the systems in which they live, and make a clear distinction as to what each particular function call actually does. In relation to XML, this particular problem was solved nearly 10 years ago with the introduction of XML namespaces, something JSON is simply not capable of dealing with at this stage of the game. requires much less code to parse,
As would any system that didn't have to differentiate between two words spelled exactly the same and yet had two completely different meanings.
and will be easier to translate back and
forth from
... from? If there's no back then there's no forth, so there's subsequently no back and forth between anything that means exactly the same thing on one system as it does another. But there's no such thing as two systems that are exactly alike. And JSON doesn't allow for such discrepancies. something more sysadmin-friendly with a small standalone C
utility,
Looks like the sysadmins are going to have to suck it up and learn French this semester. Sorry folks, JSON won't work in this space. Unless the goal of the OCCI is finding a way for system vendors to agree upon homogenizing their system API's? I'm pretty sure it's not, and in this regard, JSON simply will not work. Period. -- /M:D M. David Peterson Co-Founder & Chief Architect, 3rd&Urban, LLC Email: m.david@3rdandUrban.com | m.david@amp.fm Mobile: (206) 999-0588 http://3rdandUrban.com | http://amp.fm | http://broadcast.oreilly.com/m-david-peterson/
David, On Wed, May 13, 2009 at 2:22 AM, M. David Peterson <xmlhacker@gmail.com> wrote:
It just hit me. JSON is utterly useless in this space.
... The problem space here requires that there be in place the ability to take two function names which seemingly provide the same functionality, carry the same name, and yet couldn't be further apart in regards to the action they represent on each of the systems in which they live, and make a clear distinction as to what each particular function call actually does.
No it does not require that ability. That is exactly what we don't want to see because it will break interoperability. You are talking about INTEGRATION. In your example the requirement as I understand it is for two different providers to make a local interpretation of a name. This is exactly why we should encourage extensibility at the edge - where the provider is in control and the name has all the context that it needs available to it. But we need to keep local interpretations local. To prevent confusion, there can be NO scope for ambiguity in the common core. That is why the interop core format benefits from NOT being user extensible or namespaceable or anything else like that. TXT is almost good enough, but IMO in the end we benefit from a bit more structure out of the box. If we use XML for the interop core then we need a way to restrict users from extending it at runtime. If we use JSON for the interop core then there can be no confusion because users will be forced to do their XML extensions at the edge integration points.
In relation to XML, this particular problem was solved nearly 10 years ago with the introduction of XML namespaces, something JSON is simply not capable of dealing with at this stage of the game.
Namespaces would be disastrous for interop and a great way to achieve WS-fail. Namespaces are a win for integration.
requires much less code to parse,
As would any system that didn't have to differentiate between two words spelled exactly the same and yet had two completely different meanings.
Yes, this is why JSON is perfect for interop. The requirement for interop, is this: When two parties say the same thing to each other, they MUST mean the same thing.
Sorry folks, JSON won't work in this space. Unless the goal of the OCCI is finding a way for system vendors to agree upon homogenizing their system API's? I'm pretty sure it's not, and in this regard, JSON simply will not work. Period.
No, the goal is interoperability. This does not imply homogenization. See the recent mails from Randy and Ignacio on another thread.
-- /M:D
M. David Peterson Co-Founder & Chief Architect, 3rd&Urban, LLC Email: m.david@3rdandUrban.com | m.david@amp.fm Mobile: (206) 999-0588 http://3rdandUrban.com | http://amp.fm | http://broadcast.oreilly.com/m-david-peterson/
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Sam, On Wed, May 13, 2009 at 1:23 AM, Sam Johnston <samj@samj.net> wrote:
Yes you can define a model and map it directly to a wire format like JSON (a process that has been suggested a number of times already even today) but when you need to modify it you need to go through the same process and risk breaking existing code while you're at it. The result is both brittle and inextensible
Please can you spell out this argument so that I can understand it. When is a wire format "like" JSON, and why does modifying the format create a "brittle" system? I have yet to see any convincing argument that JSON is worse for OCCI core than XML. Extensibility is the enemy of interoperability. We should XML for Integration at the edge. NOT for the interop core.
which is fine for Twitter but useless for real applications like OCCI on which enterprises will be looking to depend.
Meaning what exactly? "Enterprise" is a politically loaded term with no fixed denotation. See here just one example of "enterprise" being interpreted in a manner convenient to the author: http://www.zhen.org/zen20/2009/05/13/google-lost-grip-on-enterprise-reality/
However, because optional formats will (by definition) not be universal and hence not something that portable apps can rely on, and given that I (like you) am in the minority with this view, realistically I have to accept that we'll end up specifying mandatory data format(s) which wrap(s) the data in pointless fluff.
Your "pointless fluff" is anothers' absolute requirement
Requirement for integration or for interop.? A requirement for integration, may indeed be pointless for interop. It may even be fluffy :-)
Here's the alternatives ordered by decreasing complexity... even vCloud is significantly less complicated on the wire than WS-* so far as I can tell:
WS-* (SOAP/XML-RPC) DMTF (vCloud/OVF) OCCI-XML <- sweet spot IMO OCCI-JSON TXT
Good diagram. I agree with the order but not the sweet spot. So I think we are all gradually getting closer to being able to debate specific issues without other issues getting in the way. This is great progress. alexis
Missed this... On Wed, May 13, 2009 at 10:44 AM, Alexis Richardson < alexis.richardson@gmail.com> wrote:
Sam,
On Wed, May 13, 2009 at 1:23 AM, Sam Johnston <samj@samj.net> wrote:
Yes you can define a model and map it directly to a wire format like JSON
(a
process that has been suggested a number of times already even today) but when you need to modify it you need to go through the same process and risk breaking existing code while you're at it. The result is both brittle and inextensible
Please can you spell out this argument so that I can understand it. When is a wire format "like" JSON, and why does modifying the format create a "brittle" system?
Parsing error? Try again s/JSON/POX/. The point is you create a monolithic model, sign it off, and then blat it out as discrete operations. To make changes you go back to your model, tweak it and blat it out again. Every time you do a round trip you risk making all sorts of wheels fall off in all sorts of ways - hence brittle. If you have no need for extensibility (Twitter) that's fine. If you do you want something like *eXtensible* Markup Language (XML) in which case you can safely add what you like in full confidence that you will upset nobody. For those parts that we want to interoperate we give a tight specification - for everything else anything goes. IOW, your average request to ElasticHosts is going to be skeletal while your average request to VMware (if they ever implement it) will be relatively fat. Who cares?
I have yet to see any convincing argument that JSON is worse for OCCI core than XML.
Yes you have, you just don't know it ;)
Extensibility is the enemy of interoperability. We should XML for Integration at the edge. NOT for the interop core.
Rubbish - we need extensibility and there is no "edge" - if you get to the "edge" of a protocol specified in this fashion you drop off the side. We can have an infinite number of arbitrarily specified network parameters and so long as we say that the "ip" and "gateway" fields are to be used for interoperability we're fine - interop works side by side with extensibility. Besides, as I explained before, interop is the exceptional use case - integration is the rule. If Microsoft decide to use "ms-ip" instead then they are not interoperable - indeed if they don't specify "ip" the schemas will complain about conformance too. For non-XML formats we don't have this luxury and have either to point two possibly equally broken implementations at each other, have a protocol analyzer in one hand and the spec in another, or both. I know which I prefer.
which is fine for Twitter but useless for real applications
like OCCI on which enterprises will be looking to depend.
Meaning what exactly?
"Enterprise" is a politically loaded term with no fixed denotation. See here just one example of "enterprise" being interpreted in a manner convenient to the author:
http://www.zhen.org/zen20/2009/05/13/google-lost-grip-on-enterprise-reality/
Where you see me say "enterprise" you can substitute "business with a 5 or 6 figure headcount, usually from this list<http://en.wikipedia.org/wiki/CAC_40> ". Oh, and VMware bashes Google, claims enterprise wants private cloud. No they don't <http://samj.net/2009/05/bragging-rights-valeos-30000-google.html>. Film at 11.
However, because optional formats will (by definition) not be universal and hence not something that portable apps can rely on, and given that I (like you) am in the minority with this view, realistically I have to accept that we'll end up specifying mandatory data format(s) which wrap(s) the data in pointless fluff.
Your "pointless fluff" is anothers' absolute requirement
Requirement for integration or for interop.? A requirement for integration, may indeed be pointless for interop. It may even be fluffy :-)
Most of our use cases are for integration, not interop. That makes sense when you think about it - I want my systems to work well together and couldn't care less about moving them (except as a loaded shotgun when it comes to contract negotiations).
Here's the alternatives ordered by decreasing complexity... even vCloud is
significantly less complicated on the wire than WS-* so far as I can tell:
WS-* (SOAP/XML-RPC) DMTF (vCloud/OVF) OCCI-XML <- sweet spot IMO OCCI-JSON TXT
Good diagram. I agree with the order but not the sweet spot.
So I think we are all gradually getting closer to being able to debate specific issues without other issues getting in the way. This is great progress.
Sure, as soon as people realise that what might work for them won't necessarily work for everyone we can move on. Sam
Sam, On Thu, May 14, 2009 at 7:40 PM, Sam Johnston <samj@samj.net> wrote:
Extensibility is the enemy of interoperability. We should XML for Integration at the edge. NOT for the interop core.
Rubbish - we need extensibility and there is no "edge"
Thanks Sam. I am not arguing against extensions, I am arguing that dealing with them needs to be done so as to not make it easy to break interop. The reason that extensibility is the enemy of interoperability is that if two users extend the core protocol then: 1. If they do not interoperate then this is really hard to debug without appealing to the users who made them. "Really hard" meaning "impractical to the point of hampering adoption". 2. If they appear to interoperate then we still cannot tell if they are actually interoperating because the semantics of their extensions may not be the same. But, users want extensions. The solution to this problem is to allow extensions but not require them to be in the core protocol. Not being in the core protocol, means being on the 'edge', which is an appropriate term for 'not core' or 'at the edge of the network' to be more specific. Does TCP have extensions? No. (Or if it does people apparently don't use them because it would break interop) Does WS-* have extensions? Yes. Please - anyone - tell me what is wrong with the above argument. Sam, I liked Gary's diagrams - perhaps you did too which suggests some common ground or that we are arguing at cross purposes? alexis
On Thu, May 14, 2009 at 9:01 PM, Alexis Richardson < alexis.richardson@gmail.com> wrote:
I am not arguing against extensions, I am arguing that dealing with them needs to be done so as to not make it easy to break interop.
We're arguing for the same thing then. Good.
The reason that extensibility is the enemy of interoperability is that if two users extend the core protocol then:
1. If they do not interoperate then this is really hard to debug without appealing to the users who made them. "Really hard" meaning "impractical to the point of hampering adoption".
2. If they appear to interoperate then we still cannot tell if they are actually interoperating because the semantics of their extensions may not be the same.
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space. If we missed it and we need it we can add it in a revision (and I'm not thinking infrequent major revisions like 1.0 vs 2.0, rather regular addition of extensions to cover needs in order of priority). If OCCI core (sans resources) never needed to change I'd be happy, which means it should be really minimalistic and very extensible. A good specification explicitly deals with extensibility (assuming it is desired) - Atom has an entire section on Extending Atom<http://tools.ietf.org/html/rfc4287#section-6>the gist of which is: * *
*Atom Processors that encounter foreign markup in a location that is legal according to this specification MUST NOT stop processing or signal an error. It might be the case that the Atom Processor is able to process the foreign markup correctly and does so. Otherwise, such markup is termed "unknown foreign markup".*
Basically, if you don't know what it does then don't touch it.
But, users want extensions. The solution to this problem is to allow extensions but not require them to be in the core protocol. Not being in the core protocol, means being on the 'edge', which is an appropriate term for 'not core' or 'at the edge of the network' to be more specific.
I'm happy to have nothing in the core protocol *except* extensibility... think the microkernel approach to standards development. That's not a bad analogy actually, only all the things that make it not work for operating systems (e.g. context switching costs) don't apply here. Andy's alternative is more like a monolithic kernel and we all know what happens when you try to poke a broken driver into one of those. This approach is actually necessary if we want to support hypervisor-only setups (e.g. core + compute), nas/san (core + storate) and network devices (core + network).
Does TCP have extensions? No. (Or if it does people apparently don't use them because it would break interop)
Actually yes it does but they don't work properly because of broken, non-compliant middleware (think ECN). You can read a Google paper on Probing the viability of TCP extensions<http://www.imperialviolet.org/binary/ecntest.pdf>for more details but it boils down to: *TCP was designed with extendibility in mind, chiefly reflected in the
options mechanism. However, there have beenrepeated observations of misbehaving middleware that have hampered the deployment of beneficial TCP extensions*
Extensibility now doesn't work so TCP's users pay (in expensive workarounds, reduced functionality/performat, etc.). Does WS-* have extensions? Yes.
It wasn't WS-*'s extensibility that killed it. If we act like we're operating in a vacuum then we'll have exactly the same result.
Please - anyone - tell me what is wrong with the above argument.
I just have. Not only that but it relies on the premise that I'm promoting putting extensibility where it can interfere with the interoperability components (I'm not).
Sam, I liked Gary's diagrams - perhaps you did too which suggests some common ground or that we are arguing at cross purposes?
Gary's diagrams were interesting but didn't get much of a rise out of me - adapters aren't particularly performant and someone has to write code which is exactly my problem with JSON... all of these problems (like everything) are fixable depending on how much code you want to write. XML adapters don't require coding (unless you call stylesheets coding). Sam

Yes. Extensions do not need to be interoperable. If it becomes clear that a given extension does need to be interoperable (e.g. widely adopted or lots of variations of the same theme) then that¹s a red flag indicating we need to evaluate it for inclusion in the core. On 5/14/09 12:42 PM, "Sam Johnston" <samj@samj.net> wrote:
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space.
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
Agreed.... ANd plugfests are a good way to help identify those extensions. -gary Randy Bias wrote:
Yes. Extensions do not need to be interoperable. If it becomes clear that a given extension *does* need to be interoperable (e.g. widely adopted or lots of variations of the same theme) then that’s a red flag indicating we need to evaluate it for inclusion in the core.
On 5/14/09 12:42 PM, "Sam Johnston" <samj@samj.net> wrote:
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space.
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias ------------------------------------------------------------------------
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Fri, May 15, 2009 at 6:08 AM, Gary Mazz <garymazzaferro@gmail.com> wrote:
Agreed.... ANd plugfests are a good way to help identify those extensions.
Exactly. If OCCI gets anything more than modest adoption (it certainly should provided we deliver on time) then we probably won't even have to organise these ourselves... organisations like the Open Cloud Consortium sound more geared up for this kind of thing anyway. OTOH sounds like a useful addition to the OGF27/28 agenda. Sam
Randy Bias wrote:
Yes. Extensions do not need to be interoperable. If it becomes clear that a given extension *does* need to be interoperable (e.g. widely adopted or lots of variations of the same theme) then that’s a red flag indicating we need to evaluate it for inclusion in the core.
On 5/14/09 12:42 PM, "Sam Johnston" <samj@samj.net> wrote:
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space.
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias ------------------------------------------------------------------------
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Fri, May 15, 2009 at 2:11 AM, Randy Bias <randyb@gogrid.com> wrote:
Yes. Extensions do not need to be interoperable. If it becomes clear that a given extension *does* need to be interoperable (e.g. widely adopted or lots of variations of the same theme) then that’s a red flag indicating we need to evaluate it for inclusion in the core.
Exactly - and by using registries we should be able to avoid this in most cases anyway. Process goes like this: - Extensible spec released, implementors have at it - MacroHard wants to talk about RAID levels for their upcoming BigDisk™ - It's not in the spec so they complain to the registry maintainer (us?) - We think it's a good idea (or not) and add it to the appropriate registry (or not) - JuniperBerry see MacroHard's BigDisk™ eating their lunch and want to add a similar feature to their LittleDisk™ - It's already in the registry so nothing needs to be done - bingo, interoperability This doesn't work for complicated requirements, but for that we have the good work being done by other SSOs like DMTF - we can continue to focus on what interests us and users can do everything they need without breaking out into multiple protocols. Sam On 5/14/09 12:42 PM, "Sam Johnston" <samj@samj.net> wrote:
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space.
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
Quoting [Sam Johnston] (May 15 2009):
On Fri, May 15, 2009 at 2:11 AM, Randy Bias <[1]randyb@gogrid.com> wrote:
Yes. Extensions do not need to be interoperable. If it becomes clear that a given extension does need to be interoperable (e.g. widely adopted or lots of variations of the same theme) then thats a red flag indicating we need to evaluate it for inclusion in the core.
Exactly - and by using registries we should be able to avoid this in most cases anyway. Process goes like this: * Extensible spec released, implementors have at it * MacroHard wants to talk about RAID levels for their upcoming BigDisk * It's not in the spec so they complain to the registry maintainer (us?) * We think it's a good idea (or not) and add it to the appropriate registry (or not) * JuniperBerry see MacroHard's BigDisk eating their lunch and want to add a similar feature to their LittleDisk * It's already in the registry so nothing needs to be done - bingo, interoperability
An alternative, but somewhat more heavyweight/slower, and thus only ustified when there is vested interest from multiple sides: * Extensible spec released, implementors have at it * MacroHard wants to talk about RAID levels for their upcoming BigDisk * It's not in the spec so they propose an extension package to us (aka OCCI-WG) * we discuss it, think it's a good idea (or not), and produce a formal specification document * implementors hack at it, and interop if proven by multiple implementations * JuniperBerry see MacroHard's BigDisk eating their lunch and want to add a similar feature to their LittleDisk * it's already specified so nothing needs to be done - bingo, interoperability Andre. PS.: I am not sure if OGF would go into the space of maintaining registries, or such. OGF's business is to produce specification documents, and to host the infrastructure for doing so. But I am sure that, if a registry is the way to go, we'll find a host for that...
This doesn't work for complicated requirements, but for that we have the good work being done by other SSOs like DMTF - we can continue to focus on what interests us and users can do everything they need without breaking out into multiple protocols. Sam
On 5/14/09 12:42 PM, "Sam Johnston" <[2]samj@samj.net> wrote:
Whoever said extensions need to be interoperable? We can do what we can (e.g. registries) but beyond that extensions are just somewhere for people to put stuff, like trunk space. -- Nothing is ever easy.
On Fri, May 15, 2009 at 11:04 AM, Andre Merzky <andre@merzky.net> wrote:
An alternative, but somewhat more heavyweight/slower, and thus only ustified when there is vested interest from multiple sides:
* Extensible spec released, implementors have at it * MacroHard wants to talk about RAID levels for their upcoming BigDisk * It's not in the spec so they propose an extension package to us (aka OCCI-WG) * we discuss it, think it's a good idea (or not), and produce a formal specification document * implementors hack at it, and interop if proven by multiple implementations * JuniperBerry see MacroHard's BigDisk eating their lunch and want to add a similar feature to their LittleDisk * it's already specified so nothing needs to be done - bingo, interoperability
Yes, we would need both - registries primarily for change management of attributes, states, etc. and full-blown extensions for more advanced topics like adding new resource types/styles (e.g. load balancers). I'd suggest breaking up the workload as follows: - Adopt AtomPub (+search, caching, etc.) as OCCI Core - *lots* of hard work already done (the alternative will almost certainly involve another OGF cycle, pushing the final delivery out to OGF 28 which is yet to be scheduled in 2010) - Specify compute, storage and network resources as separate extensions (probably in that order) - Specify state control as an extension <- at this point we have our implementable draft - Specify billing, performance monitoring, etc. as extensions - Flesh out over time based on demand for features One huge advantage of this approach is that we don't have to wait until the end before we start implementations - people can start right now (as I have).
PS.: I am not sure if OGF would go into the space of maintaining registries, or such. OGF's business is to produce specification documents, and to host the infrastructure for doing so. But I am sure that, if a registry is the way to go, we'll find a host for that...
One non-technical point to consider when it comes to things like registries is that using neutral ground like IANA make the standard *far* more likely to be adopted by other SSOs. Sam
Quoting [Sam Johnston] (May 15 2009):
Yes, we would need both - registries primarily for change management of attributes, states, etc. and full-blown extensions for more advanced topics like adding new resource types/styles (e.g. load balancers). I'd suggest breaking up the workload as follows: * Adopt AtomPub (+search, caching, etc.) as OCCI Core - lots of hard work already done (the alternative will almost certainly involve another OGF cycle, pushing the final delivery out to OGF 28 which is yet to be scheduled in 2010) * Specify compute, storage and network resources as separate extensions (probably in that order) * Specify state control as an extension <- at this point we have our implementable draft * Specify billing, performance monitoring, etc. as extensions * Flesh out over time based on demand for features
Looks good to me. Although Atom, which you favour, is still not decided upon ;-) Anyway, procedure and timeline look sensible, IMHO. FWIW, OGF28 should be around March 2010.
One huge advantage of this approach is that we don't have to wait until the end before we start implementations - people can start right now (as I have).
PS.: I am not sure if OGF would go into the space of maintaining registries, or such. OGF's business is to produce specification documents, and to host the infrastructure for doing so. But I am sure that, if a registry is the way to go, we'll find a host for that...
One non-technical point to consider when it comes to things like registries is that using neutral ground like IANA make the standard far more likely to be adopted by other SSOs.
Yes, good point. Andre.
Sam
-- Nothing is ever easy.
On Fri, May 15, 2009 at 11:46 AM, Andre Merzky <andre@merzky.net> wrote:
Quoting [Sam Johnston] (May 15 2009):
* Adopt AtomPub (+search, caching, etc.) as OCCI Core - lots of hard work already done (the alternative will almost certainly involve another OGF cycle, pushing the final delivery out to OGF 28 which is yet to be scheduled in 2010)
Looks good to me. Although Atom, which you favour, is still not decided upon ;-) Anyway, procedure and timeline look sensible, IMHO.
I'm *acutely* aware that Atom is still not decided upon - I'm the one who has the privilege of personally paying for a plane to prague (say that 3 times quickly!) to stand in front of an audience and tell everyone where we're at remember... drop AtomPub and I've got very little to talk about beyond the fact that we're on track to fail to deliver on our first deadline. Fun. For JSON (or any non-Atom format for that matter) you don't have these 20,000+ <http://tools.ietf.org/rfc/rfc4287.txt> words<http://tools.ietf.org/html/rfc5023>as a head start so I find it hard to imagine there's not at least one or two extra OGF cycles to factor in. To be safe you might even consider adopting Thijs' original timeline<http://www.ogf.org/pipermail/capi-bof/2009-March/000027.html>as the compressed version factored in the significant optimisation (albeit not deliberately/explicitly): *Goals/Deliverables: * OGF25: BoF session and group discussion OGF26: Group presentations / Spin-off of standardization work. OGF27: Document (#1) describing use cases and giving an overview of the current state of art / First draft of an API. OGF28: Document defining entities to be managed, their life-cycle and the associated processes to manage the life-cycle (#2) OGF29: Standardized API (#3) OGF30: Refinements OGF31: Final version of an API Does anyone seriously think there'll still be a window for OCCI to be relevant in 2011/2012 with the rate things are moving? That's what I thought. The point is we can still deliver on our promises by relying on AtomPub and pushing the feedback period to post-OGF26 to make up for lost time... alternatively you might just be able to squeeze in an implementable draft by OGF27 and final version by OGF28 "around March 2010" but I wouldn't rely on it and I wouldn't rely on it still being relevant - who knows, you might even end up being forced to implement DMTF's stuff because the "I can't believe it's not cloud" guys have got their ducks in a row before us ;) FWIW, OGF28 should be around March 2010.
If we've got our final version done by OGF27 (October 2009) then we can get to work on migrating to JSON (JSONPub anyone?) and with any luck drag the rest of the industry over with us through 2010/2011. Iff it makes sense to do so of course - AtomPub is plenty light enough IMO and much lighter starts to be flying too close to the ground (conversely, add schemas, namespaces etc. to JSON and you end up with XML with curly braces!).
One non-technical point to consider when it comes to things like registries is that using neutral ground like IANA make the standard far more likely to be adopted by other SSOs.
Yes, good point.
Glad we agree - this was one point that worried me a bit about dragging the attention towards a specific SSO outside of IETF... Sam
Alexis, JSDL has shown that extensions work fine even (sigh) with XML namespaces, without breaking interop. Leaving extension points with xsd:any with namespace #other and lax content allows for easy interop by just ignoring vendor-specific stuff. -Alexander Am 14.05.2009 um 21:01 schrieb Alexis Richardson <alexis.richardson@gmail.com
:
Sam,
On Thu, May 14, 2009 at 7:40 PM, Sam Johnston <samj@samj.net> wrote:
Extensibility is the enemy of interoperability. We should XML for Integration at the edge. NOT for the interop core.
Rubbish - we need extensibility and there is no "edge"
Thanks Sam.
I am not arguing against extensions, I am arguing that dealing with them needs to be done so as to not make it easy to break interop.
The reason that extensibility is the enemy of interoperability is that if two users extend the core protocol then:
1. If they do not interoperate then this is really hard to debug without appealing to the users who made them. "Really hard" meaning "impractical to the point of hampering adoption".
2. If they appear to interoperate then we still cannot tell if they are actually interoperating because the semantics of their extensions may not be the same.
But, users want extensions. The solution to this problem is to allow extensions but not require them to be in the core protocol. Not being in the core protocol, means being on the 'edge', which is an appropriate term for 'not core' or 'at the edge of the network' to be more specific.
Does TCP have extensions? No. (Or if it does people apparently don't use them because it would break interop)
Does WS-* have extensions? Yes.
Please - anyone - tell me what is wrong with the above argument.
Sam, I liked Gary's diagrams - perhaps you did too which suggests some common ground or that we are arguing at cross purposes?
alexis _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Fri, May 15, 2009 at 11:29 AM, Alexander Papaspyrou < alexander.papaspyrou@tu-dortmund.de> wrote:
JSDL has shown that extensions work fine even (sigh) with XML namespaces, without breaking interop.
Leaving extension points with xsd:any with namespace #other and lax content allows for easy interop by just ignoring vendor-specific stuff.
However you slice it, namespaces are almost certainly going to be a necessary evil for extensibility. Even for our own stuff namespaces are useful for differentiating between resource types rather than throwing everything in one bucket. I've already seen a "vx_au.net.aos" namespace option proposed for JSON extensibility based on a similar monstrosity I suggested earlier for XML - at the end of the day all markup ends up looking like XML<http://www.megginson.com/blogs/quoderat/2007/01/03/all-markup-ends-up-looking-like-xml/>anyway. Also playing nice with other standards includes OGF standards of course... is it safe to say these are mostly/soley done in XML? Sam
Sam, Am 15.05.2009 um 13:02 schrieb Sam Johnston:
On Fri, May 15, 2009 at 11:29 AM, Alexander Papaspyrou <alexander.papaspyrou@tu-dortmund.de
wrote: JSDL has shown that extensions work fine even (sigh) with XML namespaces, without breaking interop.
Leaving extension points with xsd:any with namespace #other and lax content allows for easy interop by just ignoring vendor-specific stuff.
However you slice it, namespaces are almost certainly going to be a necessary evil for extensibility. Even for our own stuff namespaces are useful for differentiating between resource types rather than throwing everything in one bucket. I've already seen a "vx_au.net.aos" namespace option proposed for JSON extensibility based on a similar monstrosity I suggested earlier for XML - at the end of the day all markup ends up looking like XML anyway.
Also playing nice with other standards includes OGF standards of course... is it safe to say these are mostly/soley done in XML?
yes. OGF is XML for data representation and WS* for service interfaces. While I agree that we should stay clean from the latter, I see no reason for rebuilding the features of the former just for the sake of avoiding to use it. -Alexander -- Alexander Papaspyrou alexander.papaspyrou@tu-dortmund.de
On Fri, May 15, 2009 at 1:15 PM, Alexander Papaspyrou < alexander.papaspyrou@tu-dortmund.de> wrote:
Sam,
Am 15.05.2009 um 13:02 schrieb Sam Johnston:
Also playing nice with other standards includes OGF standards of course...
is it safe to say these are mostly/soley done in XML?
yes. OGF is XML for data representation and WS* for service interfaces. While I agree that we should stay clean from the latter, I see no reason for rebuilding the features of the former just for the sake of avoiding to use it.
+1 I'd be interested to hear what Tim's thoughts are now he knows the bigger picture. JSON makes absolute sense for the Sun Cloud, where its purpose is to expose the functionality of a specific product, but less so when we need to expose the current and future functionality of every product. Sam
On May 12, 2009, at 7:17 AM, Chris Webb wrote:
A KEY VALUE parser is trivial to write.
A JSON parser is fairly easy to write.
An XML/Atom parser is a major undertaking.
Those look like different amounts of code to me.
I don't buy this argument. All of these parsers are routinely available to programmers in popular programming languages. -Tim
Tim, Exactly! I just want us to use something that has a regular grammar; I don't care what it is. Chas. Tim Bray wrote:
On May 12, 2009, at 7:17 AM, Chris Webb wrote:
A KEY VALUE parser is trivial to write.
A JSON parser is fairly easy to write.
An XML/Atom parser is a major undertaking.
Those look like different amounts of code to me.
I don't buy this argument. All of these parsers are routinely available to programmers in popular programming languages. -Tim _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Tue, May 12, 2009 at 6:01 PM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 12, 2009, at 7:17 AM, Chris Webb wrote:
A KEY VALUE parser is trivial to write.
A JSON parser is fairly easy to write.
An XML/Atom parser is a major undertaking.
Those look like different amounts of code to me.
I don't buy this argument. All of these parsers are routinely available to programmers in popular programming languages. -Tim
I've certainly never written a parser where one was available, except for some ASN.1 stuff where the key information I needed to extract from certificates was concealed in the usual APIs. As I explained to someone who privately suggested ASN.1 as an alternative for OCCI, I'd rather remove my own testicles with a rusty spoon than do that again. For XML we have native support in any language that matters. Even for Atom[Pub] we have native support in Microsoft's libraries and a full blown Apache Software Foundation project dedicated to the topic for Java. That's good enough for pretty much everyone - in the worst case for the most secure sites they'd end up making sense of Atom themselves using approved XML libraries. For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one. Sam
On May 12, 2009, at 1:02 PM, Sam Johnston wrote:
As I explained to someone who privately suggested ASN.1 as an alternative for OCCI, I'd rather remove my own testicles with a rusty spoon than do that again.
Sam is right. The thing is, ASN.1 might have had a chance if there were decent free tools. One of the reasons XML succeeded so widely is that there were multiple pretty-good open-source parsers available even before XML 1.0 shipped.
For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
We should put this to bed, once and for all. You can write a parser in anything and for the most part there are tools available in all the major languages and systems (I have written enough of them in my life). All I ask for is a regular grammar! After that I can transcode one form into another with little effort. Chuck Tim Bray wrote:
On May 12, 2009, at 1:02 PM, Sam Johnston wrote:
As I explained to someone who privately suggested ASN.1 as an alternative for OCCI, I'd rather remove my own testicles with a rusty spoon than do that again.
Sam is right. The thing is, ASN.1 might have had a chance if there were decent free tools. One of the reasons XML succeeded so widely is that there were multiple pretty-good open-source parsers available even before XML 1.0 shipped.
For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Tue, May 12, 2009 at 10:23 PM, Tim Bray <Tim.Bray@sun.com> wrote:
For JSON it's a lot less clear (at least for the famous enterprise users)
due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
Perhaps we do [live in different worlds]. Where I come from people would rather have silent phones<http://blogs.gartner.com/lydia_leong/2009/05/11/the-perils-of-defaults/>than risk changing a default setting. Opaque binaries and their updates pass without question while third-party/open source implementations are held up for months in convoluted approval processes (if not flat out banned). "Simplicity" translates to "Complexity" (so does "Complexity" for that matter). One of the reasons I'm pushing the point is because I'd actually like to be permitted to use the fruits of our labour. Sam
On Tue, May 12, 2009 at 3:24 PM, Sam Johnston <samj@samj.net> wrote:
One of the reasons I'm pushing the point is because I'd actually like to be permitted to use the fruits of our labour.
Just to throw a format out there that seems to have been left off the list and yet was designed from the ground up as an efficient data serialization format for decentralized grid/cloud computing, what about Protocol Buffers? I realize that using ProtofBuf in a majority of use cases being discussed on this list would be extreme overkill. But by its very nature, cloud computing tends to encourage the hucking of large amounts of data from one node and from one cloud to the next. In cases such as this where Interop between disparate platforms, systems, languages, etc. come par for the course, and therefore cleanly fit into the OCCI charter, shouldn't considerable thought be put into using the format best suited for the task at hand? -- /M:D M. David Peterson Co-Founder & Chief Architect, 3rd&Urban, LLC Email: m.david@3rdandUrban.com | m.david@amp.fm Mobile: (206) 999-0588 http://3rdandUrban.com | http://amp.fm | http://broadcast.oreilly.com/m-david-peterson/
It sound like there is a consensus here to agree to disagree. Having said that tongue in cheek, I'd have a few configurations issues I'd like to propose as it pertains to rendering. I've put it fixed font if it looks odd, change the font to a fixed version The drawings are simple 2 node systems. The systems represent integration points. You'll notice there are 2 interconnects between the systems. A rendered format and a logical model. I discriminate between the two, because, I believe they are two separate issues in terms of interoperability. I'm looking for consensus that these are the 4 simple models we will most likely encounter in deployments. -gary 1) OCCI Native Configuration ------------------ Native OCCI ------------------ | | Format | | | System A |<---------------------->| System B | | | | | ------------------ ------------------ System A Model <========================> System B Model ---------------------------------------------------------------------------------------------------------------- 2) OCCI Adapter Configuration --------------------------------------- ------------------ Native OCCI |----------- ------------ | | | Format || OCCI |<----------->| System B | | | System A |<---------------------->|| Adapter | Foreign | (Foreign)| | | | |----------- Format ------------ | ------------------ | | -------------------------------------- System A Model <========================> System B Foreign Model Model Transform ---------------------------------------------------------------------------------------------------------------- 3) Foreign Adapter Configuration --------------------------------------- ------------------ Native Foreign |----------- ------------ | | | Format || Foreign |<----------->| System B | | | System A |<---------------------->|| Adapter | OCCI | (OCCI) | | | (Foreign) | |----------- Format ------------ | ------------------ | | -------------------------------------- System A Foreign Model <=================> System B OCCI Model Model Transform ---------------------------------------------------------------------------------------------------------------- 4) Gateway Configuration ------------------ Native Foreign ----------------- Native OCCI ------------------ | | Format | | Format | | | System A |<------------------->| OCCI Gateway |<------------------->| System B | | (Foreign) | | | | (OCCI) | ------------------ ----------------- ------------------ System A Foreign Model <===================================================> System B OCCI Model Model Transform ---------------------------------------------------------------------------------------------------------------- Sam Johnston wrote:
On Tue, May 12, 2009 at 10:23 PM, Tim Bray <Tim.Bray@sun.com <mailto:Tim.Bray@sun.com>> wrote:
For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
Perhaps we do [live in different worlds]. Where I come from people would rather have silent phones <http://blogs.gartner.com/lydia_leong/2009/05/11/the-perils-of-defaults/> than risk changing a default setting. Opaque binaries and their updates pass without question while third-party/open source implementations are held up for months in convoluted approval processes (if not flat out banned). "Simplicity" translates to "Complexity" (so does "Complexity" for that matter).
One of the reasons I'm pushing the point is because I'd actually like to be permitted to use the fruits of our labour.
Sam
------------------------------------------------------------------------
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Alexis mentioned the ascii art failed, sorry... here is a pdf -gary It sound like there is a consensus here to agree to disagree. Having said that tongue in cheek, I'd have a few configurations issues I'd like to propose as it pertains to rendering. I've put it fixed font if it looks odd, change the font to a fixed version The drawings are simple 2 node systems. The systems represent integration points. You'll notice there are 2 interconnects between the systems. A rendered format and a logical model. I discriminate between the two, because, I believe they are two separate issues in terms of interoperability. I'm looking for consensus that these are the 4 simple models we will most likely encounter in deployments. -gary 1) OCCI Native Configuration ------------------ Native OCCI ------------------ | | Format | | | System A |<---------------------->| System B | | | | | ------------------ ------------------ System A Model <========================> System B Model ---------------------------------------------------------------------------------------------------------------- 2) OCCI Adapter Configuration --------------------------------------- ------------------ Native OCCI |----------- ------------ | | | Format || OCCI |<----------->| System B | | | System A |<---------------------->|| Adapter | Foreign | (Foreign)| | | | |----------- Format ------------ | ------------------ | | -------------------------------------- System A Model <========================> System B Foreign Model Model Transform ---------------------------------------------------------------------------------------------------------------- 3) Foreign Adapter Configuration --------------------------------------- ------------------ Native Foreign |----------- ------------ | | | Format || Foreign |<----------->| System B | | | System A |<---------------------->|| Adapter | OCCI | (OCCI) | | | (Foreign) | |----------- Format ------------ | ------------------ | | -------------------------------------- System A Foreign Model <=================> System B OCCI Model Model Transform ---------------------------------------------------------------------------------------------------------------- 4) Gateway Configuration ------------------ Native Foreign ----------------- Native OCCI ------------------ | | Format | | Format | | | System A |<------------------->| OCCI Gateway |<------------------->| System B | | (Foreign) | | | | (OCCI) | ------------------ ----------------- ------------------ System A Foreign Model <===================================================> System B OCCI Model Model Transform ---------------------------------------------------------------------------------------------------------------- Sam Johnston wrote:
On Tue, May 12, 2009 at 10:23 PM, Tim Bray <Tim.Bray@sun.com <mailto:Tim.Bray@sun.com>> wrote:
For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
Perhaps we do [live in different worlds]. Where I come from people would rather have silent phones <http://blogs.gartner.com/lydia_leong/2009/05/11/the-perils-of-defaults/> than risk changing a default setting. Opaque binaries and their updates pass without question while third-party/open source implementations are held up for months in convoluted approval processes (if not flat out banned). "Simplicity" translates to "Complexity" (so does "Complexity" for that matter).
One of the reasons I'm pushing the point is because I'd actually like to be permitted to use the fruits of our labour.
Sam
------------------------------------------------------------------------
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Interesting diagram, does seem to cover most of the common cases. Sam On Thu, May 14, 2009 at 9:13 AM, Gary Mazz <garymazzaferro@gmail.com> wrote:
Alexis mentioned the ascii art failed, sorry...
here is a pdf
-gary
It sound like there is a consensus here to agree to disagree. Having said that tongue in cheek, I'd have a few configurations issues I'd like to propose as it pertains to rendering.
I've put it fixed font if it looks odd, change the font to a fixed version
The drawings are simple 2 node systems. The systems represent integration points. You'll notice there are 2 interconnects between the systems. A rendered format and a logical model. I discriminate between the two, because, I believe they are two separate issues in terms of interoperability.
I'm looking for consensus that these are the 4 simple models we will most likely encounter in deployments.
-gary
1) OCCI Native Configuration
------------------ Native OCCI ------------------ | | Format | | | System A |<---------------------->| System B | | | | | ------------------ ------------------ System A Model <========================> System B Model
---------------------------------------------------------------------------------------------------------------- 2) OCCI Adapter Configuration
--------------------------------------- ------------------ Native OCCI |----------- ------------ | | | Format || OCCI |<----------->| System B | | | System A |<---------------------->|| Adapter | Foreign | (Foreign)| | | | |----------- Format ------------ | ------------------ | |
-------------------------------------- System A Model <========================> System B Foreign Model Model Transform
---------------------------------------------------------------------------------------------------------------- 3) Foreign Adapter Configuration
--------------------------------------- ------------------ Native Foreign |----------- ------------ | | | Format || Foreign |<----------->| System B | | | System A |<---------------------->|| Adapter | OCCI | (OCCI) | | | (Foreign) | |----------- Format ------------ | ------------------ | |
-------------------------------------- System A Foreign Model <=================> System B OCCI Model Model Transform
---------------------------------------------------------------------------------------------------------------- 4) Gateway Configuration
------------------ Native Foreign ----------------- Native OCCI ------------------ | | Format | | Format | | | System A |<------------------->| OCCI Gateway |<------------------->| System B | | (Foreign) | | | | (OCCI) | ------------------ ----------------- ------------------ System A Foreign Model <===================================================> System B OCCI Model Model Transform
----------------------------------------------------------------------------------------------------------------
Sam Johnston wrote:
On Tue, May 12, 2009 at 10:23 PM, Tim Bray <Tim.Bray@sun.com <mailto: Tim.Bray@sun.com>> wrote:
For JSON it's a lot less clear (at least for the famous enterprise users) due to the support, copyright, patent, etc. status surrounding third-party implementations. I know at least some of my clients have policies that would require developers to write the parser themselves - granted not a particularly difficult task but an unnecessary and error prone one.
We must live in different worlds. The Java programmers I know are like "Yeah, JSON, whatever", and for .NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex. Javascript/Python/Ruby, no problem. PHP I have no first-hand info, but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
Perhaps we do [live in different worlds]. Where I come from people would rather have silent phones < http://blogs.gartner.com/lydia_leong/2009/05/11/the-perils-of-defaults/> than risk changing a default setting. Opaque binaries and their updates pass without question while third-party/open source implementations are held up for months in convoluted approval processes (if not flat out banned). "Simplicity" translates to "Complexity" (so does "Complexity" for that matter).
One of the reasons I'm pushing the point is because I'd actually like to be permitted to use the fruits of our labour.
Sam
------------------------------------------------------------------------
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Tue, May 12, 2009 at 2:23 PM, Tim Bray <Tim.Bray@sun.com> wrote:
.NET, http://www.google.com/search?q=json%20.net turns up lots of stuff including from Microsoft's own Codeplex.
There's even native support for JSON inside of Silverlight[1] which for a company as XML-heavy as MSFT says quite a bit. Javascript/Python/Ruby, no problem. PHP I have no first-hand info,
but since half the Ajax-heavy sites in the planet are PHP-backed, I can't imagine it's an issue. -T
Yup. At this stage of the game when to use JSON and when to use XML for data serialization comes down to some pretty basic rules: * If you're working with: * Mixed content (e.g. this is <i>an example</i> of mixed <strong>content</strong>), * Mixed vocabularies (e.g. <foo xmlns="http://example.com/foo" xmlns:bar="http://example.com/foo/bar"><bar:baz/></foo>) * Data which requires schema-based validation (e.g. <html><body><head><title>This is illegal</title></head></body></html>) ... you're only option is XML. * If you're working with: * Structured data (e.g. { name: "foo", bar: "Yes please!" } ) * Data from one or more sources that can happily coexist within a single namespace (e.g. { name: "foo", bar: "Yes please!", baz: [1, 2, 3] } ) * Data that doesn't require schema-based validation (e.g. { baz: [1, 2, 3], bar: "Yes please!", name: "foo" } ) Then use the format that is easier to work with from a developers perspective for the use case at hand. In most cases that means JSON, at least from a web development perspective, as you tend to be working directly with the data as is w/o need for further filtering and/or transformation. In /some/ cases that means XML as it /does/ require further filtering and/or transformation into something else. For the record, as big of a believer I am in the fact that XSLT actually /does/ cure cancer, from my own perspective when you're not required to use XML for the reasons mentioned above and yet you choose to just because it can easily be transformed into something else via XSLT you're making the wrong decision. Use JSON and if you find yourself in a situation where you actually need the power of XSLT to transform and/or filter the data represented by the JSON object, write a recursive function that converts the JSON object into a DOM object to then transform and/or filter it as you best see fit. Just my two cents. [1] http://msdn.microsoft.com/en-us/library/system.runtime.serialization.json(VS... -- /M:D M. David Peterson Co-Founder & Chief Architect, 3rd&Urban, LLC Email: m.david@3rdandUrban.com | m.david@amp.fm Mobile: (206) 999-0588 http://3rdandUrban.com | http://amp.fm | http://broadcast.oreilly.com/m-david-peterson/
pull in tens of thousands of lines of library code...
Nobody's forcing you to pull in any more code for one rendering than another - the Google GData clients have code for working with all of their 16 services and are Apache licensed
As I said this morning, GData libraries do exist for many platforms, but are not universal, and do run to tens of thousands of lines of code. I'm worried having a library of this size as a key dependency for OCCI when we could go with a much lighter meta-model (in either JSON or XML) and not require the library. All existing cloud APIs (Amazon, Sun, GoGrid, ElasticHosts, etc.) have specified their APIs directly over HTTP rather than over a pre-existing meta model. Should we really be pulling in a dependency which is this large when we have a clear choice not to? Richard.
Re: The meta-model - and it's related to current model discussions... This is somewhat incorrect - all providers provide access to their API's over HTTP yet their metamodels are not bound to HTTP in principle. I can send a XML model based on an XML-XSD metamodel over HTTP. I can send that same model over a different transport if I wanted to. The point here is that the model and the optional meta-model are not explicitly bound to the transport. Sun's models are specified in text [1]. They seem not to use an imported metamodel per say, possibly due to JSON's lack of a mechanism to define schemas (yes there's JSONSchema but not in wide use). In fact Sun's models are very suitable for many of OCCI's needs (as Ben Black noted). Amazon's [2] as embedded XSD in the WSDL based on W3C XSD (its meta model). All have models, some have metamodels and all are not inherently bound to a particular transport, just a default, prior-agreed one. Other than that I agree with keeping dependencies to a minimum, like you describe. Andy [1] http://kenai.com/projects/suncloudapis/pages/CloudAPISpecificationResourceMo... [2] http://soap.amazon.com/schemas2/AmazonWebServices.wsdl -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Richard Davies Sent: 12 May 2009 15:19 To: occi-wg@ogf.org Subject: Re: [occi-wg] Simple JSON rendering for OCCI
pull in tens of thousands of lines of library code...
Nobody's forcing you to pull in any more code for one rendering than another - the Google GData clients have code for working with all of their 16 services and are Apache licensed
As I said this morning, GData libraries do exist for many platforms, but are not universal, and do run to tens of thousands of lines of code. I'm worried having a library of this size as a key dependency for OCCI when we could go with a much lighter meta-model (in either JSON or XML) and not require the library. All existing cloud APIs (Amazon, Sun, GoGrid, ElasticHosts, etc.) have specified their APIs directly over HTTP rather than over a pre-existing meta model. Should we really be pulling in a dependency which is this large when we have a clear choice not to? Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
On Tue, May 12, 2009 at 4:19 PM, Richard Davies < richard.davies@elastichosts.com> wrote: I'm worried having a library of this size as a key dependency for OCCI when
we could go with a much lighter meta-model (in either JSON or XML) and not require the library.
The existing client libraries are a convenience, not a "key dependency" - you can use native XML parsers and only a few lines of code if you prefer and the result will look very similar to its JSON counterpart. I assure you there is no "much lighter meta-model", having gone through the process to arrive where we are today. Each resource has: - Common attributes (ID, Title) - Resource specific attributes (CPU Speed, Memory) - Taxonomical information (Categories) - Generic Links (to other resources as well as descriptor files, screenshots, console, snapshots, etc.) This maps perfectly to Atom and while I'm well aware of your concerns about generic links I quickly start running into problems when trying to describe screenshots, snapshots, consoles and other cruft we can't possibly hope to predict. Aside from that there is virtually no difference outside of the delimeters. All existing cloud APIs (Amazon, Sun, GoGrid, ElasticHosts, etc.) have
specified their APIs directly over HTTP rather than over a pre-existing meta model.
And Google? Microsoft? Salesforce? The fact they are all using AtomPub (two of them strategically) is a very strong message as to its suitability in heterogeneous cloud environments. Even VMware's vCloud is XML based so we know what the top end of town wants/needs/will end up using. What we need to find is the midpoint between the ElasticHosts API (plain text) and DMTF APIs (heavyweight XML) that satisfies the needs of all cloud infrastructure users... it's logical that this would end up being "just enough XML" rather than "a little bit more than plain text" (JSON). In fact it's worse than that... by going with JSON and ruling a line between private and public cloud in the form of a separate API for each we would essentially be forcing users to choose between the two. The only alternative then is for public cloud providers to implement DMTF's standards in order to reach the bigger fish as OCCI will be inadequate for their needs (enterprises still [believe they] have needs for stuff like IPX/SPX that we have no intention of specifying but should nonetheless allow for). Should we really be pulling in a dependency which is this large when we have
a clear choice not to?
XML support is natively present in any language worth using which is more than can be said for the alternative. Sam
On May 12, 2009, at 4:20 AM, Sam Johnston wrote:
These are both valid alternatives but given our ultimate aim is to reduce costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
You have argued on many occasions that mechanical transformation of the OCCI protocol data format is a key requirement. I've never understood why, and I've never engaged in a protocol design where this was an issue. Could you expand on why this matters? -Tim
On Tue, May 12, 2009 at 5:53 PM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 12, 2009, at 4:20 AM, Sam Johnston wrote:
These are both valid alternatives but given our ultimate aim is to reduce
costs it makes [a lot] more sense to have a primary format which supports mechanical transforms than to externalise the development to implementors (and then expect the results to be interoperable).
You have argued on many occasions that mechanical transformation of the OCCI protocol data format is a key requirement. I've never understood why, and I've never engaged in a protocol design where this was an issue. Could you expand on why this matters? -Tim
True, but I've also cited on many occasions use cases that rely on specific formats. Here's a dozen that come to mind and would otherwise have to be manually coded by each implementor: - Sysadmins conducting routine tasks with shell scripts (TXT) - Task scheduling with cron (TXT) - Automatic/autonomic task mechanisation, e.g. failover, recovery (TXT) - Users wanting to learn the API/kick the tyres by hand (TXT) - Exporting of [collections of] resources in arbitrary formats (OVF, VMX, etc.) - Documentation generation (ODF) - Report generation (PDF) - Diagramming (SVG) - Accounting (CSV) - Mapping to other protocols/implementations (EC2) - End user web interface (HTML) - End user RIA (XUL) - etc. As for standards, one could point at XML and the subsequent need to create XSLT ;) Sam
On May 12, 2009, at 9:09 AM, Sam Johnston wrote:
You have argued on many occasions that mechanical transformation of the OCCI protocol data format is a key requirement. I've never understood why, and I've never engaged in a protocol design where this was an issue. Could you expand on why this matters? -Tim
True, but I've also cited on many occasions use cases that rely on specific formats. Here's a dozen that come to mind and would otherwise have to be manually coded by each implementor:
Ah, I get it. I 100% agree that this is a problem. We thought about this a lot in the Sun-API design process. But ended up in a different place. We were pretty convinced that REST was the right basis for the API. It just can't be beat in terms of integration flexibility and network-friendliness. The problem is, a lot of programmers and sysadmins don't want to talk directly to a REST interface. So, what we did was write simple wrapper libraries in Java, Ruby, and Python (someone's working on PHP too) that give you VM, PrivateNetwork, Cluster, and so on classes wrapped around the REST/ JSON calls. Plus, a little command-line tool (in python, so it should run on anything) so you can say cloud_command --list --cluster Database cloud_command --attach --privateNetwork PN1 --vm Database/3X03 We'll be publishing those under an Apache2 license Real Soon Now. I'm unconvinced that auto-generation of different version of your protocols messages will be that much help to sysadmins and script- writers and so on, but you're closer to the use-cases than I am. -Tim
Sysadmins conducting routine tasks with shell scripts (TXT) Task scheduling with cron (TXT) Automatic/autonomic task mechanisation, e.g. failover, recovery (TXT) Users wanting to learn the API/kick the tyres by hand (TXT) Exporting of [collections of] resources in arbitrary formats (OVF, VMX, etc.) Documentation generation (ODF) Report generation (PDF) Diagramming (SVG) Accounting (CSV) Mapping to other protocols/implementations (EC2) End user web interface (HTML) End user RIA (XUL) etc. As for standards, one could point at XML and the subsequent need to create XSLT ;)
Sam
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
On Wed, May 13, 2009 at 1:56 AM, Tim Bray <Tim.Bray@sun.com> wrote:
On May 12, 2009, at 9:09 AM, Sam Johnston wrote:
You have argued on many occasions that mechanical transformation of the
OCCI protocol data format is a key requirement. I've never understood why, and I've never engaged in a protocol design where this was an issue. Could you expand on why this matters? -Tim
True, but I've also cited on many occasions use cases that rely on specific formats. Here's a dozen that come to mind and would otherwise have to be manually coded by each implementor:
Ah, I get it. I 100% agree that this is a problem. We thought about this a lot in the Sun-API design process. But ended up in a different place. We were pretty convinced that REST was the right basis for the API. It just can't be beat in terms of integration flexibility and network-friendliness. The problem is, a lot of programmers and sysadmins don't want to talk directly to a REST interface.
If the REST interface spits out a trivial format (eg KEY VALUE) then it's easily consumed by programmers, cron jobs, failover scripts, users at the command line, tools like cush <http://code.google.com/p/cush/>, etc. If it spits out anything more complex (XML, JSON) it's essentially useless for these use cases. Moral: support for multiple formats in the server makes the life of the clients much easier, especially since there are few server implementations to very many clients. Content negotiation works and exists with good reason.
So, what we did was write simple wrapper libraries in Java, Ruby, and Python (someone's working on PHP too) that give you VM, PrivateNetwork, Cluster, and so on classes wrapped around the REST/JSON calls. Plus, a little command-line tool (in python, so it should run on anything) so you can say
cloud_command --list --cluster Database cloud_command --attach --privateNetwork PN1 --vm Database/3X03
We'll be publishing those under an Apache2 license Real Soon Now.
That all sounds great for a packaged product (in which case the format over the wire could be completely obfuscated for all the user could care) but ideally APIs should be directly approachable by all users without the need for tooling. I'm unconvinced that auto-generation of different version of your protocols
messages will be that much help to sysadmins and script-writers and so on, but you're closer to the use-cases than I am.
It's hard to imagine all the possible use cases for OCCI but the ones we have already go somewhat further than what you've needed for the Sun Cloud APIs. There will certainly need to be extensible support for things like billing, monitoring, SLAs, etc. for example as well as good support for "supporting" (e.g. SNIA) as well as "competing" (e.g. OVF) standards. This is all handled seamlessly and safely with XML[NS] and can be validated as much as required. I could not be more convinced that JSON is not [yet] up to the task for OCCI (even if spot on for Sun Cloud APIs) but there's only so many ways I can say it before giving up and wandering off; I'm not going to invest time in a project I no longer believe in and/or have a use for but I don't want to keep the rest of you from reaching consensus any longer than I already have. Sam
On Tue, May 12, 2009 at 7:35 PM, Sam Johnston <samj@samj.net> wrote:
I could not be more convinced that JSON is not [yet] up to the task for OCCI (even if spot on for Sun Cloud APIs) but there's only so many ways I can say it before giving up and wandering off;
FWIW, I'm now 100% behind you on this. And I fear the wrath of no one -- Well, as long as their name isn't Tim Bray. For what I assume are obvious reasons when it comes to the XML space, Tim's wrath I doth fear. ;-) But to everyone else. Bring it, bitches! ;-) (said and meant in the most loving and caring sense of the word, of course :-) -- /M:D M. David Peterson Co-Founder & Chief Architect, 3rd&Urban, LLC Email: m.david@3rdandUrban.com | m.david@amp.fm Mobile: (206) 999-0588 http://3rdandUrban.com | http://amp.fm | http://broadcast.oreilly.com/m-david-peterson/
Richard, (+Krishna, +Colleen) On Fri, May 8, 2009 at 4:41 PM, Richard Davies <richard.davies@elastichosts.com> wrote:
The list has thankfully gone quiet, so I've recounted the votes since my previous post. We are now at:
10 JSON, 5 XML, 2 TXT
I don't consider this as a vote for a decision, but do think it has drawn out a lot of opinions and shown the lay of the land more clearly - in the light of the votes, the only two viable options are:
- Single-format: JSON - Multi-format: JSON + XML + ?TXT
The list has also been fairly evenly split on whether multiple format support makes sense or not (independent of the choice of the single format).
I shall post separately a defence of the "single format for interoperability" position.
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
I think it is essential that a JSON rendering is produced, treating it as a primary format for interop on the wire. This is the case, regardless of any other aspects of this discussion. One good reason is: Those of us proposing JSON as a primary format cannot expect a fair hearing from the XML-preferring folks unless this rendering is concrete, visible and examinable in its specifics.
There is still work here - e.g. verbs and attributes on networks have not been specified, nor have we agreed fully the _model_ of how we link servers to storage and networks.
Thanks to Alexander Papaspyrou, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000461.html http://www.ogf.org/pipermail/occi-wg/2009-May/000444.html
OK. So on the model - I am asking everyone to take future Model discussions into a separate thread. Please. And where possible - put it on the wiki and refer to that in your email. Let's keep the emails short and on one point at a time please, if possible. I'm going to go through a few emails on this thread with the same requests - park it, move it onto another thread, etc.
2) The JSON vs. XML debate is not just about angle-brackets vs. curly-brackets.
Agreed. Indeed: The argument that "JSON and XML differ only in their syntax, therefore one must be better than the other", implies that when considering JSON vs XML, syntax should be the primary concern. But syntax has nothing to do with interop, which is about data. Syntax has a lot to do with integration, which is a whole 'nother thing. I think at least 50% of our recent debates have failed to correctly separate integration from interop., and that mixing the two is one way to get you into a WS-mess. More on this on another thread.
Amongst the XML supporters, I have seen little opposition to a GData/Atom meta-model around the nouns/verbs/attributes. [Tim Bray, who co-chaired the IETF Atom working group, felt it was the wrong choice, but then he doesn't support using XML at all in this context]
However, many(/all?) of the JSON supporters seem to want a lighter meta-model around the nouns/verbs/attributes. For instance, they would probably prefer fixed actuator URLs to passing these in the feed, and would likely transmit flatter hashes of noun attributes rather than following Atom conventions the structure of links, attributes, etc. within an object.
I think this is the second and possibly more fundamental area of disagreement. * The former crew see the verbs primarily as CRUD, and the *resource* metamodel as resource links. * The latter want a more RESTful approach (not just CRUD/HTTP), in which the *application* metamodel is commingled with the protocol itself and the execution of the application model is hypertext navigation (HATEOAS). * Recall that "A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). …" I think this is a sufficiently interesting discussion that we should take it onto a separate thread. There are a number of concerns and ideas all kicking around: feeds, performance of multiple calls, how to scale to deal with huge collections, the possible relevance of and integration into GData, and how we'd like to convince Google to get involved. Let's move ALL this onto a new thread please. Again - keep your emails short or at least split them into specific points. Please.
Thanks to Ben Black, Andy Edmonds: http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html
My conclusion from this is that we should not develop the JSON rendering in terms of an XSLT transform from the XML rendering, and should not go for "GData-JSON". We will need these automatic transforms eventually, but we should develop the JSON rendering in its own right, thinking about what works well for JSON, and then later work out how we'll auto transform back and forth.
FOR NOW ... I want us to focus on: * Model - nouns, verbs etc * Interoperability This can be deemed OCCI-DRAFT-0-1 DISCUSSION points: * Metamodel (interesting but could take time) * Integration As mentioned I think we have been mixing Integration with Interoperability and this is bad.
Do the 10 JSON supporters agree with this, or have I misjudged it and there is actually strong support for GData-JSON?
Separate thread please.
Myself and Chris would be happy to lead developing the JSON rendering it its own right if people agree with my statements above and hence that it does need independent development (from the same set of nouns/verb/attributes and semantics).
Please could you do that. I think it needs development. Not sure about 'independent'.. there is no need to go off on your own, leadership involves dialogue please :-)
3) I suggest we(/I!) stop discussing TXT for now. If we go multi-format then we should probably have it, but Chris has demonstrated how it can be trivially transformed back and forth from JSON.
Agreed. Let's park TXT. Thanks Chris. And thanks Richard - good summary. Please crack on guys! alexis
==========================================
JSON: 10 - Alexis Richardson http://www.ogf.org/pipermail/occi-wg/2009-May/000405.html - Andy Edmonds http://www.ogf.org/pipermail/occi-wg/2009-May/000420.html - Ben Black http://www.ogf.org/pipermail/occi-wg/2009-May/000395.html - Krishna Sankar http://www.ogf.org/pipermail/occi-wg/2009-May/000455.html - Mark Masterson http://www.ogf.org/pipermail/occi-wg/2009-May/000440.html - Michael Richardson (private mail to me) - Randy Bias? (JSON listed first at http://wiki.gogrid.com/wiki/index.php/API:Anatomy_of_a_GoGrid_API_Call) - Richard Davies http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote) - Tino Vazquez? http://www.ogf.org/pipermail/occi-wg/2009-May/000411.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html
XML: 5 - Chuck W http://www.ogf.org/pipermail/occi-wg/2009-May/000448.html - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000470.html - Kristoffer Sheather http://www.ogf.org/pipermail/occi-wg/2009-May/000430.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000381.html - William Vambenepe http://www.ogf.org/pipermail/occi-wg/2009-May/000396.html
TXT: 2 - Andre Merzky http://www.ogf.org/pipermail/occi-wg/2009-May/000447.html - Chris Webb http://www.ogf.org/pipermail/occi-wg/2009-May/000409.html (split EH vote)
Single: 3 - Benjamin Black http://www.ogf.org/pipermail/occi-wg/2009-May/000457.html - Tim Bray http://www.ogf.org/pipermail/occi-wg/2009-May/000418.html - Richard Davies (revised in light of Tim Bray's comments)
Multi: 3 - Gary Mazz http://www.ogf.org/pipermail/occi-wg/2009-May/000458.html - Marc-Elian Begin http://www.ogf.org/pipermail/occi-wg/2009-May/000439.html - Sam Johnston http://www.ogf.org/pipermail/occi-wg/2009-May/000445.html _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Quoting [Alexis Richardson] (May 09 2009):
I see three conclusions going forward:
1) Continue our specification in terms of the model (nouns, verbs, attributes, semantics of these, how these are linked together) with both JSON and XML renderings of this being explored on the wiki. We can decide later if we run with both or just JSON.
I think it is essential that a JSON rendering is produced, treating it as a primary format for interop on the wire. This is the case, regardless of any other aspects of this discussion.
One good reason is: Those of us proposing JSON as a primary format cannot expect a fair hearing from the XML-preferring folks unless this rendering is concrete, visible and examinable in its specifics.
Well, to be fair: the XML folx could say the same ;-) Andre -- Nothing is ever easy.

Tim Bray wrote:
3. General advice on making standards
3.1 Dare to do less. Consider Gall's Law. Try to hit 80/20 points. Build "The simplest thing that could possibly work". When in doubt, leave it out.
This is my major concern with the route which OCCI has been heading to date. When the group was set up, I understood that our aim was to quickly write down and agree the common core between existing IaaS APIs: Amazon, Sun, GoGrid, ElasticHosts, etc. We've done some work in that direction (the nouns, verbs and attributes), but have also proposed a lot which would be going beyond what any/most IaaSes have actually implemented to date. For example: embedding of OVF, proposed extensions such as a search service, billing and reporting. We shouldn't be working on these - we should stick to 3 nouns, ~15 verbs, ~15 attributes (of which we have a good draft) and should wrap these in the simplest possible wire format (e.g. fix actuator URLs for each verb. Represent nouns as a single level JSON hash listing the attributes as key-value pairs). See the ElasticHosts application/json format at http://www.elastichosts.com/products/api for how simple this can be (or equivalently GoGrid, Sun, etc. - though I believe that Sun's JSON has unnecessarily deep data structures). Then we should declare victory and go home! Richard.
Richard, On Thu, May 7, 2009 at 10:01 AM, Richard Davies <richard@daviesmail.org> wrote:
When the group was set up, I understood that our aim was to quickly write down and agree the common core between existing IaaS APIs: Amazon, Sun, GoGrid, ElasticHosts, etc.
We've done some work in that direction (the nouns, verbs and attributes),
And this is good.
but have also proposed a lot which would be going beyond what any/most IaaSes have actually implemented to date.
For example: embedding of OVF, proposed extensions such as a search service, billing and reporting.
The OVF thing is partly to do with our charter. But I am not convinced as to the right course of action *today*. You could just knock out a codegen to map OVF to JSON ;-)
We shouldn't be working on these - we should stick to 3 nouns, ~15 verbs, ~15 attributes (of which we have a good draft) and should wrap these in the simplest possible wire format (e.g. fix actuator URLs for each verb. Represent nouns as a single level JSON hash listing the attributes as key-value pairs).
See the ElasticHosts application/json format at http://www.elastichosts.com/products/api for how simple this can be (or equivalently GoGrid, Sun, etc. - though I believe that Sun's JSON has unnecessarily deep data structures).
Then we should declare victory and go home!
I assume you have a flight suit to hand ;-) a
Richard. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
Clone is dangerous. Please define what you mean. As far as I can tell everyone means something difference. For pass one I'd prefer to avoid verbs that aren't very specific, like 'stop'. Heck, even with stop we have differences. 'Clone' is incredibly overloaded and has lots of expectations associated with it. --Randy On 5/6/09 9:01 AM, "Tino Vazquez" <tinova@fdi.ucm.es> wrote:
Hi everyone,
I would like to see a clone verb (or maybe attribute, not sure about this) for drives, also maybe as an extension. I'm thinking on implementations sharing images using shared storage, this will allow to use those images directly, and obviously "cloning" set to "no" will make this image persistent automatically. What do you think?
About the choice of format, as much as I like XML and Atom specially, I would advocate for the "simpler is nicer" principle is there is nothing that proves that it can do things that simple text or even JSON (from which I can see benefits for machine and human readibility) simply can´t, which also I haven't seen so far (Sam, please, correct me if I am wrong).
Regards,
-Tino
-- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org
On Wed, May 6, 2009 at 6:18 PM, Chris Webb <chris.webb@elastichosts.com> wrote:
Alexis Richardson <alexis.richardson@gmail.com> writes:
Chris, if you think we have a choice to make please could you describe the options we have to choose from in more detail.
I think Richard has just beaten me to it! However, more generally, I think that before we can even have these discussions about formats, we should confirm that we're all on the same page with regard to the semantic building blocks:
http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/NounsVe rbsAndAttributes
I think Richard, Sam, Andy and I have all hacked at this page. Would anyone else like to comment or is there general consensus around these basic nouns, verbs and attributes?
Cheers,
Chris. _______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
Hi Randy, By "clone" I mean "copy the image" if set to yes or "use the original" if set to no. What other meaning do you have in mind? Also, for me "stop" means stop the VM and dump the state onto a file. "suspend" would be stop it but keep the state in memory. BTW, there is something in state machine diagram [1] that I still don't understand. The entry point (after start) I take it as the "defined" or "pending" state. If that is correct, then we have our VMs going always from the initial state to "suspended". Is that what we want? Regards, -Tino [1] http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/StateMo... -- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org On Thu, May 7, 2009 at 1:29 AM, Randy Bias <randyb@gogrid.com> wrote:
dange
First off, we've got to be careful about saying 'copy the image'. You probably mean 'copy the instance'. Where an image is an on-disk representation of an unpowered VM and an instance is a running version of that same on-disk representation or a running copy. So for 'cloning' do you mean: - An image in a library is turned into an instance? - A running instance is copied? - If a running instance is copied do you have a new image or a new instance? - If you have a new instance, is it powered on automatically? - Does a new cloned instance have the exact same hardware profile as the original cloned instance? RAM, CPU, disk? - Does a cloned instance also duplicate the RAM? In other words, am I making a PURE 100% duplicated running instance (there are use cases for this), a new reference image, or am I 'scaling' an instance (either horizontally with more copies or vertically with a bigger copy)? I've seen clone used by customers, clouds, and various IT departments and I've almost never seen the same definition. It's about as bad as 'cloud' when it comes to being defined. When our customers ask for cloning they also usually mean very different things. I'd rather have a few different verbs here that specified different behavior and that's potentially a rat's nest because not every cloud supports all of these behaviors. --Randy On 5/7/09 12:44 AM, "Tino Vazquez" <tinova@fdi.ucm.es> wrote:
Hi Randy,
By "clone" I mean "copy the image" if set to yes or "use the original" if set to no. What other meaning do you have in mind?
Also, for me "stop" means stop the VM and dump the state onto a file. "suspend" would be stop it but keep the state in memory.
BTW, there is something in state machine diagram [1] that I still don't understand. The entry point (after start) I take it as the "defined" or "pending" state. If that is correct, then we have our VMs going always from the initial state to "suspended". Is that what we want?
Regards,
-Tino
[1]
http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/StateMode> l
-- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org
On Thu, May 7, 2009 at 1:29 AM, Randy Bias <randyb@gogrid.com> wrote:
dange
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
I'm in agreement with Randy's comment. Terms like snapshot, clone, duplicate, replicate, all have different meanings when looking under the covers. Some are misnomers while others are defining solutions in terms of defensible solutions. To be clear, more complete feature should have a definition of terms or a model that defines properties which differentiates the variations, something that can be described in the occi rendering format -gary Randy Bias wrote:
First off, we've got to be careful about saying 'copy the image'. You probably mean 'copy the instance'. Where an image is an on-disk representation of an unpowered VM and an instance is a running version of that same on-disk representation or a running copy.
So for 'cloning' do you mean:
- An image in a library is turned into an instance? - A running instance is copied? - If a running instance is copied do you have a new image or a new instance? - If you have a new instance, is it powered on automatically? - Does a new cloned instance have the exact same hardware profile as the original cloned instance? RAM, CPU, disk? - Does a cloned instance also duplicate the RAM?
In other words, am I making a PURE 100% duplicated running instance (there are use cases for this), a new reference image, or am I 'scaling' an instance (either horizontally with more copies or vertically with a bigger copy)?
I've seen clone used by customers, clouds, and various IT departments and I've almost never seen the same definition. It's about as bad as 'cloud' when it comes to being defined.
When our customers ask for cloning they also usually mean very different things.
I'd rather have a few different verbs here that specified different behavior and that's potentially a rat's nest because not every cloud supports all of these behaviors.
--Randy
On 5/7/09 12:44 AM, "Tino Vazquez" <tinova@fdi.ucm.es> wrote:
Hi Randy,
By "clone" I mean "copy the image" if set to yes or "use the original" if set to no. What other meaning do you have in mind?
Also, for me "stop" means stop the VM and dump the state onto a file. "suspend" would be stop it but keep the state in memory.
BTW, there is something in state machine diagram [1] that I still don't understand. The entry point (after start) I take it as the "defined" or "pending" state. If that is correct, then we have our VMs going always from the initial state to "suspended". Is that what we want?
Regards,
-Tino
[1]
http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/StateMode> l
-- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org
On Thu, May 7, 2009 at 1:29 AM, Randy Bias <randyb@gogrid.com> wrote:
dange

Hi Randy, First of all, excuse me for the delayed answer. This thread somehow ended up in my Trash folder, not really sure why (?). Comments interspersed, On Sun, May 10, 2009 at 12:10 AM, Randy Bias <randyb@gogrid.com> wrote:
First off, we've got to be careful about saying 'copy the image'. You probably mean 'copy the instance'. Where an image is an on-disk representation of an unpowered VM and an instance is a running version of that same on-disk representation or a running copy.
So for 'cloning' do you mean:
- An image in a library is turned into an instance? - A running instance is copied? - If a running instance is copied do you have a new image or a new instance? - If you have a new instance, is it powered on automatically? - Does a new cloned instance have the exact same hardware profile as the original cloned instance? RAM, CPU, disk? - Does a cloned instance also duplicate the RAM?
I really mean copy the image, as it is a suggestion for an attribute of the "Drive" object. AFAIK, the clone attribute has been already suggested for the "Server" object (BTW, wouldn't it be better to call it VirtualMachine instead of Server?). So, as I see it Drive object -> clone attribute. Set to yes: "Copy the on-disk representation of one drive of a VM" Set to no: "Use the original on-disk representation of one drive of a VM" As I see it , one VM can have more than one drive, it is not its complete representation (I mean, it can be, but it doesn't have to). I suggested it because I can see the benefits of declaring the base system drive of a VM as cloneable (so it can be used by different VMs) but each VM having their data partition set as not clonable and each VM use their own one (not sure if we should introduce the concept of "shareable", it is quite a dangerous field). And other combination also. The cloning attribute for "Servers" has to be correctly defined, and I suggest using your questions as a starting point to unequivocally do so. It just got me thinking, VMWare uses the concept of Template aside from the VirtualMachine, with the purpose of making clones. How do you feel about this?
In other words, am I making a PURE 100% duplicated running instance (there are use cases for this), a new reference image, or am I 'scaling' an instance (either horizontally with more copies or vertically with a bigger copy)?
In this case, I guess I was talking about a new reference image.
I've seen clone used by customers, clouds, and various IT departments and I've almost never seen the same definition. It's about as bad as 'cloud' when it comes to being defined.
I understand you concern. I think that the purpose of this working group is to precisely define these concepts, as good as we can do i. I really think that the "clone" attribute for drives is a good complement for the "persistent" one.
When our customers ask for cloning they also usually mean very different things.
Precisely, we have to give them meaning as what we find more reasonable.
I'd rather have a few different verbs here that specified different behavior and that's potentially a rat's nest because not every cloud supports all of these behaviors.
That is true, I suggest using it as a extension. We will therefore avoid further ill-defined "clone" attributes for different clouds. That is, IMHO, what standards are for.
--Randy
Thanks, I think this is a rather productive discussion. - Tino
On 5/7/09 12:44 AM, "Tino Vazquez" <tinova@fdi.ucm.es> wrote:
Hi Randy,
By "clone" I mean "copy the image" if set to yes or "use the original" if set to no. What other meaning do you have in mind?
Also, for me "stop" means stop the VM and dump the state onto a file. "suspend" would be stop it but keep the state in memory.
BTW, there is something in state machine diagram [1] that I still don't understand. The entry point (after start) I take it as the "defined" or "pending" state. If that is correct, then we have our VMs going always from the initial state to "suspended". Is that what we want?
Regards,
-Tino
[1]
http://forge.gridforum.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/StateMode> l
-- Constantino Vázquez, Grid Technology Engineer/Researcher: http://www.dsa-research.org/tinova DSA Research Group: http://dsa-research.org Globus GridWay Metascheduler: http://www.GridWay.org OpenNebula Virtual Infrastructure Engine: http://www.OpenNebula.org
On Thu, May 7, 2009 at 1:29 AM, Randy Bias <randyb@gogrid.com> wrote:
dange
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
Chris, I think we made good progress in today's call and addressed many of the issues that Andy and Richard had (feel free to correct me if I'm wrong). On Wed, May 6, 2009 at 4:34 PM, Chris Webb <chris.webb@elastichosts.com>wrote:
It's a great shame Ben hasn't joined the occi-wg so far. I'd like to put on the record my strong agreement with his points quoted above. I share his horror at the idea of accessing a simple API to a simple service via two layers of complex container formats, and agree that there has been no technical argument for this other than vague and thoroughly unconvincing references to 'enterprise users' and 'extensibility'.
I'd love to see Ben, Tim and all the other [potential] stakeholders involved as well and hope/suspect they will be before long. To clarify, nobody's talking about "two layers of complex container formats", rather HTTP (which is assumed - I don't think there's any contention whatsoever about building on top of HTTP; at least there shouldn't be) and a very light layer of XML soley to provide sufficient common metadata for all resources (id, title, updated, etc.) as well as a mechanism to realise our model by way of links (with attributes on both the resources and the links between them). I assure you that if you were to try to do this from scratch in XML (as Andy suggested on the call) you will end up with something just like Atom anyway (I know because I did go through this very exercise), and that if it cannot be represented cleanly and completely in JSON and/or TXT formats then it will not be included... this places significant restrictions/controls on what is possible. I'd like to be able to give you better reasoning than I have already but what I'm trying to do is deliver enough standardisation for interoperability without stifling innovation... I don't plan to bury anything in the content element but if some enterprise user wants to take advantage of some of the work done over the last 10 years, be it WS-*, CIM, OVF or something to be developed at e.g. SNIA then that's fine by me... I certainly don't want to stop them or force them to implement multiple protocols to get the stuff done that we chose not to cover. And then of course there's the value of both [potentially] being able to get Google on board and taking advantage of their many thousands of man hours invested in GData clients already (simply by submitting patches to handle multiple namespaces). I'm going to leave you guys to it for a few hours while I take a train to Paris, but very much appreciate your involvement and the lively discussion, A bientôt, Sam
[from discussion Ben Black]
XML drags along an awful lot of baggage, which has resulted in many folks using lighter-weight formats like JSON. ATOM, in turns, lards still more baggage into the mix, again ... JSON has similarly moved well beyond its origins as something used by Javascript (see CouchDB for a great example). Finally, it is a simple, text-based system, far simpler than XML, and I have recent, painful experience in working in JSON and XML simultaneously for systems management.
A man after my own heart ;-) Seriously, I think the point here is that the Atom XML vs. simple JSON/TXT discussion is a typical unresolvable programmers' religious war. To caricature: - One camp will always believe that Atom XML is more flexible, extensible and Enterprise-ready, whilst being "simple enough". - The other camp will always believe that very basic JSON/TXT formats are much simpler, lower baggage and "flexible/extensible enough". OCCI will be used by programmers from both camps, so we need to meet both needs. Luckily on this mailing list we have Sam as a strong advocate of the first camp, and ElasticHosts as a strong advocate of the second ;-) As I have said before, my aim is that the XML, JSON and TXT formats should all share the same nouns, verbs and attributes, and should also be automatically translatable into each other, but beyond that each should be well designed in their own right. ElasticHosts will continue to fight strongly for the second camp in the JSON and TXT format, whilst deferring on most issues of taste in the XML format. I'd like to see members of the first camp fighting strongly in the XML format, but deferring on most issues of taste in the JSON and TXT formats. Cheers, Richard.
On May 6, 2009, at 6:37 AM, Sam Johnston wrote:
Au contraire, we are paying *very* close attention to the Sun Cloud APIs and originally wanted to draw from them heavily were it not for a disagreement with the OGF powers that be over Creative Commons licensing.
Huh? I find this hard to understand. Could you explain?
Sun's decision to use JSON no doubt stems from the fact that the API was previously consumed almost exclusively by the Q-Layer web interface
No. We started with XML and decided that JSON was a superior choice.
Oh and we are not at all wedded to OAuth - any HTTP authentication mechanism will do (though it may make sense for us to limit this somewhat for interoperability).
Actually, one of the nice things about using HTTP is that it allows you to do like AtomPub did and say "Use whatever you want as long as it's as strong as TLS", and let the (rich and growing) web-security marketplace sort it out.
So why go for angle brackets (XML) over curly braces (JSON) given most of the action is going on in the latter camp? In addition to the reasons given above, Google. That is, if we essentially rubber stamp GData (a well proven protocol) in the form of OCCI core
GData is all about CRUD. The reason this cloud stuff is interesting is that it has lots of non-CRUD stuff in it. Maybe I'm missing something, but the code around GData seems to live in a different universe from the one where cloud infrastructure lives. -Tim
The point regarding GData is one that I hinted at in the teleconf. It's a particular schema for describing the publication and syndication of content. With that (possibly simplistic view) in mind atom is not a natural fit, even though you can make it fit a model of a bunch of resources like compute, storage and network. I guess there is where the danger lies with atom, perhaps, it's quite generic and that can be very attractive, yet like the Sirens' song :-) On further reflection, my own personal preference is with a model that is domain-specific and has as little dependencies as is possible. Something not much more simple as the one under the nouns, verbs, attribute wiki page (naturally extended with concrete types (nouns) and annotating links between entities) [1]. What is very apparent is that there are more positive calls for JSON than XML imho. Tim has provided a very useful means to choose a suitable rendering of the OCCI model and should be digested by all. Regarding the licensing issue, if there is/were issues any of SLA@SOI contributions would be invalid as they too are released under CC-Attrib. Regarding optional features, that makes sense. However I do see the value in offer a means to allow for extensions/plugins. Andy [1] http://forge.ogf.org/sf/wiki/do/viewPage/projects.occi-wg/wiki/NounsVerbsAnd... -----Original Message----- From: occi-wg-bounces@ogf.org [mailto:occi-wg-bounces@ogf.org] On Behalf Of Tim Bray Sent: 06 May 2009 18:40 To: Sam Johnston Cc: occi-wg@ogf.org Subject: Re: [occi-wg] Is OCCI the HTTP of Cloud Computing? On May 6, 2009, at 6:37 AM, Sam Johnston wrote:
Au contraire, we are paying *very* close attention to the Sun Cloud APIs and originally wanted to draw from them heavily were it not for a disagreement with the OGF powers that be over Creative Commons licensing.
Huh? I find this hard to understand. Could you explain?
Sun's decision to use JSON no doubt stems from the fact that the API was previously consumed almost exclusively by the Q-Layer web interface
No. We started with XML and decided that JSON was a superior choice.
Oh and we are not at all wedded to OAuth - any HTTP authentication mechanism will do (though it may make sense for us to limit this somewhat for interoperability).
Actually, one of the nice things about using HTTP is that it allows you to do like AtomPub did and say "Use whatever you want as long as it's as strong as TLS", and let the (rich and growing) web-security marketplace sort it out.
So why go for angle brackets (XML) over curly braces (JSON) given most of the action is going on in the latter camp? In addition to the reasons given above, Google. That is, if we essentially rubber stamp GData (a well proven protocol) in the form of OCCI core
GData is all about CRUD. The reason this cloud stuff is interesting is that it has lots of non-CRUD stuff in it. Maybe I'm missing something, but the code around GData seems to live in a different universe from the one where cloud infrastructure lives. -Tim
_______________________________________________ occi-wg mailing list occi-wg@ogf.org http://www.ogf.org/mailman/listinfo/occi-wg ------------------------------------------------------------- Intel Ireland Limited (Branch) Collinstown Industrial Park, Leixlip, County Kildare, Ireland Registered Number: E902934 This e-mail and any attachments may contain confidential material for the sole use of the intended recipient(s). Any review or distribution by others is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
Here's another insightful reply from William Vambenepe: Speaking of WS-*, I don't think it's a selfish plug for me to point you
towards the post in which I examine how previous efforts (mainly around WS-*) can inform Cloud standards going forward. It is very relevant to what you write here. When I read this paragraph:
"Enter the OGF's Open Cloud Computing Interface (OCCI) whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things."
... I am a bit worried because you describe the whole field of IT modeling and interoperability as we've tried to capture it for the last decade. So when I see that you plan to "deliver an implementable draft this month" I get a little worried.
Anyway, here is the "lessons to learn" post, titled "A post-mortem on the previous IT management revolution": http://stage.vambenepe.com/archives/700Among other things, beware on focusing on protocols rather than models, beware of working without clear use cases and beware of trying to address broad problems rather than constrained problems. BTW, I am not saying that you are doing these things and I haven't looked at the working documents on the OCCI site. These are just thoughts that come to mind from reading this blog entry.
And his blog post: A post-mortem on the previous IT management revolution<http://stage.vambenepe.com/archives/700> by
William Vambenepe
Before rushing to standardize “Cloud APIs”, let’s take a look back at the previous attempt to tackle the same problem, which is one of IT management integration and automation. I am referring to the definition of specifications that attempted to use the then-emerging SOAP-based Web services framework to easily integrate IT management systems and their targets.
Leaving aside the “Cloud” spin of today and the “Web services” frenzy of yesterday, the underlying problem remains to provide IT services (mostly applications) in a way that offers the best balance of performance, availability, security and economy. Concretely, it is about being able to deploy whatever IT infrastructure and application bits need to be deployed, configure them and take any required ongoing action (patch, update, scale up/down, optimize…) to keep them humming so customers don’t notice anything bothersome and you don’t break any regulation. Or rather so that any disruption a customer sees and any mandate you violate cost you less than it would have cost to avoid them.
The realization that IT systems are moving more and more towards distributed/connected applications was the primary reason that pushed us towards the definition of Web services protocols geared towards management interactions. By providing a uniform and network-friendly interface, we hoped to make it convenient to integrate management tasks vertically (between layers of the IT stack) and horizontally (across distributed applications). The latter is why we focused so much on managing new entities such as Web services, their execution environments and their conversations. I’ll refer you to the WSMF submission<http://xml.coverpages.org/ni2003-07-21-a.html>that my HP colleagues and I made to OASIS in 2003 for the first consistent definition of such a management framework. The overview white paper<http://xml.coverpages.org/WSMF-Overview.pdf>even has a use case called “management as a service” if you’re still not convinced of the alignment with today’s Cloud-talk.
Of course there are some differences between Web service management protocols and Cloud APIs. Virtualization capabilities are more advanced than when the WS effort started. The prospect of using hosted resources is more realistic (though still unproven as a mainstream business practice). Open source component are expected to play a larger role. But none of these considerations fundamentally changes the task at hand.
Let’s start with a quick round-up and update on the most relevant efforts and their status.
*Protocols*
WSMF <http://xml.coverpages.org/ni2003-07-21-a.html> (Web Services Management Framework): an HP-created set of specifications, submitted to the OASIS WSDM working group (see below). Was subsumed into WSDM. Not only a protocol BTW, it includes a basic model for Web services-related artifacts.
WS-Manageability<http://www.ibm.com/developerworks/library/specification/ws-manage/>: An IBM-led alternative to parts of WSDM, also submitted to OASIS WSDM.
WSDM <http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsdm>(Web Services Distributed Management): An OASIS technical committee. Produced two standards (a protocol, “Management Using Web Services” and a model of Web services, “Management Of Web Services”). Makes use of WSRF (see below). Saw a few implementations but never achieved real adoption.
OGSI <http://www.ggf.org/documents/GFD.15.pdf> (Open Grid Services Infrastructure): A GGF (the organization now known as OGF) standard to provide a service-oriented resource manipulation infrastructure for Grid computing. Replaced with WSRF.
WSRF <http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsrf>: An OASIS technical committee which produced several standards (the main one is WS-ResourceProperties). Started as an attempt to align the GGF/OGSI approach to resource access with the IT management approach (represented by WSDM). Saw some adoption and is currently quietly in use under the cover in the GGF/OGF space. Basically replaced OGSI but didn’t make it in the IT management world because its vehicle there, WSDM, didn’t.
WS-Management <http://www.dmtf.org/standards/wsman>: A DMTF standard, based on a Microsoft-led submission. Similar to WSDM in many ways. Won the adoption battle with it. Based on WS-Transfer and WS-Enumeration.
WS-ResourceTransfer<http://schemas.xmlsoap.org/ws/2006/08/resourceTransfer/WS-ResourceTransfer.pdf>(aka WS-RT): An attempt to reconcile <http://xml.coverpages.org/WSM-HarmonizationRoadmap200603.pdf>the underlying foundations of WSDM and WS-Management. Stalled as a private effort (IBM, Microsoft, HP, Intel). Was later submitted to the W3C WS-RA working group (see below).
WSRA <http://www.w3.org/2002/ws/ra/> (Web Services Resource Access): A W3C working group created to standardize the specifications that WS-Management is built on (WS-Transfer etc) and to add features to them in the form of WS-RT (which was also submitted there, in order to be finalized). This is (presumably) the last attempt at standardizing a SOAP-based access framework for distributed resources. Whether the window of opportunity to do so is still open is unclear. Work is ongoing.
WS-ResourceCatalog<http://schemas.xmlsoap.org/ws/2007/05/ResourceCatalog/WS-ResourceCatalog.pdf>: A discovery helper companion specification to WS-Management. Started as a Microsoft document, went through the “WSDM/WS-Management reconciliation” effort, emerged as a new specification that was submitted to DMTF<http://stage.vambenepe.com/archives/110>in May 2007. Not heard of since.
CMDBf<http://www.dmtf.org/standards/published_documents/DSP0252_1.0.0c.pdf>(Configuration Management Database Federation): A DMTF working group (and soon to be standard) that mainly defines a SOAP-based protocol to query repositories of configuration information. Not linked with (or dependent on) any of the specifications listed above (it is debatable whether it belongs in this list or is part of a new breed).
*Modeling*
DCML <http://www.dcml.org/> (Data Center Markup Language): The first comprehensive effort to model key elements of a data center, their relationships and their policies. Led by EDS and Opsware. Never managed to attract the major management vendors. Transitioned to an OASIS member section and died of being ignored.
SDM <http://msdn.microsoft.com/en-us/library/ms181772%28VS.80%29.aspx>(System Definition Model): A Microsoft specification to model an IT system in a way that includes constraints and validation, with the goal of improving automation and better linking the different phases of the application lifecycle. Was the starting point for SML.
SML <http://www.w3.org/XML/SML/> (Service Modeling Language): Currently a W3C “proposed recommendation” (soon to be a recommendation, I assume) with the same goals as SDM. It was created, starting from SDM, by a consortium of companies that eventually submitted it<http://www.w3.org/Submission/2007/01/>to W3C. No known adoption other than the Eclipse COSMOS <http://www.eclipse.org/cosmos/resource_modeling/index.php> project (Microsoft was supposed to use it, but there hasn’t been any news on that front for a while). Technically, it is a combination of XSD and Schematron. It appears dead, unless it turns out that Microsoft is indeed using it (I don’t know whether System Center is still using SDM, whether they are adopting SML, whether they are moving towards M or whether they have given up on the model-centric vision).
CML (Common Model Library): An effort by the SML authors to create a set of model elements using the SML metamodel. Appears to be dead (no news in a long time and the cml-project.org domain name that was used seems abandoned).
SDD <http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=sdd>(Solution Deployment Descriptor): An OASIS standard to define a packaging mechanism meant to simplify the deployment and configuration of software units. It is to an application archive what OVF is to a virtual disk. Little adoption that I know of, but maybe I have a blind spot on this.
OVF <http://www.dmtf.org/standards/published_documents/DSP0243_1.0.0.pdf>(Open Virtualization Format): A recently released <http://xml.coverpages.org/DMTF-OVFv10-Standard.html> DMTF standard. Defines a packaging and descriptor format to distribute virtual machines. It does not defined a common virtual machine format, but a wrapper around it. Seems to have some momentum. Like CMDBf, it may be best thought of as part of a new breed than directly associated with WS-Management and friends.
This is not an exhaustive list. I have left aside the eventing aspects (WS-Notification, WS-Eventing, WS-EventNotification) because while relevant it is larger discussion and this entry to too long already (see here<http://blog.elementallinks.net/2008/09/epts-event-pr-3.html>and here<http://travisspencer.com/blog/2008/11/effort-to-converge-ws-eventing.html>for some updates from late last year on the eventing front). It also does not cover the Grid work (other than OGSI/WSRF to the extent that they intersect with the IT management world), even though a lot of the work that took place there is just as relevant to Cloud computing as the IT management work listed above. Especially CDDLM/CDL<http://www.ggf.org/documents/GFD.127.pdf>an abandoned effort to port SmartFrog <http://smartfrog.org/> to the then-hot XML standards, from which there are plenty of relevant lessons to extract.
*The lessons*
What does this inventory tell us that’s relevant to future Cloud API standardization work? The first lesson is that protocols are easy and models are hard. WS-Management and WSDM technically get the job done. CMDBf will be a good query language. But none of the model-related efforts listed above seem to have hit the mark of “doing the job”. With the possible exception of OVF which is promising (though the current expectations on it<http://news.cnet.com/8301-1001_3-10216049-92.html?part=rss&subj=news&tag=2547-1_3-0-20>are often beyond what it really delivers<http://devcentral.f5.com/weblogs/macvittie/archive/2009/04/21/ovf-a-few-layers-short-of-a-full-stack.aspx>). In general, the more focused and narrow a modeling effort is, the more successful it seems to be (with OVF as the most focused of the list and CML as the other extreme). That’s lesson learned number two: models that encompass a wide range of systems are attractive, but impossible to deliver. Models that focus on a small sub-area are the way to go. The question is whether these specialized models can at least share a common metamodel or other base building blocks (a type system, a serialization, a relationship model, a constraint mechanism, etc), which would make life easier for orchestrators. SML tries (tried?) to be all that, with no luck. RDF could be all that, but hasn’t managed to get noticed in this context. The OVF and SDD examples seems to point out that the best we’ll get is XML as a shared foundation (a type system and a serialization). At this point, I am ready to throw the towel on achieving more modeling uniformity than XML provides, and ready to do the needed transformations in code instead. At least until the next window of opportunity arrives.
I wish that rather than being 80% protocols and 20% models, the effort in the WS-based wave of IT management standards had been the other way around. So we’d have a bit more to show for our work, for example a clear, complete and useful way to capture the operational configuration of application delivery services (VPN, cache, SSL, compression, DoS protection…). Even if the actual specification turns out to not make it, its content should be able to inform its successor (in the same way that even if you don’t use CIM to model your server it is interesting to see what attributes CIM has for a server).
It’s less true with protocols. Either you use them (and they’re very valuable) or you don’t (and they’re largely irrelevant). They don’t capture domain knowledge that’s intrinsically valuable. What value does WSDM provide, for example, now that’s it’s collecting dust? How much will the experience inform its successor (other than trying to avoid the WS-Addressing disaster)? The trend today seems to be that a more direct use of HTTP (”REST”) will replace these protocols. Sure. Fine. But anyone who expects this break from the past to be a vaccination against past problems is in for a nasty surprise. Because, and I am repeating myself, *it’s the model, stupid*. Not the protocol. Something I (hopefully) explained in my comments on the Sun Cloud API <http://stage.vambenepe.com/archives/632>(before I knew that caring about this API might actually become part of my day job) and something on which I’ll come back in a future post.
Another lesson is the need for clear use cases. Yes, it feels silly to utter such an obvious statement. But trust me, standards groups still haven’t gotten this. It’s not until years spent on WSDM and then WS-Management that I realized that most people were not going after management integration, as I was, but rather manageability. Where “manageability” is concerned with discovering and monitoring individual resources, while “management integration” is concerned with providing a systematic view of the environment, with automation as the goal. In other words, manageability standards can allow you to get a traditional IT management console without the need for agents. Management integration standards can allow you to coordinate your management systems and automate their orchestration. WS-Management is for manageability. CMDBf is in the management integration category. Many of the (very respectful and civilized) head-butting sessions I engaged in during the WSDM effort can be traced back to the difference between these two sets of use cases. And there is plenty of room for such disconnect in the so-loosely-defined “Cloud” world.
We have also learned (or re-learned) that arbitrary non-backward compatible versioning, e.g. for political or procedural reasons as with WS-Addressing, is a crime. XML namespaces (of the XSD and WSDL types, as well as URIs used in similar ways in specifications, e.g. to identify a dialect or profile) are tricky, because they don’t have backward compatibility metadata and because of the practice to use organizations domain names in the URI (as opposed to specification-specific names that can be easily transferred, e.g. cmdbf.org versus dmtf.org/cmdbf). In the WS-based management world, we inherited these problems at the protocol level from the generic WS stack. Our hands are more or less clean, but only because we didn’t have enough success/longevity to generate our own versioning problems, at the model level. But those would have been there had these models been able to see the light of day (CML) or see adoption (DCML).
There are also practical lessons that can be learned about the tactics and strategies of the main players. Because it looks like they may not change very much, as corporations or even as individuals. Karla Norsworthy speaks for IBM on Cloud interoperability standards in this article<http://www.sdtimes.com/CLOUD_PROVIDERS_VOW_INTEROPERABILITY/About_CLOUDCOMPUTING/33410>. Andrew Layman represented Microsoft<http://www.eweek.com/c/a/Cloud-Computing/The-Open-Cloud-Manifesto-Debuts-707560/>in the post-Manifestogate Cloud patch-up meeting in New York. Winston Bumpus is driving the standards strategy at VMWare. These are all veterans of the WS-Management, WSDM and related wars collaborations (and more generally the whole WS-* effort for the first two). For the details of what there is to learn from the past in that area, you’ll have to corner me in a hotel bar and buy me a few drinks though. I am pretty sure you’d get your money’s worth (I am not a heavy drinker)…
In summary, here are my recommendations for standardizing Cloud API, based on lessons from the Web services management effort. The theme is “focus on domain models”. The line items:
- Have clear goals for each effort. E.g. is your use case to deploy and run an existing application in a Cloud-like automated environment, or is it to create new applications that efficiently take advantage of the added flexibility. Very different problems. - If you want to use OVF, then beef it up to better apply to Cloud situations, but keep it focused on VM packaging: don’t try to grow it into the complete model for the entire data center (e.g. a new DCML). - Complement OVF with similar specifications for other domains, like the application delivery systems listed above. Informally try to keep these different specifications consistent, but don’t over-engineer it by repeating the SML attempt. It is more important to have each specification map well to its domain of application than it is to have perfect consistency between them. Discrepancies can be bridged in code, or in a later incarnation. - As you segment by domain, as suggested in the previous two bullets, don’t segment the models any further within each domain. Handle configuration, installation and monitoring issues as a whole. - Don’t sweat the protocols. HTTP, plain old SOAP (don’t call it POS) or WS-* will meet your need. Pick one. You don’t have a scalability challenge as much as you have a model challenge so don’t get distracted here. If you use REST, do it in the mindset that Tim Bray describes<http://www.tbray.org/ongoing/When/200x/2009/03/16/Sun-Cloud>: “*If you’re going to do bits-on-the-wire, Why not use HTTP?<http://timothyfitz.wordpress.com/2009/02/12/why-http/>And if you’re going to use HTTP, use it right. That’s all. *” Not as something that needs to scale to Web scale or as a rebuff of WS-*. - Beware of versioning. Version for operational changes only, not organizational reasons. Provide metadata to assert and encourage backward compatibility.
This is not a recipe for the ideal result but it is what I see as practically achievable. And fault-tolerant, in the sense that the failure of one piece would not negate the value of the others. As much as I have constrained expectations <http://stage.vambenepe.com/archives/684> for Cloud portability, I still want it to improve to the extent possible. If we can’t get a consistent RDF-based (or RDF-like in many ways) modeling framework, let’s at least apply ourselves to properly understanding and modeling the important areas.
In addition to these general lessons, there remains the question of what specific specifications will/should transition to the Cloud universe. Clearly not all of them, since not all of them even made it in the “regular” IT management world for which they were designed. How many then? Not surprisingly (since IBM had a big role in most of them), Karla Norsworthy, in the interview<http://www.sdtimes.com/CLOUD_PROVIDERS_VOW_INTEROPERABILITY/About_CLOUDCOMPUTING/33410>mentioned above, asserts that *“infrastructure as a service, or virtualization as a paradigm for deployment, is a situation where a lot of existing interoperability work that the industry has done will surely work to allow integration of services”*. And just as unsurprisingly Amazon’s Adam Selipsky, who’s company has nothing to with the previous wave but finds itself in leadership position WRT to Cloud Computing is a lot more circumspect: *“whether existing standards can be transferred to this case [of cloud computing] or if it’s a new topic is [too] early to say”*. OVF is an obvious candidate. WS-Management is by far the most widely implemented of the bunch, so that gives it an edge too (it is apparently already in use for Cloud monitoring, according to this press release<http://findarticles.com/p/articles/mi_pwwi/is_200903/ai_n31400439/>by an “innovation leader in automated network and systems monitoring software” that I had never heard of). Then there is the question of what IBM has in mind for WS-RT (and other specifications that the WS-RA working group is toiling on). If it’s not used as part of a Cloud API then I really don’t know what it will be used for. But selling it as such is going to be an uphill battle. CMDBf is a candidate too, as a model-neutral way to manage the configuration of a distributed system. But here I am, violating two of my own recommendations (”focus on models” and “don’t isolate config from other modeling aspects”). I guess it will take another pass to really learn…
On Tue, May 5, 2009 at 3:33 AM, Sam Johnston <samj@samj.net> wrote:
Morning all,
I'm going to break my own rules about reposting blog posts because this is very highly relevant, it's 03:30am already and I'm traveling again tomorrow. The next step for us is to work out what the protocol itself will look like on the wire, which is something I have been spending a good deal of time looking at over many months (both analysing existing efforts and thinking of "blue sky" possibilities).
I am now 100% convinced that the best results are to be had with a variant of XML over HTTP (as is the case with Amazon, Google, Sun and VMware) and that while Google's GData is by far the most successful cloud API in terms of implementations, users, disparate services, etc. Amazon's APIs are (at least for the foreseeable future) a legal minefield. I'm also very interested in the direction Sun and VMware are going and have of course been paying very close attention to existing public clouds like ElasticHosts and GoGrid (with a view to being essentially backwards compatible and sysadmin friendly).
I think the best strategy by a country mile is to standardise OCCI core protocol following Google's example (e.g. base it on Atom and/or AtomPub with additional specs for search, caching, etc.), build IaaS extensions in the spirit of Sun/VMware APIs and support alternative formats including HTML, JSON and TXT via XML Stylesheets (e.g. occi-to-html.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-html.xsl>, occi-to-json.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-json.xsl>and occi-to-text.xsl<http://code.google.com/p/occi/source/browse/trunk/xml/occi-to-text.xsl>). You can see the basics in action thanks to my Google App Engine reference implementation<http://code.google.com/p/occi/source/browse/#svn/trunk/occitest>at http://occitest.appspot.com/ (as well as HTML<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-html.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>, JSON<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-json.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>and TXT<http://www.w3.org/2005/08/online_xslt/xslt?xslfile=http%3A%2F%2Focci.googlecode.com%2Fsvn%2Ftrunk%2Fxml%2Focci-to-text.xsl&xmlfile=http%3A%2F%2Foccitest.appspot.com>versions of same), KISS junkies bearing in mind that this weighs in under 200 lines of python code! Of particular interest is the ease at which arbitrarily complex [X]HTML interfaces can be built directly on top of OCCI (optionally rendered from raw XML in the browser itself) and the use of the hCard microformat <http://microformats.org/> as a simple demonstration of what is possible.
Anyway, without further ado:
Is OCCI the HTTP of Cloud Computing? http://samj.net/2009/05/is-occi-http-of-cloud-computing.html
The Web is built on the Hypertext Transfer Protocol (HTTP)<http://en.wikipedia.org/wiki/HTTP>, a client-server protocol that simply allows client user agents to retrieve and manipulate resources stored on a server. It follows that a single protocol could prove similarly critical for Cloud Computing<http://en.wikipedia.org/wiki/Cloud_computing>, but what would that protocol look like?
The first place to look for the answer is limitations in HTTP itself. For a start the protocol doesn't care about the payload it carries (beyond its Internet media type <http://en.wikipedia.org/wiki/Internet_media_type>, such as text/html), which doesn't bode well for realising the vision<http://www.w3.org/2001/sw/Activity.html>of the [ Semantic <http://en.wikipedia.org/wiki/Semantic_Web>] Web<http://en.wikipedia.org/wiki/World_Wide_Web>as a "universal medium for the exchange of data". Surely it should be possible to add some structure to that data in the simplest way possible, without having to resort to carrying complex, opaque file formats (as is the case today)?
Ideally any such scaffolding added would be as light as possible, providing key attributes common to all objects (such as updated time) as well as basic metadata such as contributors, categories, tags and links to alternative versions. The entire web is built on hyperlinks so it follows that the ability to link between resources would be key, and these links should be flexible such that we can describe relationships in some amount of detail. The protocol would also be capable of carrying opaque payloads (as HTTP does today) and for bonus points transparent ones that the server can seamlessly understand too.
Like HTTP this protocol would not impose restrictions on the type of data it could carry but it would be seamlessly (and safely) extensible so as to support everything from contacts to contracts, biographies to books (or entire libraries!). Messages should be able to be serialised for storage and/or queuing as well as signed and/or encrypted to ensure security. Furthermore, despite significant performance improvements introduced in HTTP 1.1 it would need to be able to stream many (possibly millions) of objects as efficiently as possible in a single request too. Already we're asking a lot from something that must be extremely simple and easy to understand.
XML
It doesn't take a rocket scientist to work out that this "new" protocol is going to be XML based, building on top of HTTP in order to take advantage of the extensive existing infrastructure. Those of us who know even a little about XML will be ready to point out that the "X" in XML means "eXtensible" so we need to be specific as to the schema for this assertion to mean anything. This is where things get interesting. We could of course go down the WS-* route and try to write our own but surely someone else has crossed this bridge before - after all, organising and manipulating objects is one of the primary tasks for computers.
Who better to turn to for inspiration than a company whose mission<http://www.google.com/corporate/>it is to "organize the world's information and make it universally accessible and useful", Google. They use a single protocol for almost all of their APIs, GData <http://code.google.com/apis/gdata/>, and while people don't bother to look under the hood (no doubt thanks to the myriad client libraries <http://code.google.com/apis/gdata/clientlibs.html> made available under the permissive Apache 2.0 license), when you do you may be surprised at what you find: everything from contacts to calendar items, and pictures to videos is a feed (with some extensions for things like searching<http://code.google.com/apis/gdata/docs/2.0/basics.html#Searching>and caching<http://code.google.com/apis/gdata/docs/2.0/reference.html#ResourceVersioning> ).
OCCI
Enter the OGF's Open Cloud Computing Interface (OCCI)<http://www.occi-wg.org/>whose (initial) goal it is to provide an extensible interface to Cloud Infrastructure Services (IaaS). To do so it needs to allow clients to enumerate and manipulate an arbitrary number of server side "resources" (from one to many millions) all via a single entry point. These compute, network and storage resources need to be able to be created, retrieved, updated and deleted (CRUD) and links need to be able to be formed between them (e.g. virtual machines linking to storage devices and network interfaces). It is also necessary to manage state (start, stop, restart) and retrieve performance and billing information, among other things.
The OCCI working group basically has two options now in order to deliver an implementable draft this month as promised: follow Amazon or follow Google (the whole while keeping an eye on other players including Sun and VMware). Amazon use a simple but sprawling XML based API with a PHP style flat namespace and while there is growing momentum around it, it's not without its problems. Not only do I have my doubts about its scalability outside of a public cloud environment (calls like 'DescribeImages' would certainly choke with anything more than a modest number of objects and we're talking about potentially millions) but there are a raft of intellectual property issues as well:
- *Copyrights* (specifically section 3.3 of the Amazon Software License<http://aws.amazon.com/asl/>) prevent the use of Amazon's "open source" clients with anything other than Amazon's own services. - *Patents* pending like #20070156842<http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PG01&p=1&u=%2Fnetahtml%2FPTO%2Fsrchnum.html&r=1&f=G&l=50&s1=%2220070156842%22.PGNR.&OS=DN/20070156842&RS=DN/20070156842>cover the Amazon Web Services APIs and we know that Amazon have been known to use patents offensively<http://en.wikipedia.org/wiki/1-Click#Barnes_.26_Noble>against competitors. - *Trademarks* like #3346899<http://tarr.uspto.gov/servlet/tarr?regser=serial&entry=77054011>prevent us from even referring to the Amazon APIs by name.
While I wish the guys at Eucalyptus <http://open.eucalyptus.com/> and Canonical <http://news.zdnet.com/2100-9595_22-292296.html> well and don't have a bad word to say about Amazon Web Services, this is something I would be bearing in mind while actively seeking alternatives, especially as Amazon haven't worked out<http://www.tbray.org/ongoing/When/200x/2009/01/20/Cloud-Interop>whether the interfaces are IP they should protect. Even if these issues were resolved via royalty free licensing it would be very hard as a single vendor to compete with truly open standards (RFC 4287: Atom Syndication Format<http://tools.ietf.org/html/rfc4287>and RFC 5023: Atom Publishing Protocol <http://tools.ietf.org/html/rfc5023>) which were developed at IETF by the community based on loose consensus and running code.
So what does all this have to do with an API for Cloud Infrastructure Services (IaaS)? In order to facilitate future extension my initial designs for OCCI have been as modular as possible. In fact the core protocol is completely generic, describing how to connect to a single entry point, authenticate, search, create, retrieve, update and delete resources, etc. all using existing standards including HTTP, TLS, OAuth and Atom. On top of this are extensions for compute, network and storage resources as well as state control (start, stop, restart), billing, performance, etc. in much the same way as Google have extensions for different data types (e.g. contacts vs YouTube movies).
Simply by standardising at this level OCCI may well become the HTTP of Cloud Computing.
Amen on this one. Small and constrained. Plus use cases. That¹s it. --Randy On 5/6/09 7:04 AM, "Sam Johnston" <samj@samj.net> wrote:
In general, the more focused and narrow a modeling effort is, the more successful it seems to be (with OVF as the most focused of the list and CML as the other extreme).
-- Randy Bias, VP Technology Strategy, GoGrid randyb@gogrid.com, (415) 939-8507 [mobile] BLOG: http://neotactics.com/blog, TWITTER: twitter.com/randybias
participants (24)
-
 Alexander Papaspyrou
Alexander Papaspyrou -
 Alexis Richardson
Alexis Richardson -
 Andre Merzky
Andre Merzky -
 Benjamin Black
Benjamin Black -
 CEW
CEW -
 Chris Webb
Chris Webb -
 colleen smith
colleen smith -
 Edmonds, AndrewX
Edmonds, AndrewX -
eprparadocs@gmail.com
-
 Gary Mazz
Gary Mazz -
gary mazzaferro
-
 Krishna Sankar (ksankar)
Krishna Sankar (ksankar) -
 M. David Peterson
M. David Peterson -
 Marc-Elian Begin
Marc-Elian Begin -
Marc-Elian Bégin
-
 Mark Masterson
Mark Masterson -
 Randy Bias
Randy Bias -
 Richard Davies
Richard Davies -
 Richard Davies
Richard Davies -
 Roger Menday
Roger Menday -
 Sam Johnston
Sam Johnston -
 Tim Bray
Tim Bray -
 Tino Vazquez
Tino Vazquez -
 Tino Vazquez
Tino Vazquez