
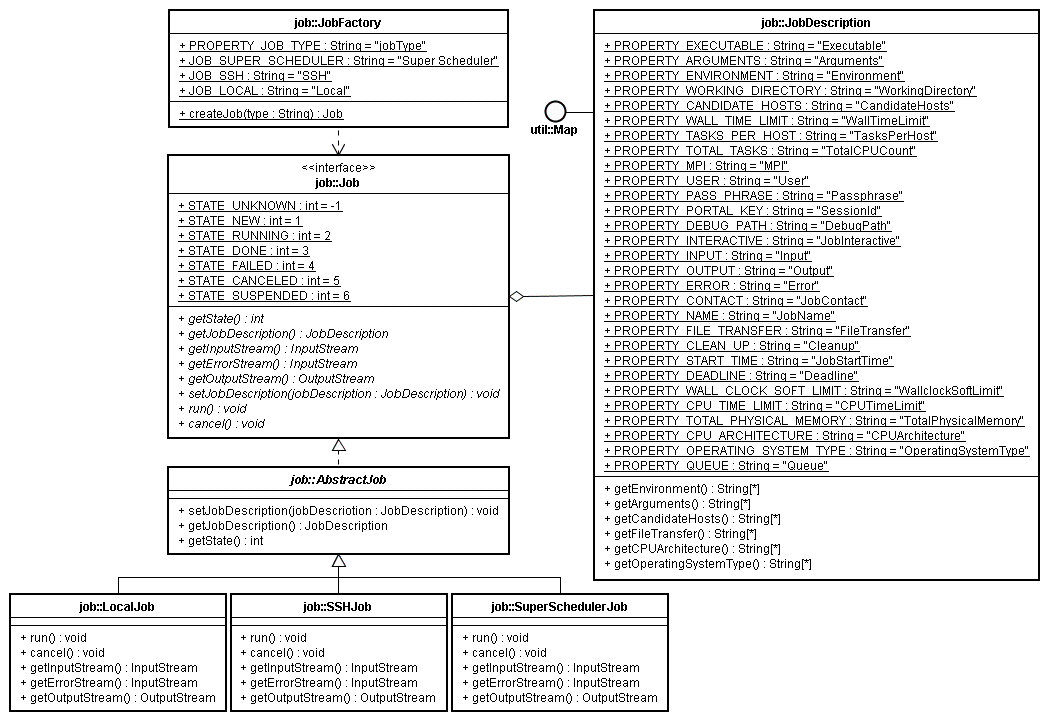
Dear SAGA members, Based on the API document currently in public comment phase, we have implemented a very simple version of the Job Management API. Basically we stripped the underlying SAGA model and when directly to Job Management API. See the attachment UML graph for details. The reason was that we did not have enough time to implement the full SAGA core to support the API and we focus on the NAREGI Super Scheduler (SS). Consideration and simplifications: - We do not support the suspended state at this time (see below for details). - The wait method is reserved in java for signal synchronization and is not used in the same way; we did not implement a real wait method since we are not interested in synchronization of jobs at the moment. This might be equivalent of the Thread.join() method. - Metrics handling has not been added. This might come with future incarnation of the package. - Job_self is not supported, also we could pretend it is the same as job in java. - We do not include all the methods of the job_service so far in the factory, might come in later incarnations and rename the factory in service. - Checkpoint and migrate are not supported for now. In two models it has no sense and the SS seems not to support it yet. - Signal is not supported, internally some implementations have it. But again the SS does not. - Many attributes are not supported at the moment. - Session and security model ignored (the SS has his own model) others don't care. - A job description can take strings, collections and a string arrays as arguments. Other formats are allowed if the caller knows how to manipulate them. Properties that are known to use string arrays have direct assessors to facilitate their access. All properties can be stored as a single string to allow serialization. Since we are working in Java we decided to go pure pattern oriented. So an application has access to the factory, job pattern and a Job description. The concrete Job stubs implementations are not supposed to be exposed (but are accessible since the class is public). Now the design is made so that we can later on hock the SAGA core classes below the current API without breaking (to much) the code (assuming we hold on our design pattern approach). We have three concrete implementations of Jobs: Local, SSH and Super Scheduler. - The local job uses the java process object and handles a job on the same machine as the JVM. This job type does not support suspended mode at all. This is a fully synchronous job since all actions are taken on the spot, unless you submit the job on a queuing system. - The SSH is a remote job incarnation, the job can run on any machine that has the SSH daemon running, this can be a synchronous job, unless you submit the job on a queuing system. This job type does not support suspended mode for the moment and only POSIX systems can be used to launch the job. - The Super Scheduler is NAREGI specific and uses NAREGI’s middleware. This is an asynchronous job. Suspended mode cannot be directly handled even if the state exists in the SS, so this is still pending. This job produces internally WSDL documents; the necessary methods are private however. General comments and questions. Might be some meat for the public comments as well: Now we stumbled upon the state machine of the API. The "Unknown" and "New" state are unclear to us. In our opinion when you create a job either with the factory or directly with the constructor of the specific incarnation, we enter the "New" state. The "Unknown" state is now reserved for the very short time the object is instantiated but we directly switch to "New" once the constructor is finished. The principle in OO programming is to have a stable object once you finish constructing it and calling method; if the constructor is not enough to have a stable object you need a factory. So when you get an object back it should be in a stable state, thus the "Unknown" state is superficial in our opinion. Some metrics or attributes or the Job are useless since they come directly from the descriptor, Example: "ExecutionHosts", "WorkingDirectory" or "CPUTimeLimit". Unless you consider that these values might be different from the job description. Or if the job description don't mention them the job can have this values assigned by the back-end. Either case the API documentation should clarify this. The run_job from the service will not follow the API contract if implemented. Only one parameter can be returned in java. Also the streams are available thought the Job pattern. In the document section 3.8.8 Examples the example at line 16 and 17 is wrong (or the method is overwritten). There should be no string argument. The host should be set in the descriptor. -- Best regards, Pascal Kleijer ---------------------------------------------------------------- HPC Marketing Promotion Division, NEC Corporation 1-10, Nisshin-cho, Fuchu, Tokyo, 183-8501, Japan. Tel: +81-(0)42/333.6389 Fax: +81-(0)42/333.6382
{kind=link}

Hi Pascal, below some answers/comments to the second part of your mail - for the first part I need more time for digestion... :-) Only so much: great that you attempt a SAGA implementation!!! Quoting [Pascal Kleijer] (Dec 14 2006):
General comments and questions. Might be some meat for the public comments as well:
Now we stumbled upon the state machine of the API. The "Unknown" and "New" state are unclear to us. In our opinion when you create a job either with the factory or directly with the constructor of the specific incarnation, we enter the "New" state. The "Unknown" state is now reserved for the very short time the object is instantiated but we directly switch to "New" once the constructor is finished. The principle in OO programming is to have a stable object once you finish constructing it and calling method; if the constructor is not enough to have a stable object you need a factory. So when you get an object back it should be in a stable state, thus the "Unknown" state is superficial in our opinion.
The new state is indeed supposed to reflect a successfull job creation: the job was created by calling job_service.create_job () synchronously. The job instance then has a job description, and methods like run() can be called. saga::job j = job_service.create (job_description); // job is 'New' here, and can be run. However, when the same methid has been called _asynchronously_, the job instance remains uninitialized until the async call returns: saga::job j; // job state is 'Unknown' - cannot be run, yet saga::task = job_service.create_job <async> (&job, job_description); // job state is still 'Unknown' - cannot be run, yet task.wait (); // only now the job instance is initialized, and the state // changes to 'New' - run can be called now. The state diagram contains the method calls which lead to the different states - maybe that is not obvious enough...
Some metrics or attributes or the Job are useless since they come directly from the descriptor, Example: "ExecutionHosts", "WorkingDirectory" or "CPUTimeLimit". Unless you consider that these values might be different from the job description. Or if the job description don't mention them the job can have this values assigned by the back-end. Either case the API documentation should clarify this.
Well, these metrics are not useless, but potentially redundant ;-) as you say, the job_description might not contain the respective values (only 'Executable' is required in jd). Also, you may not have started the job with a job_description, but may have created the instane via list<string> ids = job_service.list_jobs (); saga::job job = job_service.get_job (ids[0]); Also, things like CPUTimeLimit, pwd, or queue may get changed by the backend. Lastly, the metrics are monitorable, so you can get notifictions on such changes. That does not work with the job_description. Does that make sense?
The run_job from the service will not follow the API contract if implemented. Only one parameter can be returned in java. Also the streams are available thought the Job pattern.
Well, you can return an parameter array in Java - that is, AFAIK, the java way to multiple return parameters? But, yes, streams are available anyway. run_job() is a convenience method anyway... I am not sure how that should be rendered in Java... It'll probably be the single most discussed call in the Java bindings ;-)
In the document section 3.8.8 Examples the example at line 16 and 17 is wrong (or the method is overwritten). There should be no string argument. The host should be set in the descriptor.
Yes, indeed! Thanks nice catch - I fixed it in CVS... Cheers, Andre. -- "So much time, so little to do..." -- Garfield
Hello Andre, OK I let you digest the first part. If you need it I can bundle you the code if you feel for some Java snack :p Also some in-line comments:
below some answers/comments to the second part of your mail - for the first part I need more time for digestion... :-) Only so much: great that you attempt a SAGA implementation!!!
Quoting [Pascal Kleijer] (Dec 14 2006):
General comments and questions. Might be some meat for the public comments as well:
Now we stumbled upon the state machine of the API. The "Unknown" and "New" state are unclear to us. In our opinion when you create a job either with the factory or directly with the constructor of the specific incarnation, we enter the "New" state. The "Unknown" state is now reserved for the very short time the object is instantiated but we directly switch to "New" once the constructor is finished. The principle in OO programming is to have a stable object once you finish constructing it and calling method; if the constructor is not enough to have a stable object you need a factory. So when you get an object back it should be in a stable state, thus the "Unknown" state is superficial in our opinion.
The new state is indeed supposed to reflect a successfull job creation: the job was created by calling job_service.create_job () synchronously. The job instance then has a job description, and methods like run() can be called.
saga::job j = job_service.create (job_description); // job is 'New' here, and can be run.
However, when the same methid has been called _asynchronously_, the job instance remains uninitialized until the async call returns:
saga::job j; // job state is 'Unknown' - cannot be run, yet
saga::task = job_service.create_job <async> (&job, job_description); // job state is still 'Unknown' - cannot be run, yet
task.wait (); // only now the job instance is initialized, and the state // changes to 'New' - run can be called now.
The state diagram contains the method calls which lead to the different states - maybe that is not obvious enough...
OK I didn't think about the Task constructor. I come from a school of open mission critical software design where you need to mathematically prove that at each stage of your application your system is stable. The Unknown would sound strange.
saga::task = job_service.create_job <async> (&job, job_description); // job state is still 'Unknown' - cannot be run, yet
If I would implement this in Java the job would not be given in the args list. But the task would return it after the task has finished setting it up. The job is returned with another method call on the task and this method returns a value *ONLY* when it has finished setting up. In that case the Unknown state is always skipped for the user point of view. Internally it might exists for a brief time.
Some metrics or attributes or the Job are useless since they come directly from the descriptor, Example: "ExecutionHosts", "WorkingDirectory" or "CPUTimeLimit". Unless you consider that these values might be different from the job description. Or if the job description don't mention them the job can have this values assigned by the back-end. Either case the API documentation should clarify this.
Well, these metrics are not useless, but potentially redundant ;-) as you say, the job_description might not contain the respective values (only 'Executable' is required in jd). Also, you may not have started the job with a job_description, but may have created the instane via
list<string> ids = job_service.list_jobs (); saga::job job = job_service.get_job (ids[0]);
Also, things like CPUTimeLimit, pwd, or queue may get changed by the backend. Lastly, the metrics are monitorable, so you can get notifictions on such changes. That does not work with the job_description.
Does that make sense?
Yes it does, but it would be better to make it clean in the documentation that it might be redundant or that these values might be different from what the JD actually has.
The run_job from the service will not follow the API contract if implemented. Only one parameter can be returned in java. Also the streams are available thought the Job pattern.
Well, you can return an parameter array in Java - that is, AFAIK, the java way to multiple return parameters?
But, yes, streams are available anyway. run_job() is a convenience method anyway... I am not sure how that should be rendered in Java... It'll probably be the single most discussed call in the Java bindings ;-)
Yes I know. Actually returning an array is a possibility but not very clean because you then need to do additional type casts. Since the streams are available in the job, the Java binding will not return them.
In the document section 3.8.8 Examples the example at line 16 and 17 is wrong (or the method is overwritten). There should be no string argument. The host should be set in the descriptor.
I have found some more, see the public track page. -- Best regards, Pascal Kleijer ---------------------------------------------------------------- HPC Marketing Promotion Division, NEC Corporation 1-10, Nisshin-cho, Fuchu, Tokyo, 183-8501, Japan. Tel: +81-(0)42/333.6389 Fax: +81-(0)42/333.6382
Hi again, Quoting [Pascal Kleijer] (Dec 18 2006):
OK I let you digest the first part. If you need it I can bundle you the code if you feel for some Java snack :p
*shiver* ;-)
[...]
OK I didn't think about the Task constructor. I come from a school of open mission critical software design where you need to mathematically prove that at each stage of your application your system is stable. The Unknown would sound strange.
saga::task = job_service.create_job <async> (&job, job_description); // job state is still 'Unknown' - cannot be run, yet
If I would implement this in Java the job would not be given in the args list. But the task would return it after the task has finished setting it up. The job is returned with another method call on the task and this method returns a value *ONLY* when it has finished setting up. In that case the Unknown state is always skipped for the user point of view. Internally it might exists for a brief time.
Yes, I can see that this might make sense in Jave - it would look somewhat unfamiliar in C/C++ though. I guess the Java language binding would deviate from the C++ binding then.
Some metrics or attributes or the Job are useless since they come directly from the descriptor, Example: "ExecutionHosts", "WorkingDirectory" or "CPUTimeLimit". Unless you consider that these values might be different from the job description. Or if the job description don't mention them the job can have this values assigned by the back-end. Either case the API documentation should clarify this.
Well, these metrics are not useless, but potentially redundant ;-) as you say, the job_description might not contain the respective values (only 'Executable' is required in jd). Also, you may not have started the job with a job_description, but may have created the instane via
list<string> ids = job_service.list_jobs (); saga::job job = job_service.get_job (ids[0]);
Also, things like CPUTimeLimit, pwd, or queue may get changed by the backend. Lastly, the metrics are monitorable, so you can get notifictions on such changes. That does not work with the job_description.
Does that make sense?
Yes it does, but it would be better to make it clean in the documentation that it might be redundant or that these values might be different from what the JD actually has.
Ok, good point, that makes sense IMHO.
The run_job from the service will not follow the API contract if implemented. Only one parameter can be returned in java. Also the streams are available thought the Job pattern.
Well, you can return an parameter array in Java - that is, AFAIK, the java way to multiple return parameters?
But, yes, streams are available anyway. run_job() is a convenience method anyway... I am not sure how that should be rendered in Java... It'll probably be the single most discussed call in the Java bindings ;-)
Yes I know. Actually returning an array is a possibility but not very clean because you then need to do additional type casts. Since the streams are available in the job, the Java binding will not return them.
Ok, again, that may make sense in the Java binding (we had multiple comments from Java people about that exact point already).
In the document section 3.8.8 Examples the example at line 16 and 17 is wrong (or the method is overwritten). There should be no string argument. The host should be set in the descriptor.
I have found some more, see the public track page.
Great :-) Thanks, Andre. -- "So much time, so little to do..." -- Garfield
participants (2)
-
 Andre Merzky
Andre Merzky -
 Pascal Kleijer
Pascal Kleijer