
I choose some arbitrary names for some attributes; I'm happy to discuss that in another thread.
I guess I should rename this thread to "other" ;) Jason Zurawski wrote:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:segment nm:idRef="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
Is there a reason you choose to introduce a new element (segment) instead of using link? I think we are all aware of the 'segment vs link' battles of past OGFs that have spanned many different working groups, and I was under the impression that the outcome was to use 'link' for all connections instead of switching between names.
I meant both to be a "nml:link" instance. My example is indeed confusing, and comes from my background in using RDF/XML. A better syntax proposal is indeed (note that nml:segment is replaced by nml:link, and nm:idRef is replaces by nm:id): <nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:link nm:id="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link> In case you are curious why I created such a convoluted example, read on. (it's off-topic for the NML-WG though, and you may want to skip it) +------------------------------------------------+ | Link | +------------------------------------------------+ | id = urn:ogf:network:example.net:pathAC | | type = "link" | | ... | +------------------------------------------------+ | | | +------------------------------+ | | Relation | | +------------------------------+ |--| type = "serialcompound" | | | cl:type = "partial" | | | ... | | +------------------------------+ | | +------------------------------------------------+ | Link | +------------------------------------------------+ | id = urn:ogf:network:example.net:segmentAB | | ... | +------------------------------------------------+ In RDF, only objects can have properties. properties can not. So if I want to describe the above, I need to make both Links and Relations an object. The relation between two objects is always with a named attribute, so for RDF, one needs to create for the relation between a Link and a Relation object, and between a Relation and Link object, as in: <nml:Link rdf:about="urn:ogf:network:example.net:pathAC"> <nml:linktype>link</nml:linktype> <nml:hasrelation> <!-- attribute --> <nml:Relation> <nml:relationtype>serialcompound</nml:relationtype> <cl:type>partial</cl:type> <nml:segment rdf:resource="urn:ogf:network:example.net:segmentAB"/> </nml:Relation> </nml:hasrelation> </nml:Link> (observe that rdf:about is the same as nm:id, and rdf:resource is the same as nm:idRef) In XML, this can be a lot shorter, so I picked XML for brevity, but indeed forget to use the object name (nml:Link) instead of the made-up attributed name (nml:segemnt). Sorry for the confusion, Freek

Hi Freek; On 12/13/10 11:53 AM, Freek Dijkstra wrote:
I choose some arbitrary names for some attributes; I'm happy to discuss that in another thread.
I guess I should rename this thread to "other" ;)
Jason Zurawski wrote:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:segment nm:idRef="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
Is there a reason you choose to introduce a new element (segment) instead of using link? I think we are all aware of the 'segment vs link' battles of past OGFs that have spanned many different working groups, and I was under the impression that the outcome was to use 'link' for all connections instead of switching between names.
I meant both to be a "nml:link" instance.
My example is indeed confusing, and comes from my background in using RDF/XML.
A better syntax proposal is indeed (note that nml:segment is replaced by nml:link, and nm:idRef is replaces by nm:id):
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:link nm:id="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
I still think this is a little off. I would assume that 'segmentAB' belongs to someone already? If this is the case, it's defined already, so you would use an idRef (as a pointer) in the second enclosed link instead of an id. If it is not already defined, than the use of 'id' is appropriate, but brings up another issue of defining links within relations/other links. We have avoided this in the past. I would make the example as so (again, removing the use of the attribute namespaces since I also feel this is really confusing things): <nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link> Lastly the inclusion of the 'type=partial' is still rather foreign to me, so I omitted it. Can you explain why you need to do this? Thanks; -jason
In case you are curious why I created such a convoluted example, read on. (it's off-topic for the NML-WG though, and you may want to skip it)
+------------------------------------------------+ | Link | +------------------------------------------------+ | id = urn:ogf:network:example.net:pathAC | | type = "link" | | ... | +------------------------------------------------+ | | | +------------------------------+ | | Relation | | +------------------------------+ |--| type = "serialcompound" | | | cl:type = "partial" | | | ... | | +------------------------------+ | | +------------------------------------------------+ | Link | +------------------------------------------------+ | id = urn:ogf:network:example.net:segmentAB | | ... | +------------------------------------------------+
In RDF, only objects can have properties. properties can not. So if I want to describe the above, I need to make both Links and Relations an object. The relation between two objects is always with a named attribute, so for RDF, one needs to create for the relation between a Link and a Relation object, and between a Relation and Link object, as in:
<nml:Link rdf:about="urn:ogf:network:example.net:pathAC"> <nml:linktype>link</nml:linktype> <nml:hasrelation> <!-- attribute --> <nml:Relation> <nml:relationtype>serialcompound</nml:relationtype> <cl:type>partial</cl:type> <nml:segment rdf:resource="urn:ogf:network:example.net:segmentAB"/> </nml:Relation> </nml:hasrelation> </nml:Link>
(observe that rdf:about is the same as nm:id, and rdf:resource is the same as nm:idRef)
In XML, this can be a lot shorter, so I picked XML for brevity, but indeed forget to use the object name (nml:Link) instead of the made-up attributed name (nml:segemnt).
Sorry for the confusion, Freek
Jason Zurawski wrote:
A better syntax proposal is indeed (note that nml:segment is replaced by nml:link, and nm:idRef is replaces by nm:id):
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:link nm:id="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
I still think this is a little off. I would assume that 'segmentAB' belongs to someone already? If this is the case, it's defined already, so you would use an idRef (as a pointer) in the second enclosed link instead of an id. If it is not already defined, than the use of 'id' is appropriate, but brings up another issue of defining links within relations/other links. We have avoided this in the past.
Actually, it is still not quite clear to me why there is a need to distinguish between id and idRef. If two objects have with the same value for the id attribute, it is clear they refer to the same thing. (Obviously I can imagine a few reasons to distinguish between id and idRef. For example (1) RDF has them both -with different names- for syntaxtic reasons; (2) id is used by authoritative sources, while idRef is used by non-authoratitive sources; (3) id is used when the object is defined the first time in a document, and idRef is used subsequently. Neither of these reasons is very convincing to me; perhaps you can elaborate a bit more what distinction you see and why this distinction is required.)
I would make the example as so (again, removing the use of the attribute namespaces since I also feel this is really confusing things):
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
Lastly the inclusion of the 'type=partial' is still rather foreign to me, so I omitted it. Can you explain why you need to do this?
In the above I was trying to describe the following information: "urn:ogf:network:example.net:segmentAB is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path". This seems typical information that the domain who provisioned urn:ogf:network:example.net:segmentAB might say. The addition of the word "partial" was trying to emphasis that, but I agree that it can be conveyed with other means (such as the lack of a "count" attribute in the above, meaning that the list may be incomplete.) Regards, Freek
Hi Freek/All; On 12/13/10 3:07 PM, Freek Dijkstra wrote:
Jason Zurawski wrote:
A better syntax proposal is indeed (note that nml:segment is replaced by nml:link, and nm:idRef is replaces by nm:id):
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:type="partial"> <nml:link nm:id="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
I still think this is a little off. I would assume that 'segmentAB' belongs to someone already? If this is the case, it's defined already, so you would use an idRef (as a pointer) in the second enclosed link instead of an id. If it is not already defined, than the use of 'id' is appropriate, but brings up another issue of defining links within relations/other links. We have avoided this in the past.
Actually, it is still not quite clear to me why there is a need to distinguish between id and idRef. If two objects have with the same value for the id attribute, it is clear they refer to the same thing.
(Obviously I can imagine a few reasons to distinguish between id and idRef. For example (1) RDF has them both -with different names- for syntaxtic reasons; (2) id is used by authoritative sources, while idRef is used by non-authoratitive sources; (3) id is used when the object is defined the first time in a document, and idRef is used subsequently. Neither of these reasons is very convincing to me; perhaps you can elaborate a bit more what distinction you see and why this distinction is required.)
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. Two quick examples from NMC/perfSONAR: 1) Every data has an id field, but also a 'metadataIdRef' which points to the 'parent' metadata for that data item. 2) Every 'metadata' in perfSONAR has an id field. Chaining is performed by inserting a 'metadataIdRef' inside of an empty subject, this allows us to perform filtering operations on the metadata that is 'referenced'. Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope. For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids. Hope this helps.
I would make the example as so (again, removing the use of the attribute namespaces since I also feel this is really confusing things):
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"/> </nml:relation> </nml:link>
Lastly the inclusion of the 'type=partial' is still rather foreign to me, so I omitted it. Can you explain why you need to do this?
In the above I was trying to describe the following information: "urn:ogf:network:example.net:segmentAB is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
This seems typical information that the domain who provisioned urn:ogf:network:example.net:segmentAB might say.
The addition of the word "partial" was trying to emphasis that, but I agree that it can be conveyed with other means (such as the lack of a "count" attribute in the above, meaning that the list may be incomplete.)
Alright. I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly. Thanks; -jason
Hey Jason, Excellent discussion. I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net". Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop). Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.) We're currently focussing on the second way. Let's continue that.
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly.
Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference). Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path". If I follow the above statement, I'm inclined to write: <nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids.
However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net: <nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link> (Obviously if example.net would announce the very same information, the id and idRef would flip in this example.) Which one did you mean? Regards, Freek (PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.)
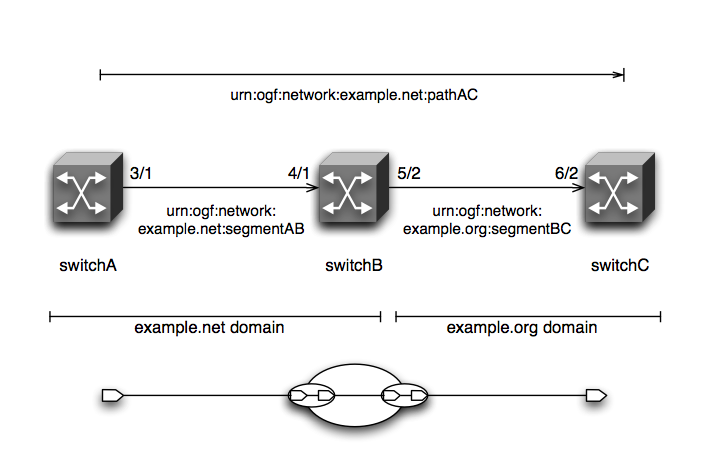{kind=link}

On Dec 13, 2010, at 5:31 PM, Freek Dijkstra wrote:
Hey Jason,
Excellent discussion.
I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net".
Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop).
Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.)
We're currently focussing on the second way. Let's continue that.
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly.
Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference).
Since I proffered the proposal, I'll take a cut at rewriting. The only big thing that would change is in the end-to-end "link" element: Original: <nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:idRef="urn:ogf:network:example.net:segmentAB" cl:order="1"/> <nml:link nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" cl:order="2"/> <nml:link nm:idRef="urn:ogf:network:example.org:segmentBC" cl:order="3"/> </nml:relation> </nml:link> Modified: <nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:id="l1" nm:idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link nm:idRef="l2" /> </nml:relation> </nml:link> <nml:link nm:id="l2" nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link nm:idRef="l3" /> </nml:relation> </nml:link> <nml:link nm:id="l3" nm:idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link> This model could be extended beyond a simple ordered list to trees or other structures as well by introducing new relationships beyond "next-hop". I will note though that 'next-hop' is just an example name, and we should probably think about a more appropriate relation name. Cheers, Aaron
Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids.
However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net:
<nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
(Obviously if example.net would announce the very same information, the id and idRef would flip in this example.)
Which one did you mean?
Regards, Freek
(PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.) <serial_compound.xml><serial compound.png>_______________________________________________ nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg
Hi Freek/All; On 12/13/10 5:43 PM, Aaron Brown wrote:
On Dec 13, 2010, at 5:31 PM, Freek Dijkstra wrote:
Hey Jason,
Excellent discussion.
I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net".
Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop).
Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.)
We're currently focussing on the second way. Let's continue that.
These two are not mutually exclusive, in fact I think that with Aaron's proposal both can exist happily. I would expect that within a domain the ports, nodes, and internal links would be well defined and utilizing the first method would be easier to do instead of relying on abstracted topology definitions. When instantiating cross domain communication there would be an increased need to exercise reference chasing (via on demand fetching), or to rely on pointers. Yes - I would want to see both approaches available, I would object to having multiple ways to implement the 2nd ('explicit' ordering) though. I can't speak to what is in use by the controlplane implementations, I was under the impression that it was path/hop. In the measurement world we do use the 'ordering' attributes for data from the traceroute tool but this is not for topology. I would prefer there be one accepted way to do such an operation instead of many. This simplifies implementation and removes confusion on the 'right' way to represent a concept. So my preference is to use the linked list method instead of using attributes to assign ids or orders.
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly.
Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference).
Since I proffered the proposal, I'll take a cut at rewriting. The only big thing that would change is in the end-to-end "link" element:
Original:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:idRef="urn:ogf:network:example.net:segmentAB" cl:order="1"/> <nml:link nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" cl:order="2"/> <nml:link nm:idRef="urn:ogf:network:example.org:segmentBC" cl:order="3"/> </nml:relation> </nml:link>
Modified:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:id="l1" nm:idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link nm:idRef="l2" /> </nml:relation> </nml:link> <nml:link nm:id="l2" nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link nm:idRef="l3" /> </nml:relation> </nml:link> <nml:link nm:id="l3" nm:idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
This model could be extended beyond a simple ordered list to trees or other structures as well by introducing new relationships beyond "next-hop". I will note though that 'next-hop' is just an example name, and we should probably think about a more appropriate relation name.
I think that other ways to link the constructs together as Aaron mentions (beyond a simple list) addresses another NML need that was discussed at the last meeting: representation of broadcast and multicast.
Cheers, Aaron
Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Instead of boring everyone with more prolonged discussions, its better for you to consult the documentation: https://forge.gridforum.org/sf/go/doc15644?nav=1 See the following sections for use cases: - 4.3.2.4 (use in the 'Metadata' element) - 4.3.2.8 (use in the 'Data' element) - 5 (basic explanation of chaining), specifically 5.1.3 for a 'merge' example and 5.2.1 for a 'operation' example. If you still have questions, lets take it offlist.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
What would 'more properties of this link' entail? You could also do it this way (in my opinion), but I am also not sure what you need to specify ...: <nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link> </nml:relation> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids.
However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net:
<nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
(Obviously if example.net would announce the very same information, the id and idRef would flip in this example.)
Which one did you mean?
Since I am not an expert in the control plane world, so I will probably need to punt on this, but I would assume that the 'side' that imitated the end to end path gets to have the 'authoritative' copy (to borrow from the information distribution model used in the gLS), and thus would address it as 'id'. Other members of the path may want a copy ('non-authoratative') and would probably refer to it as 'idRef'. If example.net initiated, they call it by 'id'. If example.org has a copy, they use 'idRef'. Does this answer your question?
Regards, Freek
(PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.) <serial_compound.xml><serial compound.png>
As for your attached topology/picture I maintain some of the same comments as prior: - Use of new elements seems unnecessary (hascrossconnect, hasport) when we have relations. - You still have not explained the difference between 'type=link' and 'type=crossconnect', and why this is necessary. I would like to understand this better. - I think all of the uses of org and net with id/idRef are correct, but the example is getting very long and hard to manage. Someone else should please verify. Thanks; -jason

On Dec 13, 2010, at 5:01 PM, Jason Zurawski wrote:
Hi Freek/All;
On 12/13/10 5:43 PM, Aaron Brown wrote:
On Dec 13, 2010, at 5:31 PM, Freek Dijkstra wrote:
Hey Jason,
Excellent discussion.
I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net".
Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop).
Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.)
We're currently focussing on the second way. Let's continue that.
These two are not mutually exclusive, in fact I think that with Aaron's proposal both can exist happily. I would expect that within a domain the ports, nodes, and internal links would be well defined and utilizing the first method would be easier to do instead of relying on abstracted topology definitions. When instantiating cross domain communication there would be an increased need to exercise reference chasing (via on demand fetching), or to rely on pointers.
Yes - I would want to see both approaches available, I would object to having multiple ways to implement the 2nd ('explicit' ordering) though. I can't speak to what is in use by the controlplane implementations, I was under the impression that it was path/hop. In the measurement world we do use the 'ordering' attributes for data from the traceroute tool but this is not for topology.
I would prefer there be one accepted way to do such an operation instead of many. This simplifies implementation and removes confusion on the 'right' way to represent a concept. So my preference is to use the linked list method instead of using attributes to assign ids or orders.
I do not believe that should be a determination made in the context of NML. NML should be used to define valid syntax. Deciding when different specific uses of the syntax make the most sense should be done in the context of a specific application or protocol. Lets keep those discussions separate for now. NML should be flexible enough to support multiple use cases, and there is no reason to limit this at this level. If we want to have the other discussion, lets do it using real examples, discussing semantic needs of specific applications and protocols. jeff
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly.
Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference).
Since I proffered the proposal, I'll take a cut at rewriting. The only big thing that would change is in the end-to-end "link" element:
Original:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:idRef="urn:ogf:network:example.net:segmentAB" cl:order="1"/> <nml:link nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" cl:order="2"/> <nml:link nm:idRef="urn:ogf:network:example.org:segmentBC" cl:order="3"/> </nml:relation> </nml:link>
Modified:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:id="l1" nm:idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link nm:idRef="l2" /> </nml:relation> </nml:link> <nml:link nm:id="l2" nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link nm:idRef="l3" /> </nml:relation> </nml:link> <nml:link nm:id="l3" nm:idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
This model could be extended beyond a simple ordered list to trees or other structures as well by introducing new relationships beyond "next-hop". I will note though that 'next-hop' is just an example name, and we should probably think about a more appropriate relation name.
I think that other ways to link the constructs together as Aaron mentions (beyond a simple list) addresses another NML need that was discussed at the last meeting: representation of broadcast and multicast.
Cheers, Aaron
Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Instead of boring everyone with more prolonged discussions, its better for you to consult the documentation:
https://forge.gridforum.org/sf/go/doc15644?nav=1
See the following sections for use cases:
- 4.3.2.4 (use in the 'Metadata' element) - 4.3.2.8 (use in the 'Data' element) - 5 (basic explanation of chaining), specifically 5.1.3 for a 'merge' example and 5.2.1 for a 'operation' example.
If you still have questions, lets take it offlist.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
What would 'more properties of this link' entail? You could also do it this way (in my opinion), but I am also not sure what you need to specify ...:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link> </nml:relation> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids.
However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net:
<nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
(Obviously if example.net would announce the very same information, the id and idRef would flip in this example.)
Which one did you mean?
Since I am not an expert in the control plane world, so I will probably need to punt on this, but I would assume that the 'side' that imitated the end to end path gets to have the 'authoritative' copy (to borrow from the information distribution model used in the gLS), and thus would address it as 'id'. Other members of the path may want a copy ('non-authoratative') and would probably refer to it as 'idRef'.
If example.net initiated, they call it by 'id'. If example.org has a copy, they use 'idRef'. Does this answer your question?
Regards, Freek
(PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.) <serial_compound.xml><serial compound.png>
As for your attached topology/picture I maintain some of the same comments as prior:
- Use of new elements seems unnecessary (hascrossconnect, hasport) when we have relations.
- You still have not explained the difference between 'type=link' and 'type=crossconnect', and why this is necessary. I would like to understand this better.
- I think all of the uses of org and net with id/idRef are correct, but the example is getting very long and hard to manage. Someone else should please verify.
Thanks;
-jason _______________________________________________ nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg

W dniu 2010-12-13 23:43, Aaron Brown pisze:
On Dec 13, 2010, at 5:31 PM, Freek Dijkstra wrote:
Hey Jason,
Excellent discussion.
I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net".
Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop).
Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.)
We're currently focussing on the second way. Let's continue that.
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly. Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference). Since I proffered the proposal, I'll take a cut at rewriting. The only big thing that would change is in the end-to-end "link" element:
Original:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:idRef="urn:ogf:network:example.net:segmentAB" cl:order="1"/> <nml:link nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" cl:order="2"/> <nml:link nm:idRef="urn:ogf:network:example.org:segmentBC" cl:order="3"/> </nml:relation> </nml:link>
Modified:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:id="l1" nm:idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link nm:idRef="l2" /> </nml:relation> </nml:link> <nml:link nm:id="l2" nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link nm:idRef="l3" /> </nml:relation> </nml:link> <nml:link nm:id="l3" nm:idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
I like that modified example because it gives solutions for ordering and grouping the links of the circuit. Just one comment: I don't think we need 'id' attribute for ordering. Both attributes (id and idRef) in 'link' element may confuse. One can use real id references (they are unique). See below (I removed the namespace for 'id' and 'idRef' attributes as I support dropping them; I also removed the type of link as its 'link' value may be default): <nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link> Cheers, Roman
This model could be extended beyond a simple ordered list to trees or other structures as well by introducing new relationships beyond "next-hop". I will note though that 'next-hop' is just an example name, and we should probably think about a more appropriate relation name.
Cheers, Aaron
Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids. However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net:
<nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
(Obviously if example.net would announce the very same information, the id and idRef would flip in this example.)
Which one did you mean?
Regards, Freek
(PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.) <serial_compound.xml><serial compound.png>_______________________________________________ nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg
nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg

Hi, On 14/12/2010 13:51, Roman Łapacz wrote:
I like that modified example because it gives solutions for ordering and grouping the links of the circuit. Just one comment: I don't think we need 'id' attribute for ordering. Both attributes (id and idRef) in 'link' element may confuse. One can use real id references (they are unique). See below (I removed the namespace for 'id' and 'idRef' attributes as I support dropping them; I also removed the type of link as its 'link' value may be default):
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
(I introduced the whitespace again, since I think it got lost in transmission somewhere). I like this version. Introducing new id's should not necessary since we already have globally unique values. The use-case for these linked lists also does not seem to call for much injection in the middle; if something changes in a segmented link, then the elements change, or it is a whole new link. Jeroen.
On Dec 14, 2010, at 7:51 AM, Roman Łapacz wrote:
W dniu 2010-12-13 23:43, Aaron Brown pisze:
On Dec 13, 2010, at 5:31 PM, Freek Dijkstra wrote:
Hey Jason,
Excellent discussion.
I attached the original example again, with one small change: segmentBC is now part of domain "example.org" instead of "example.net".
Remember, there are two distinct ways in the XML to "trace" the original path: - Using ports (if the sink of link A is port X, and the source of link B is also port X, you know that links A and B are connected in series) - Using explicit ordering (either order="1", order="2" or hop/nextHop).
Could you confirm that you want to see BOTH approaches in NML? (I think there are use cases for both.)
We're currently focussing on the second way. Let's continue that.
I would vote for Aaron's proposal that I listed out in one of the first mails (no longer in this tread for some reason) to use pointer elements instead of count/type elements. I believe that respects the original hop/path idea a little closer. If the existing tooling can deal with a concept that 'follows' a path, that's a strong argument to remain with it even if the syntax changes slightly. Could you rewrite the attached example to use the hop/nextHop approach? I think we should write both down in detail, and if we're happy with both examples, we should ask the group to vote (I currently have no preference). Since I proffered the proposal, I'll take a cut at rewriting. The only big thing that would change is in the end-to-end "link" element:
Original:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:idRef="urn:ogf:network:example.net:segmentAB" cl:order="1"/> <nml:link nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" cl:order="2"/> <nml:link nm:idRef="urn:ogf:network:example.org:segmentBC" cl:order="3"/> </nml:relation> </nml:link>
Modified:
<nml:link type="link" nm:id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound" cl:count="3"> <nml:link nm:id="l1" nm:idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link nm:idRef="l2" /> </nml:relation> </nml:link> <nml:link nm:id="l2" nm:idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link nm:idRef="l3" /> </nml:relation> </nml:link> <nml:link nm:id="l3" nm:idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
I like that modified example because it gives solutions for ordering and grouping the links of the circuit. Just one comment: I don't think we need 'id' attribute for ordering. Both attributes (id and idRef) in 'link' element may confuse. One can use real id references (they are unique). See below (I removed the namespace for 'id' and 'idRef' attributes as I support dropping them; I also removed the type of link as its 'link' value may be default):
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.net:segmentAB"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.net:crossconnect4-1_5-2"> <nml:relation type="next-hop"> <link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link> <nml:link idRef="urn:ogf:network:example.org:segmentBC" /> </nml:relation> </nml:link>
I'm not married to the idea of having the id in there as well as the idRef. Not having the id element does change the client lookup routine a bit though. Instead of doing "find the link with id of 'urn:ogf:network:example.net:crossconnect4-1_5-2'", the client does "look for a link in this relation set with an idRef of 'urn:ogf:network:example.net:crossconnect4-1_5-2'. If not found, look for a link with id 'urn:ogf:network:example.net:crossconnect4-1_5-2'". Cheers, Aaron
Cheers, Roman
This model could be extended beyond a simple ordered list to trees or other structures as well by introducing new relationships beyond "next-hop". I will note though that 'next-hop' is just an example name, and we should probably think about a more appropriate relation name.
Cheers, Aaron
Regarding the id/idRef distinction, I probably understand what you're saying in text, but I can't translate this to XML. Both statements below make sense, but they still seem to clash.
Typically 'id' is the definition of something, 'idRef' is used as a pointer to something previously defined. [...]
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
Following these examples, I would claim that if some domain defines/owns an object, such as a link, they get to assign the 'id' field. If this is a GLIFesq definition I would assume this gives it a global scope.
For any other use that wishes to reference this original, there needs to be a clear semantic meaning that we are not trying to define (or re-define) the original. In the case of an end to end path that is using several links that belong to others (e.g. the control plane world), I am suggesting that if you intend to reference the individual components of the entire path, it is necessary to use idRefs instead of ids. However, following the above text, example.org can only use the id attribute for it's own links, and should use idRef for the end-to-end link defined by example.net:
<nml:link idRef="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link id="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
(Obviously if example.net would announce the very same information, the id and idRef would flip in this example.)
Which one did you mean?
Regards, Freek
(PS: I trimmed the cc with people who are already on the NML mailing list. I also increased the cc limit, this should stop the bounces.) <serial_compound.xml><serial compound.png>_______________________________________________ nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg
nml-wg mailing list nml-wg@ogf.org http://www.ogf.org/mailman/listinfo/nml-wg
W dniu 2010-12-13 23:31, Freek Dijkstra pisze:
Let's take the example that domain example.org wants to say "urn:ogf:network:example.org:segmentBC is a segment of the end-to-end link urn:ogf:network:example.net:pathAC, but I don't know the names of other segments of this path".
If I follow the above statement, I'm inclined to write:
<nml:link id="urn:ogf:network:example.net:pathAC"> <nml:relation type="serialcompound"> <nml:link idRef="urn:ogf:network:example.org:segmentBC"/> </nml:relation> </nml:link>
<nml:link idRef="urn:ogf:network:example.org:segmentBC"> <!-- more properties of this link --> </nml:link>
In case of the reservation/circuit descriptor all links (in fact, their IdRefs) of the path will have to be present. Cheers, Roman
participants (6)
-
 Aaron Brown
Aaron Brown -
 Freek Dijkstra
Freek Dijkstra -
 Jason Zurawski
Jason Zurawski -
 Jeff W. Boote
Jeff W. Boote -
 Jeroen van der Ham
Jeroen van der Ham -
 Roman Łapacz
Roman Łapacz