
Hi all, Can you show me how to represent the setup I have below using the new structure of the GLUE 2.0 entities? - our site manages 2 clusters - each cluster runs a PBS queuing system - each queueing system manages three queues: small, medium, large - globus is installed on a separate box -- called the gateway box. we run only one instance of the GRAM service on this box. anyone running a grid job at our site will have to specify the name-of-queue@name-of-pbs-server in the queue element of their RSL to pick which queue they want to submit their jobs to. It is not mentioned anywhere in the InitialSketch wiki (http://forge.gridforum.org/sf/wiki/do/viewPage/projects.glue-wg/wiki/Initial...) that the CE is still an abstraction of a queue. The relationship of a ComputingService to a CE is also many to one which makes it hard for one GRAM service to be able to submit jobs to a number of CEs (if ever a CE is still equivalent to a queue). Does this mean that we will have redundant info for the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment for every GRAM service (for each queue) we provide? Is it safe to assume that the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment entities in GLUE 2.0 are equivalent to the Cluster, SubCluster and Software entities of GLUE 1.3 respectively? You have a comment in the form of a question under the "element" section of the wiki which says: "can we have multiple resources (computing resources <=> clusters) served by the same service instance?". My answer is yes and isn't my use case above an example of it? Thanks, Gerson
Can anyone of the 9 members of the GLUE WG answer my question below? We just want to be sure that the current information we are publishing are still supported by the new GLUE schema. Thanks. ---------- Forwarded message ---------- From: Gerson Galang <gerson.sapac@gmail.com> Date: May 29, 2007 4:30 PM Subject: GLUE2.0's Computing Element To: glue-wg@ogf.org Hi all, Can you show me how to represent the setup I have below using the new structure of the GLUE 2.0 entities? - our site manages 2 clusters - each cluster runs a PBS queuing system - each queueing system manages three queues: small, medium, large - globus is installed on a separate box -- called the gateway box. we run only one instance of the GRAM service on this box. anyone running a grid job at our site will have to specify the name-of-queue@name-of-pbs-server in the queue element of their RSL to pick which queue they want to submit their jobs to. It is not mentioned anywhere in the InitialSketch wiki (http://forge.gridforum.org/sf/wiki/do/viewPage/projects.glue-wg/wiki/Initial...) that the CE is still an abstraction of a queue. The relationship of a ComputingService to a CE is also many to one which makes it hard for one GRAM service to be able to submit jobs to a number of CEs (if ever a CE is still equivalent to a queue). Does this mean that we will have redundant info for the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment for every GRAM service (for each queue) we provide? Is it safe to assume that the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment entities in GLUE 2.0 are equivalent to the Cluster, SubCluster and Software entities of GLUE 1.3 respectively? You have a comment in the form of a question under the "element" section of the wiki which says: "can we have multiple resources (computing resources <=> clusters) served by the same service instance?". My answer is yes and isn't my use case above an example of it? Thanks, Gerson

Gerson Galang wrote:
Can anyone of the 9 members of the GLUE WG answer my question below? We just want to be sure that the current information we are publishing are still supported by the new GLUE schema.
all your questions are good ones and they require us a little more thinking. As a placeholder, we have added use case no.32 for your email: http://forge.ogf.org/sf/wiki/do/viewPage/projects.glue-wg/wiki/UseCases we'll come back to you next week with the answers. Cheers, Sergio
Thanks.
---------- Forwarded message ---------- From: *Gerson Galang* <gerson.sapac@gmail.com <mailto:gerson.sapac@gmail.com> > Date: May 29, 2007 4:30 PM Subject: GLUE2.0's Computing Element To: glue-wg@ogf.org <mailto:glue-wg@ogf.org>
Hi all,
Can you show me how to represent the setup I have below using the new structure of the GLUE 2.0 entities?
- our site manages 2 clusters - each cluster runs a PBS queuing system - each queueing system manages three queues: small, medium, large - globus is installed on a separate box -- called the gateway box. we run only one instance of the GRAM service on this box. anyone running a grid job at our site will have to specify the name-of-queue@name-of-pbs-server in the queue element of their RSL to pick which queue they want to submit their jobs to.
It is not mentioned anywhere in the InitialSketch wiki ( http://forge.gridforum.org/sf/wiki/do/viewPage/projects.glue-wg/wiki/Initial...) that the CE is still an abstraction of a queue. The relationship of a ComputingService to a CE is also many to one which makes it hard for one GRAM service to be able to submit jobs to a number of CEs (if ever a CE is still equivalent to a queue). Does this mean that we will have redundant info for the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment for every GRAM service (for each queue) we provide?
Is it safe to assume that the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment entities in GLUE 2.0 are equivalent to the Cluster, SubCluster and Software entities of GLUE 1.3 respectively?
You have a comment in the form of a question under the "element" section of the wiki which says: "can we have multiple resources (computing resources <=> clusters) served by the same service instance?". My answer is yes and isn't my use case above an example of it?
Thanks, Gerson
------------------------------------------------------------------------
_______________________________________________ glue-wg mailing list glue-wg@ogf.org http://www.ogf.org/mailman/listinfo/glue-wg
-- Sergio Andreozzi INFN-CNAF, Tel: +39 051 609 2860 Viale Berti Pichat, 6/2 Fax: +39 051 609 2746 40126 Bologna (Italy) Web: http://www.cnaf.infn.it/~andreozzi

Hi Gerson, The schema is in an early draft state and therefore might still need a little work to get it into good shape. If you have any suggestions on how to improve the schema or can see any problems please let us know. I will try an answer you question based on what I understand of the current draft. What is important is to first understand the entities that we are dealing with and the relationships between them. For me a cluster represents a set of resources that are managed, which essentially is a batch system with a master server. The queue represents two things; an end point and a policy. The GRAM service is an interface to the batch system and therefore an end point. How you represent these things depends on the implementation. 1) If the job attributes are passed to the batch system, then based on these it should decide which queue (policy) best matches the requirements. In such a scenario, you would then publish two services (end points), one for each batch system, and the gateway should route the job to the relevant batch system based on which service (end point) was used. 2) If the the job requirements are not passed though, then you have to consider each queue to be a different endpoint and hence have a service (end point) per batch system and per queue (policy). The gateway would then route the job also to the correct queue. In either case the policy (queue) would be advertised as a share. However, in the second case I am not sure how the end point is linked to the policy. Laurence Gerson Galang wrote:
Hi all,
Can you show me how to represent the setup I have below using the new structure of the GLUE 2.0 entities?
- our site manages 2 clusters - each cluster runs a PBS queuing system - each queueing system manages three queues: small, medium, large - globus is installed on a separate box -- called the gateway box. we run only one instance of the GRAM service on this box. anyone running a grid job at our site will have to specify the name-of-queue@name-of-pbs-server in the queue element of their RSL to pick which queue they want to submit their jobs to.
It is not mentioned anywhere in the InitialSketch wiki ( http://forge.gridforum.org/sf/wiki/do/viewPage/projects.glue-wg/wiki/Initial...) that the CE is still an abstraction of a queue. The relationship of a ComputingService to a CE is also many to one which makes it hard for one GRAM service to be able to submit jobs to a number of CEs (if ever a CE is still equivalent to a queue). Does this mean that we will have redundant info for the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment for every GRAM service (for each queue) we provide?
Is it safe to assume that the ComputingResource, ExecutionEnvironment, and ApplicationEnvironment entities in GLUE 2.0 are equivalent to the Cluster, SubCluster and Software entities of GLUE 1.3 respectively?
You have a comment in the form of a question under the "element" section of the wiki which says: "can we have multiple resources (computing resources <=> clusters) served by the same service instance?". My answer is yes and isn't my use case above an example of it?
Thanks, Gerson ------------------------------------------------------------------------
_______________________________________________ glue-wg mailing list glue-wg@ogf.org http://www.ogf.org/mailman/listinfo/glue-wg
Hi Laurence, Sergio, For me a cluster represents a set of resources that are managed, which
essentially is a batch system with a master server. The queue represents two things; an end point and a policy. The GRAM service is an interface to the batch system and therefore an end point.
How you represent these things depends on the implementation.
1) If the job attributes are passed to the batch system, then based on these it should decide which queue (policy) best matches the requirements. In such a scenario, you would then publish two services (end points), one for each batch system, and the gateway should route the job to the relevant batch system based on which service (end point) was used.
What you have desribed above might not work for us. The GRAM does not have the restriction of only being able to submit (interface) to one batch system (PBS server for our case). Even if we have more than one cluster at our site, we can easily pick which queue and cluster we want to run our job on by having the queue element specified in the RSL.. <queue>small@pbsserver1</queue> An instance of the WSGRAM service can only have one unique endpoint and if we implement the setup you've described above, we'll need to run one GT4 container for each batch system (cluster) we are managing here at our site. 2) If the the job requirements are not passed though, then you have to
consider each queue to be a different endpoint and hence have a service (end point) per batch system and per queue (policy). The gateway would then route the job also to the correct queue.
Same comment as above. In either case the policy (queue) would be advertised as a share.
However, in the second case I am not sure how the end point is linked to the policy.
Here's how we can probably fix the problem.. - remove the association between the ComputingService and Share - directly link Share to the ComputingElement (the queuing system). The ComputingElement won't be a computing element if it doesn't provide at least one Share (a queue). - multiplicity of the link between the ComputingElement and ComputingService should be "1..*" on the ComputingElement side Attached is a UML diagram of the changes I made to the original diagram. Cheers, Gerson
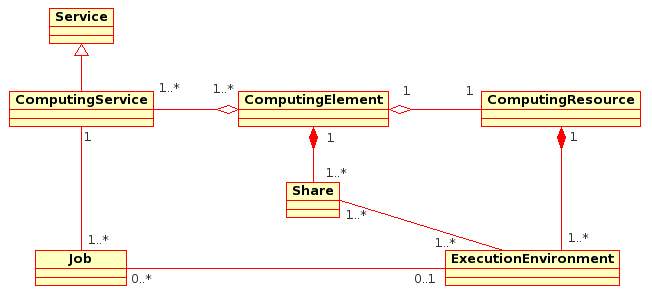{kind=link}
What you have desribed above might not work for us. The GRAM does not have the restriction of only being able to submit (interface) to one batch system (PBS server for our case). Even if we have more than one cluster at our site, we can easily pick which queue and cluster we want to run our job on by having the queue element specified in the RSL..
Doesn't this just depend on how you have written your job managers for GRAM? Laurence
Hi Laurence, On 6/5/07, Laurence Field <Laurence.Field@cern.ch> wrote:
What you have desribed above might not work for us. The GRAM does not have the restriction of only being able to submit (interface) to one batch system (PBS server for our case). Even if we have more than one cluster at our site, we can easily pick which queue and cluster we want to run our job on by having the queue element specified in the
RSL.. Doesn't this just depend on how you have written your job managers for GRAM?
APAC Grid sites did not want to install Globus on the head nodes of their clusters so each site provided a gateway box (a host running Globus) as the interface of their clusters to the grid. A gateway box only has one PBS jobmanager which allows submission of PBS jobs to any of the clusters/pbs servers sitting behind it. I don't think we should stick with the old Globus way of thinking of running the grid middleware on the head/management node of the cluster in implementing the GLUE schema. GLUE should be flexible and allow grid sites like ours (which only have one grid interface for a number of clusters they are managing) to represent our setup in the schema. So to answer your question, yes, it is dependent on how we've written our jobmanagers for the GRAM but that doesn't mean that GLUE should be restricted to only allowing sites Can you guys explain why you think the Share should be directly linked to the ComputingService? Thanks, Gerson
participants (3)
-
 Gerson Galang
Gerson Galang -
 Laurence Field
Laurence Field -
 Sergio Andreozzi
Sergio Andreozzi